 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefault Machine Learning Hyperparameters Do Not Provide Informative Initialization for Bayesian Optimization
Feb 09, 2026Bayesian Optimization (BO) is a standard tool for hyperparameter tuning thanks to its sample efficiency on expensive black-box functions. While most BO pipelines begin with uniform random initialization, default hyperparameter values shipped with popular ML libraries such as scikit-learn encode implicit expert knowledge and could serve as informative starting points that accelerate convergence. This hypothesis, despite its intuitive appeal, has remained largely unexamined. We formalize the idea by initializing BO with points drawn from truncated Gaussian distributions centered at library defaults and compare the resulting trajectories against a uniform-random baseline. We conduct an extensive empirical evaluation spanning three BO back-ends (BoTorch, Optuna, Scikit-Optimize), three model families (Random Forests, Support Vector Machines, Multilayer Perceptrons), and five benchmark datasets covering classification and regression tasks. Performance is assessed through convergence speed and final predictive quality, and statistical significance is determined via one-sided binomial tests. Across all conditions, default-informed initialization yields no statistically significant advantage over purely random sampling, with p-values ranging from 0.141 to 0.908. A sensitivity analysis on the prior variance confirms that, while tighter concentration around the defaults improves early evaluations, this transient benefit vanishes as optimization progresses, leaving final performance unchanged. Our results provide no evidence that default hyperparameters encode useful directional information for optimization. We therefore recommend that practitioners treat hyperparameter tuning as an integral part of model development and favor principled, data-driven search strategies over heuristic reliance on library defaults.
GOFAI meets Generative AI: Development of Expert Systems by means of Large Language Models
Jul 17, 2025



The development of large language models (LLMs) has successfully transformed knowledge-based systems such as open domain question nswering, which can automatically produce vast amounts of seemingly coherent information. Yet, those models have several disadvantages like hallucinations or confident generation of incorrect or unverifiable facts. In this paper, we introduce a new approach to the development of expert systems using LLMs in a controlled and transparent way. By limiting the domain and employing a well-structured prompt-based extraction