 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tree Databases in Automated Planning
Nov 16, 2025A central challenge in scaling up explicit state-space search for large tasks is compactly representing the set of generated states. Tree databases, a data structure from model checking, require constant space per generated state in the best case, but they need a large preallocation of memory. We propose a novel dynamic variant of tree databases for compressing state sets over propositional and numeric variables and prove that it maintains the desirable properties of the static counterpart. Our empirical evaluation of state compression techniques for grounded and lifted planning on classical and numeric planning tasks reveals compression ratios of several orders of magnitude, often with negligible runtime overhead.
Symmetries and Expressive Requirements for Learning General Policies
Sep 24, 2024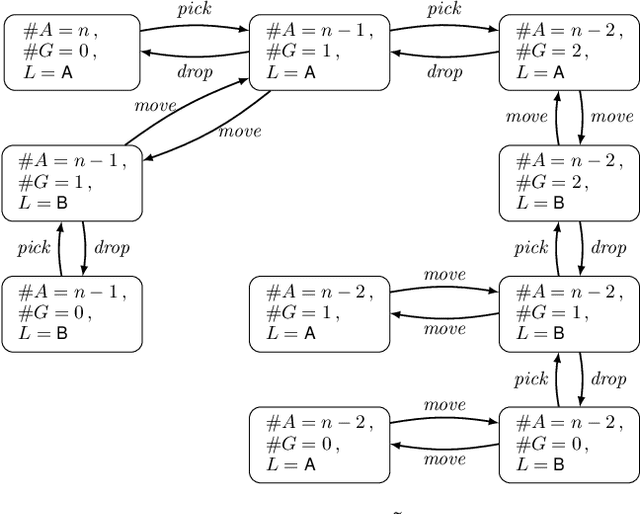
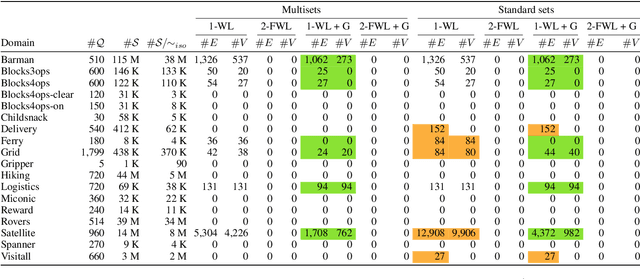
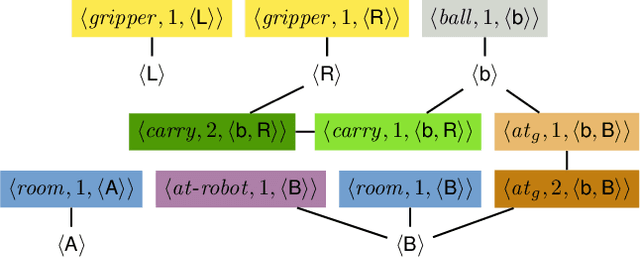
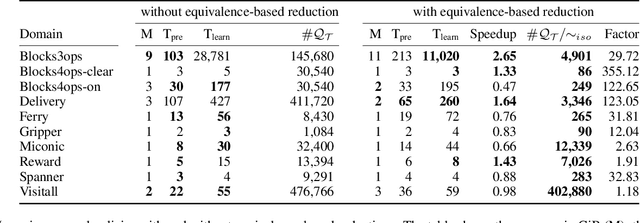
State symmetries play an important role in planning and generalized planning. In the first case, state symmetries can be used to reduce the size of the search; in the second, to reduce the size of the training set. In the case of general planning, however, it is also critical to distinguish non-symmetric states, i.e., states that represent non-isomorphic relational structures. However, while the language of first-order logic distinguishes non-symmetric states, the languages and architectures used to represent and learn general policies do not. In particular, recent approaches for learning general policies use state features derived from description logics or learned via graph neural networks (GNNs) that are known to be limited by the expressive power of C_2, first-order logic with two variables and counting. In this work, we address the problem of detecting symmetries in planning and generalized planning and use the results to assess the expressive requirements for learning general policies over various planning domains. For this, we map planning states to plain graphs, run off-the-shelf algorithms to determine whether two states are isomorphic with respect to the goal, and run coloring algorithms to determine if C_2 features computed logically or via GNNs distinguish non-isomorphic states. Symmetry detection results in more effective learning, while the failure to detect non-symmetries prevents general policies from being learned at all in certain domains.
