 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-preserving data sharing via probabilistic modelling
Paper and Code
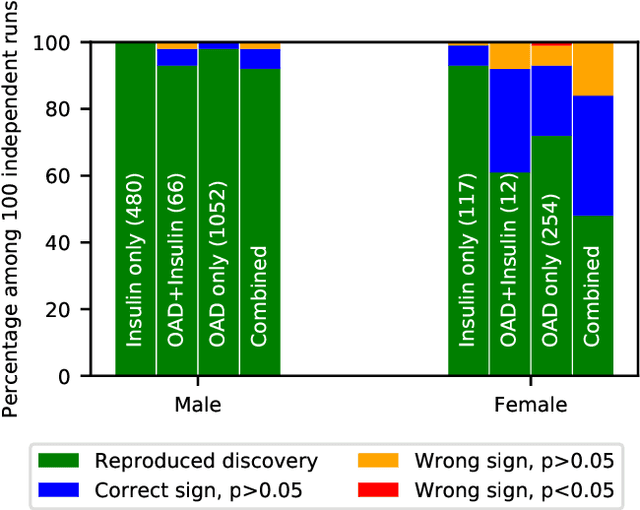
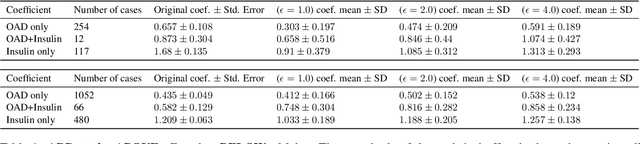
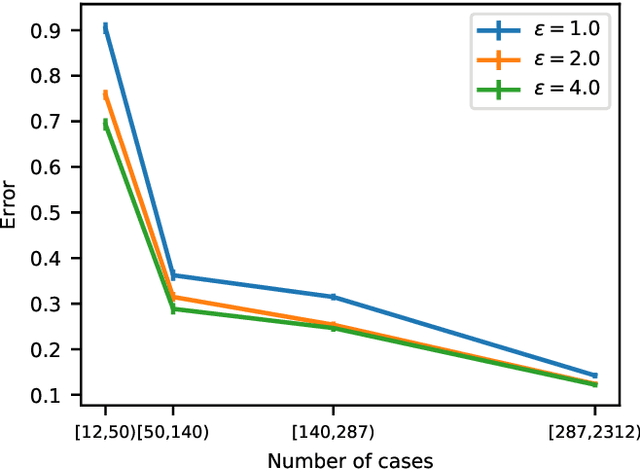

Differential privacy allows quantifying privacy loss from computations on sensitive personal data. This loss grows with the number of accesses to the data, making it hard to open the use of such data while respecting privacy. To avoid this limitation, we propose privacy-preserving release of a synthetic version of a data set, which can be used for an unlimited number of analyses with any methods, without affecting the privacy guarantees. The synthetic data generation is based on differentially private learning of a generative probabilistic model which can capture the probability distribution of the original data. We demonstrate empirically that we can reliably reproduce statistical discoveries from the synthetic data. We expect the method to have broad use in sharing anonymized versions of key data sets for research.