 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge*-CFQ: Analyzing the Scalability of Machine Learning on a Compositional Task
Dec 15, 2020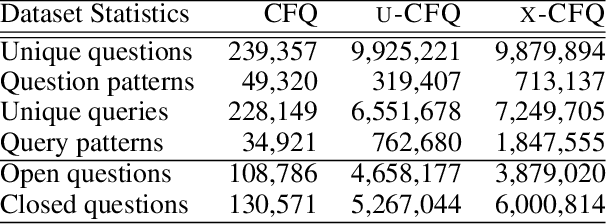
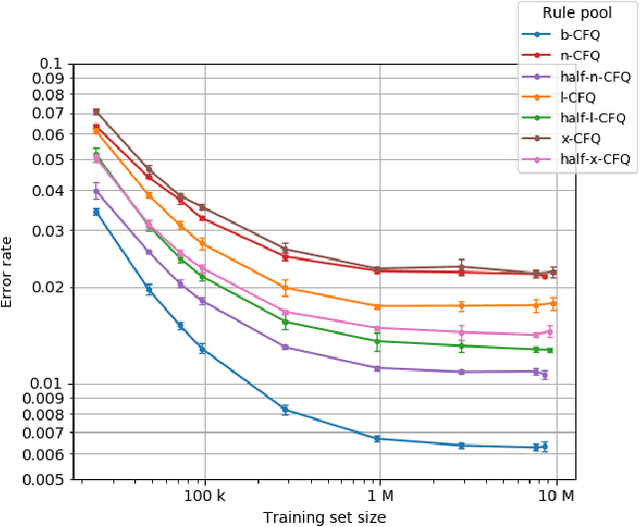

We present *-CFQ ("star-CFQ"): a suite of large-scale datasets of varying scope based on the CFQ semantic parsing benchmark, designed for principled investigation of the scalability of machine learning systems in a realistic compositional task setting. Using this suite, we conduct a series of experiments investigating the ability of Transformers to benefit from increased training size under conditions of fixed computational cost. We show that compositional generalization remains a challenge at all training sizes, and we show that increasing the scope of natural language leads to consistently higher error rates, which are only partially offset by increased training data. We further show that while additional training data from a related domain improves the accuracy in data-starved situations, this improvement is limited and diminishes as the distance from the related domain to the target domain increases.
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Dec 20, 2019

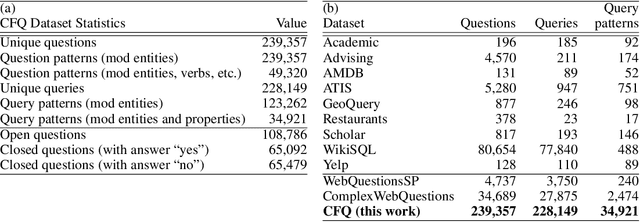
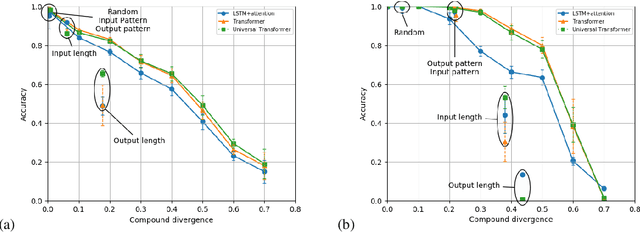
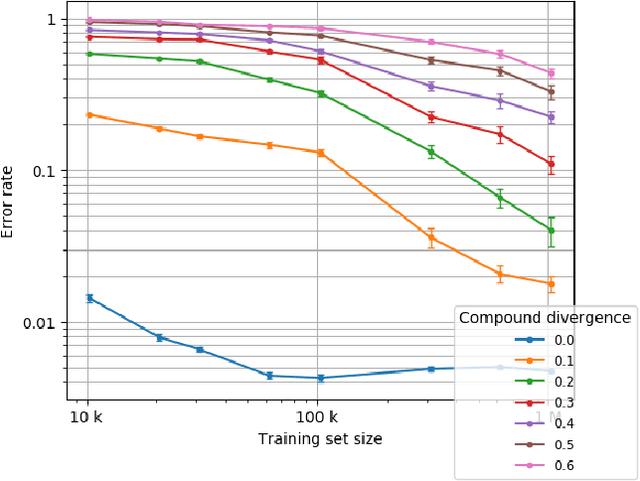
State-of-the-art machine learning methods exhibit limited compositional generalization. At the same time, there is a lack of realistic benchmarks that comprehensively measure this ability, which makes it challenging to find and evaluate improvements. We introduce a novel method to systematically construct such benchmarks by maximizing compound divergence while guaranteeing a small atom divergence between train and test sets, and we quantitatively compare this method to other approaches for creating compositional generalization benchmarks. We present a large and realistic natural language question answering dataset that is constructed according to this method, and we use it to analyze the compositional generalization ability of three machine learning architectures. We find that they fail to generalize compositionally and that there is a surprisingly strong negative correlation between compound divergence and accuracy. We also demonstrate how our method can be used to create new compositionality benchmarks on top of the existing SCAN dataset, which confirms these findings.
