 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Image Feature Analysis and its Specialization for Fréchet Distance and Neighborhoods
Jun 26, 2024


Assessing distances between images and image datasets is a fundamental task in vision-based research. It is a challenging open problem in the literature and despite the criticism it receives, the most ubiquitous method remains the Fr\'echet Inception Distance. The Inception network is trained on a specific labeled dataset, ImageNet, which has caused the core of its criticism in the most recent research. Improvements were shown by moving to self-supervision learning over ImageNet, leaving the training data domain as an open question. We make that last leap and provide the first analysis on domain-specific feature training and its effects on feature distance, on the widely-researched facial image domain. We provide our findings and insights on this domain specialization for Fr\'echet distance and image neighborhoods, supported by extensive experiments and in-depth user studies.
VerA: Versatile Anonymization Fit for Clinical Facial Images
Dec 04, 2023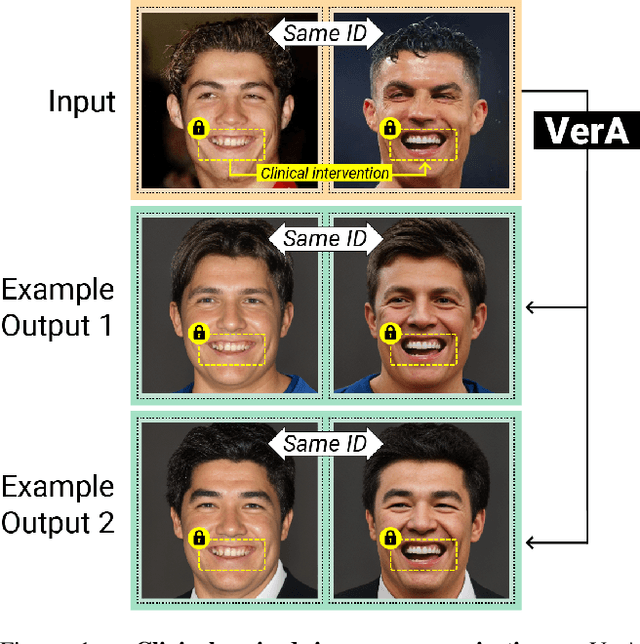



The escalating legislative demand for data privacy in facial image dissemination has underscored the significance of image anonymization. Recent advancements in the field surpass traditional pixelation or blur methods, yet they predominantly address regular single images. This leaves clinical image anonymization -- a necessity for illustrating medical interventions -- largely unaddressed. We present VerA, a versatile facial image anonymization that is fit for clinical facial images where: (1) certain semantic areas must be preserved to show medical intervention results, and (2) anonymizing image pairs is crucial for showing before-and-after results. VerA outperforms or is on par with state-of-the-art methods in de-identification and photorealism for regular images. In addition, we validate our results on paired anonymization, and on the anonymization of both single and paired clinical images with extensive quantitative and qualitative evaluation.
Visual-Only Recognition of Normal, Whispered and Silent Speech
Feb 18, 2018
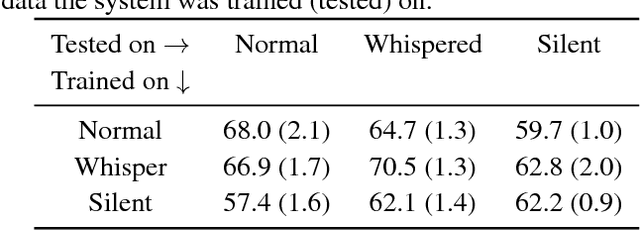

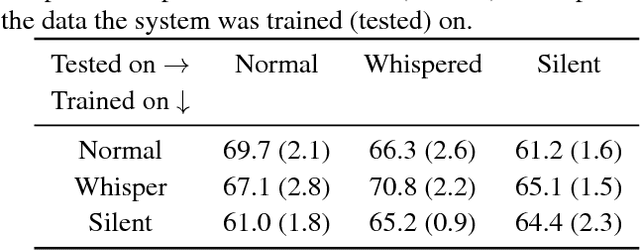
Silent speech interfaces have been recently proposed as a way to enable communication when the acoustic signal is not available. This introduces the need to build visual speech recognition systems for silent and whispered speech. However, almost all the recently proposed systems have been trained on vocalised data only. This is in contrast with evidence in the literature which suggests that lip movements change depending on the speech mode. In this work, we introduce a new audiovisual database which is publicly available and contains normal, whispered and silent speech. To the best of our knowledge, this is the first study which investigates the differences between the three speech modes using the visual modality only. We show that an absolute decrease in classification rate of up to 3.7% is observed when training and testing on normal and whispered, respectively, and vice versa. An even higher decrease of up to 8.5% is reported when the models are tested on silent speech. This reveals that there are indeed visual differences between the 3 speech modes and the common assumption that vocalized training data can be used directly to train a silent speech recognition system may not be true.