On Policy Reuse: An Expressive Language for Representing and Executing General Policies that Call Other Policies
Mar 25, 2024Recently, a simple but powerful language for expressing and learning general policies and problem decompositions (sketches) has been introduced in terms of rules defined over a set of Boolean and numerical features. In this work, we consider three extensions of this language aimed at making policies and sketches more flexible and reusable: internal memory states, as in finite state controllers; indexical features, whose values are a function of the state and a number of internal registers that can be loaded with objects; and modules that wrap up policies and sketches and allow them to call each other by passing parameters. In addition, unlike general policies that select state transitions rather than ground actions, the new language allows for the selection of such actions. The expressive power of the resulting language for policies and sketches is illustrated through a number of examples.
Learning Sketches for Decomposing Planning Problems into Subproblems of Bounded Width: Extended Version
Mar 28, 2022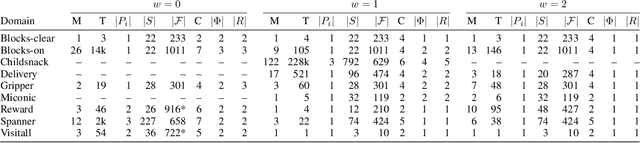
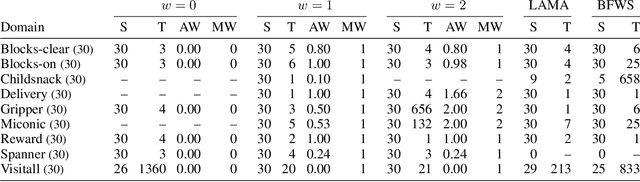
Recently, sketches have been introduced as a general language for representing the subgoal structure of instances drawn from the same domain. Sketches are collections of rules of the form C -> E over a given set of features where C expresses Boolean conditions and E expresses qualitative changes. Each sketch rule defines a subproblem: going from a state that satisfies C to a state that achieves the change expressed by E or a goal state. Sketches can encode simple goal serializations, general policies, or decompositions of bounded width that can be solved greedily, in polynomial time, by the SIW_R variant of the SIW algorithm. Previous work has shown the computational value of sketches over benchmark domains that, while tractable, are challenging for domain-independent planners. In this work, we address the problem of learning sketches automatically given a planning domain, some instances of the target class of problems, and the desired bound on the sketch width. We present a logical formulation of the problem, an implementation using the ASP solver Clingo, and experimental results. The sketch learner and the SIW_R planner yield a domain-independent planner that learns and exploits domain structure in a crisp and explicit form.
Expressing and Exploiting the Common Subgoal Structure of Classical Planning Domains Using Sketches: Extended Version
May 10, 2021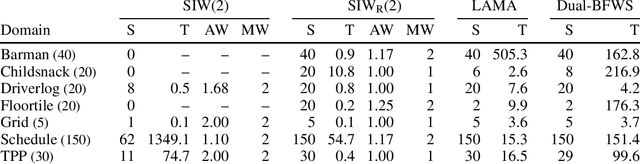
Width-based planning methods exploit the use of conjunctive goals for decomposing problems into subproblems of low width. However, algorithms like SIW fail when the goal is not serializable. In this work, we address this limitation of SIW by using a simple but powerful language for expressing problem decompositions introduced recently by Bonet and Geffner, called policy sketches. A policy sketch R consists of a set of Boolean and numerical features and a set of sketch rules that express how the values of these features are supposed to change. Like general policies, policy sketches are domain general, but unlike policies, the changes captured by sketch rules do not need to be achieved in a single step. We show that many planning domains that cannot be solved by SIW are provably solvable in low polynomial time with the SIW_R algorithm, the version of SIW that employs user-provided policy sketches. Policy sketches are thus shown to be a powerful language for expressing domain-specific knowledge in a simple and compact way and a convenient alternative to languages such as HTNs or temporal logics. Furthermore, policy sketches make it easy to express general problem decompositions and prove key properties like their complexity and width.