approach, we produce a symbolic representation of knowledge in Prolog, which can be validated and corrected by human experts. This approach also guarantees interpretability, scalability and reliability of the developed expert systems. Via quantitative and qualitative experiments with Claude Sonnet 3.7 and GPT-4.1, we show strong adherence to facts and semantic coherence on our generated knowledge bases. We present a transparent hybrid solution that combines the recall capacity of LLMs with the precision of symbolic systems, thereby laying the foundation for dependable AI applications in sensitive domains.
Alpha Entropy Search for New Information-based Bayesian Optimization
Nov 25, 2024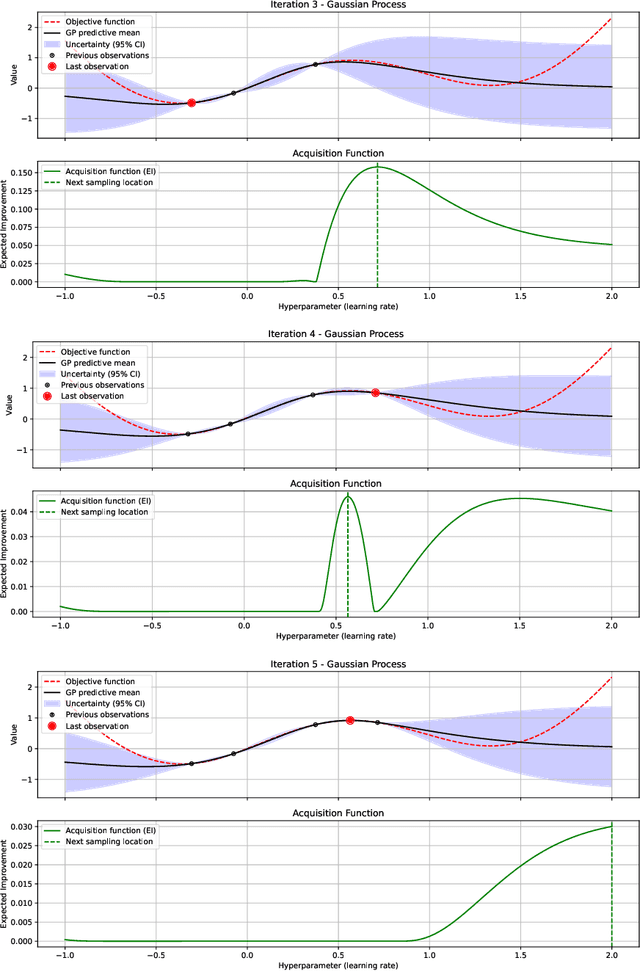

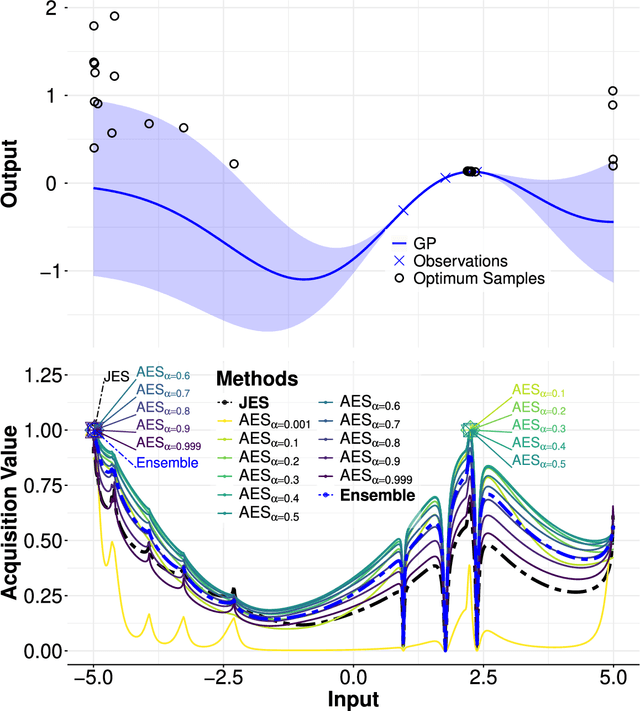
Bayesian optimization (BO) methods based on information theory have obtained state-of-the-art results in several tasks. These techniques heavily rely on the Kullback-Leibler (KL) divergence to compute the acquisition function. In this work, we introduce a novel information-based class of acquisition functions for BO called Alpha Entropy Search (AES). AES is based on the {\alpha}-divergence, that generalizes the KL divergence. Iteratively, AES selects the next evaluation point as the one whose associated target value has the highest level of the dependency with respect to the location and associated value of the global maximum of the optimization problem. Dependency is measured in terms of the {\alpha}-divergence, as an alternative to the KL divergence. Intuitively, this favors the evaluation of the objective function at the most informative points about the global maximum. The {\alpha}-divergence has a free parameter {\alpha}, which determines the behavior of the divergence, trading-off evaluating differences between distributions at a single mode, and evaluating differences globally. Therefore, different values of {\alpha} result in different acquisition functions. AES acquisition lacks a closed-form expression. However, we propose an efficient and accurate approximation using a truncated Gaussian distribution. In practice, the value of {\alpha} can be chosen by the practitioner, but here we suggest to use a combination of acquisition functions obtained by simultaneously considering a range of values of {\alpha}. We provide an implementation of AES in BOTorch and we evaluate its performance in both synthetic, benchmark and real-world experiments involving the tuning of the hyper-parameters of a deep neural network. These experiments show that the performance of AES is competitive with respect to other information-based acquisition functions such as JES, MES or PES.