Syntactic vs. Semantic Locality: How Good Is a Cheap Approximation?
Jul 06, 2012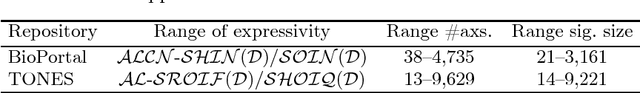
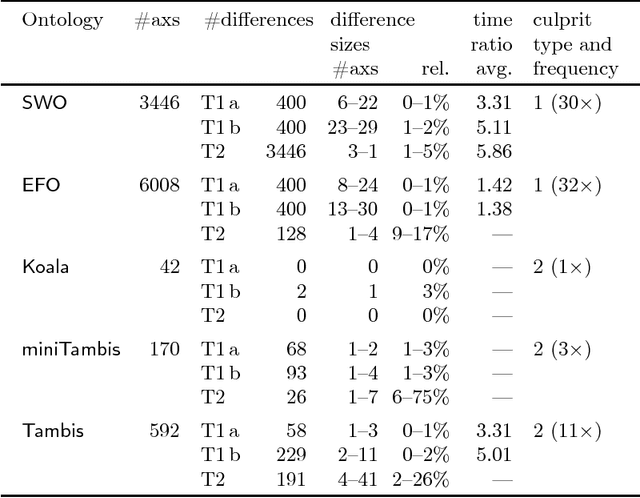
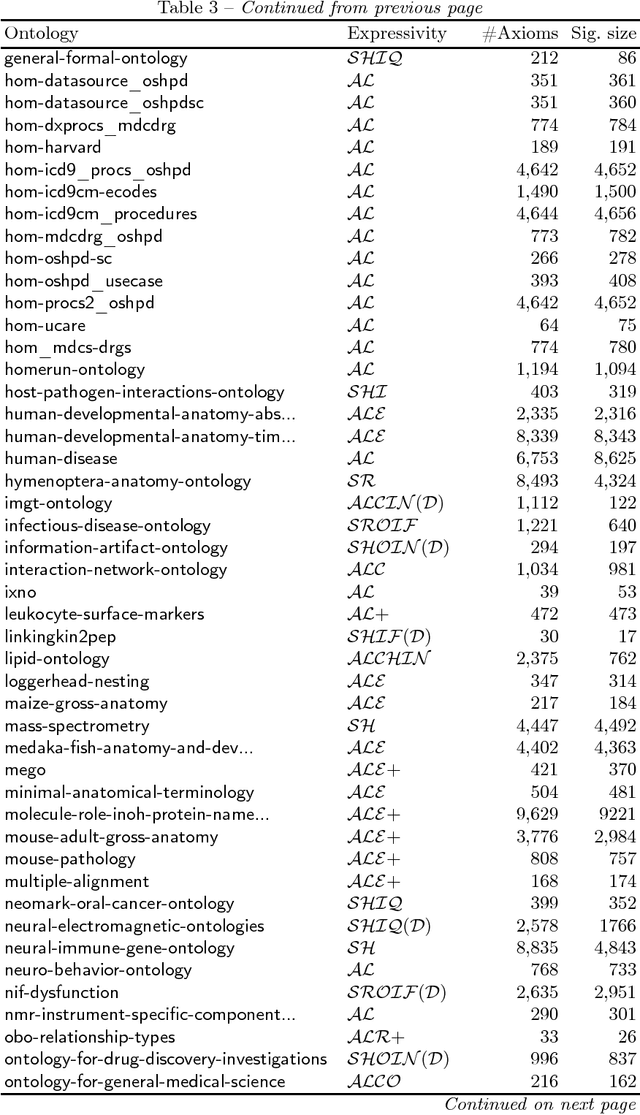
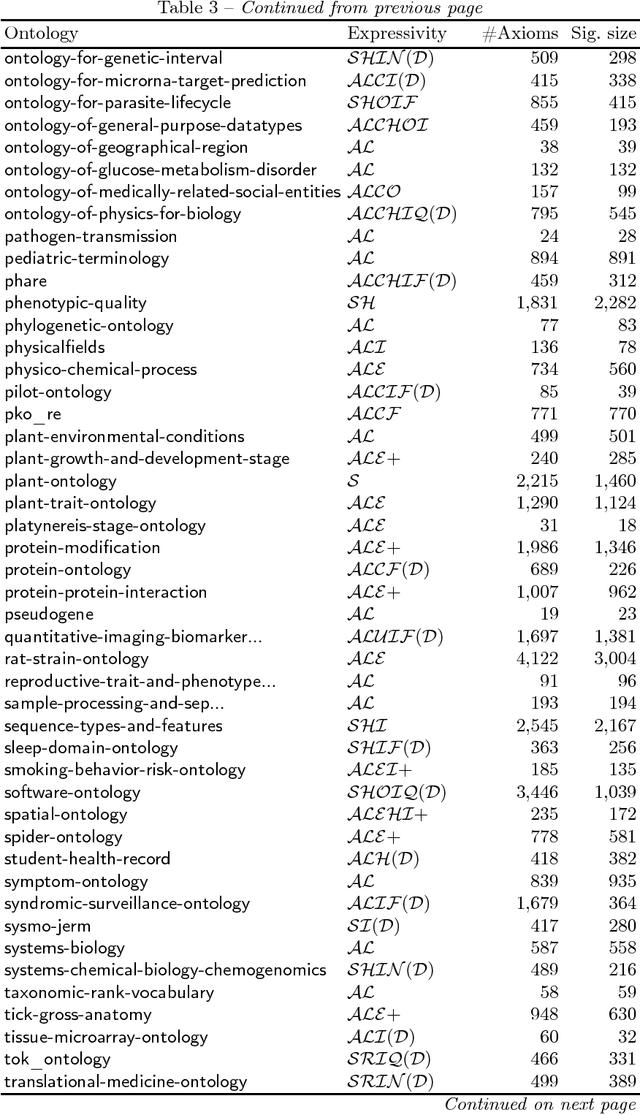
Extracting a subset of a given OWL ontology that captures all the ontology's knowledge about a specified set of terms is a well-understood task. This task can be based, for instance, on locality-based modules (LBMs). These come in two flavours, syntactic and semantic, and a syntactic LBM is known to contain the corresponding semantic LBM. For syntactic LBMs, polynomial extraction algorithms are known, implemented in the OWL API, and being used. In contrast, extracting semantic LBMs involves reasoning, which is intractable for OWL 2 DL, and these algorithms had not been implemented yet for expressive ontology languages. We present the first implementation of semantic LBMs and report on experiments that compare them with syntactic LBMs extracted from real-life ontologies. Our study reveals whether semantic LBMs are worth the additional extraction effort, compared with syntactic LBMs.