 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Only Recognition of Normal, Whispered and Silent Speech
Paper and Code
Feb 18, 2018
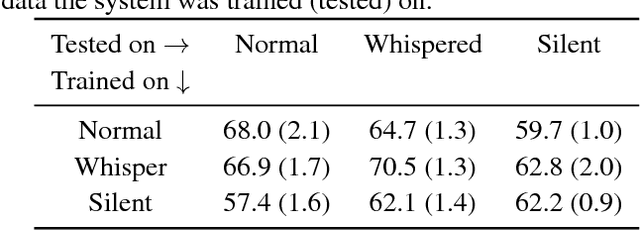

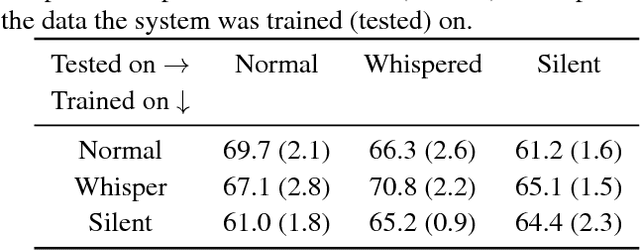
Silent speech interfaces have been recently proposed as a way to enable communication when the acoustic signal is not available. This introduces the need to build visual speech recognition systems for silent and whispered speech. However, almost all the recently proposed systems have been trained on vocalised data only. This is in contrast with evidence in the literature which suggests that lip movements change depending on the speech mode. In this work, we introduce a new audiovisual database which is publicly available and contains normal, whispered and silent speech. To the best of our knowledge, this is the first study which investigates the differences between the three speech modes using the visual modality only. We show that an absolute decrease in classification rate of up to 3.7% is observed when training and testing on normal and whispered, respectively, and vice versa. An even higher decrease of up to 8.5% is reported when the models are tested on silent speech. This reveals that there are indeed visual differences between the 3 speech modes and the common assumption that vocalized training data can be used directly to train a silent speech recognition system may not be true.