Deep Reinforcement Learning Agents for Strategic Production Policies in Microeconomic Market Simulations
Oct 27, 2024



Traditional economic models often rely on fixed assumptions about market dynamics, limiting their ability to capture the complexities and stochastic nature of real-world scenarios. However, reality is more complex and includes noise, making traditional models assumptions not met in the market. In this paper, we explore the application of deep reinforcement learning (DRL) to obtain optimal production strategies in microeconomic market environments to overcome the limitations of traditional models. Concretely, we propose a DRL-based approach to obtain an effective policy in competitive markets with multiple producers, each optimizing their production decisions in response to fluctuating demand, supply, prices, subsidies, fixed costs, total production curve, elasticities and other effects contaminated by noise. Our framework enables agents to learn adaptive production policies to several simulations that consistently outperform static and random strategies. As the deep neural networks used by the agents are universal approximators of functions, DRL algorithms can represent in the network complex patterns of data learnt by trial and error that explain the market. Through extensive simulations, we demonstrate how DRL can capture the intricate interplay between production costs, market prices, and competitor behavior, providing insights into optimal decision-making in dynamic economic settings. The results show that agents trained with DRL can strategically adjust production levels to maximize long-term profitability, even in the face of volatile market conditions. We believe that the study bridges the gap between theoretical economic modeling and practical market simulation, illustrating the potential of DRL to revolutionize decision-making in market strategies.
Real Customization or Just Marketing: Are Customized Versions of Chat GPT Useful?
Nov 27, 2023

Large Language Models (LLMs), as the case of OpenAI ChatGPT-4 Turbo, are revolutionizing several industries, including higher education. In this context, LLMs can be personalized through a fine-tuning process to meet the student demands on every particular subject, like statistics. Recently, OpenAI has launched the possibility to fine-tune their model with a natural language web interface, enabling the possibility to create customized GPT version deliberately conditioned to meet the demands of a specific task. The objective of this research is to assess the potential of the customized GPTs that have recently been launched by OpenAI. After developing a Business Statistics Virtual Professor (BSVP), tailored for students at the Universidad Pontificia Comillas, its behavior was evaluated and compared with that of ChatGPT-4 Turbo. The results lead to several conclusions. Firstly, a substantial modification in the style of communication was observed. Following the instructions it was trained with, BSVP provided responses in a more relatable and friendly tone, even incorporating a few minor jokes. Secondly, and this is a matter of relevance, when explicitly asked for something like, "I would like to practice a programming exercise similar to those in R practice 4," BSVP was capable of providing a far superior response: having access to contextual documentation, it could fulfill the request, something beyond ChatGPT-4 Turbo's capabilities. On the downside, the response times were generally higher. Lastly, regarding overall performance, quality, depth, and alignment with the specific content of the course, no statistically significant differences were observed in the responses between BSVP and ChatGPT-4 Turbo. It appears that customized assistants trained with prompts present advantages as virtual aids for students, yet they do not constitute a substantial improvement over ChatGPT-4 Turbo.
A survey of Generative AI Applications
Jun 14, 2023Generative AI has experienced remarkable growth in recent years, leading to a wide array of applications across diverse domains. In this paper, we present a comprehensive survey of more than 350 generative AI applications, providing a structured taxonomy and concise descriptions of various unimodal and even multimodal generative AIs. The survey is organized into sections, covering a wide range of unimodal generative AI applications such as text, images, video, gaming and brain information. Our survey aims to serve as a valuable resource for researchers and practitioners to navigate the rapidly expanding landscape of generative AI, facilitating a better understanding of the current state-of-the-art and fostering further innovation in the field.
Simulating H.P. Lovecraft horror literature with the ChatGPT large language model
May 05, 2023

In this paper, we present a novel approach to simulating H.P. Lovecraft's horror literature using the ChatGPT large language model, specifically the GPT-4 architecture. Our study aims to generate text that emulates Lovecraft's unique writing style and themes, while also examining the effectiveness of prompt engineering techniques in guiding the model's output. To achieve this, we curated a prompt containing several specialized literature references and employed advanced prompt engineering methods. We conducted an empirical evaluation of the generated text by administering a survey to a sample of undergraduate students. Utilizing statistical hypothesis testing, we assessed the students ability to distinguish between genuine Lovecraft works and those generated by our model. Our findings demonstrate that the participants were unable to reliably differentiate between the two, indicating the effectiveness of the GPT-4 model and our prompt engineering techniques in emulating Lovecraft's literary style. In addition to presenting the GPT model's capabilities, this paper provides a comprehensive description of its underlying architecture and offers a comparative analysis with related work that simulates other notable authors and philosophers, such as Dennett. By exploring the potential of large language models in the context of literary emulation, our study contributes to the body of research on the applications and limitations of these models in various creative domains.
ChatGPT: More than a Weapon of Mass Deception, Ethical challenges and responses from the Human-Centered Artificial Intelligence perspective
Apr 06, 2023This article explores the ethical problems arising from the use of ChatGPT as a kind of generative AI and suggests responses based on the Human-Centered Artificial Intelligence (HCAI) framework. The HCAI framework is appropriate because it understands technology above all as a tool to empower, augment, and enhance human agency while referring to human wellbeing as a grand challenge, thus perfectly aligning itself with ethics, the science of human flourishing. Further, HCAI provides objectives, principles, procedures, and structures for reliable, safe, and trustworthy AI which we apply to our ChatGPT assessments. The main danger ChatGPT presents is the propensity to be used as a weapon of mass deception (WMD) and an enabler of criminal activities involving deceit. We review technical specifications to better comprehend its potentials and limitations. We then suggest both technical (watermarking, styleme, detectors, and fact-checkers) and non-technical measures (terms of use, transparency, educator considerations, HITL) to mitigate ChatGPT misuse or abuse and recommend best uses (creative writing, non-creative writing, teaching and learning). We conclude with considerations regarding the role of humans in ensuring the proper use of ChatGPT for individual and social wellbeing.
Fine-tuning ClimateBert transformer with ClimaText for the disclosure analysis of climate-related financial risks
Mar 21, 2023
In recent years there has been a growing demand from financial agents, especially from particular and institutional investors, for companies to report on climate-related financial risks. A vast amount of information, in text format, can be expected to be disclosed in the short term by firms in order to identify these types of risks in their financial and non financial reports, particularly in response to the growing regulation that is being passed on the matter. To this end, this paper applies state-of-the-art NLP techniques to achieve the detection of climate change in text corpora. We use transfer learning to fine-tune two transformer models, BERT and ClimateBert -a recently published DistillRoBERTa-based model that has been specifically tailored for climate text classification-. These two algorithms are based on the transformer architecture which enables learning the contextual relationships between words in a text. We carry out the fine-tuning process of both models on the novel Clima-Text database, consisting of data collected from Wikipedia, 10K Files Reports and web-based claims. Our text classification model obtained from the ClimateBert fine-tuning process on ClimaText, outperforms the models created with BERT and the current state-of-the-art transformer in this particular problem. Our study is the first one to implement on the ClimaText database the recently published ClimateBert algorithm. Based on our results, it can be said that ClimateBert fine-tuned on ClimaText is an outstanding tool within the NLP pre-trained transformer models that may and should be used by investors, institutional agents and companies themselves to monitor the disclosure of climate risk in financial reports. In addition, our transfer learning methodology is cheap in computational terms, thus allowing any organization to perform it.
Bayesian Optimization of ESG Financial Investments
Feb 10, 2023



Financial experts and analysts seek to predict the variability of financial markets. In particular, the correct prediction of this variability ensures investors successful investments. However, there has been a big trend in finance in the last years, which are the ESG criteria. Concretely, ESG (Economic, Social and Governance) criteria have become more significant in finance due to the growing importance of investments being socially responsible, and because of the financial impact companies suffer when not complying with them. Consequently, creating a stock portfolio should not only take into account its performance but compliance with ESG criteria. Hence, this paper combines mathematical modelling, with ESG and finance. In more detail, we use Bayesian optimization (BO), a sequential state-of-the-art design strategy to optimize black-boxes with unknown analytical and costly-to compute expressions, to maximize the performance of a stock portfolio under the presence of ESG criteria soft constraints incorporated to the objective function. In an illustrative experiment, we use the Sharpe ratio, that takes into consideration the portfolio returns and its variance, in other words, it balances the trade-off between maximizing returns and minimizing risks. In the present work, ESG criteria have been divided into fourteen independent categories used in a linear combination to estimate a firm total ESG score. Most importantly, our presented approach would scale to alternative black-box methods of estimating the performance and ESG compliance of the stock portfolio. In particular, this research has opened the door to many new research lines, as it has proved that a portfolio can be optimized using a BO that takes into consideration financial performance and the accomplishment of ESG criteria.