 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge*-CFQ: Analyzing the Scalability of Machine Learning on a Compositional Task
Paper and Code
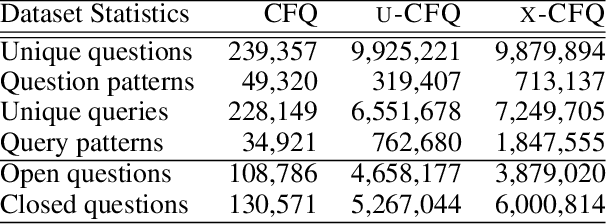
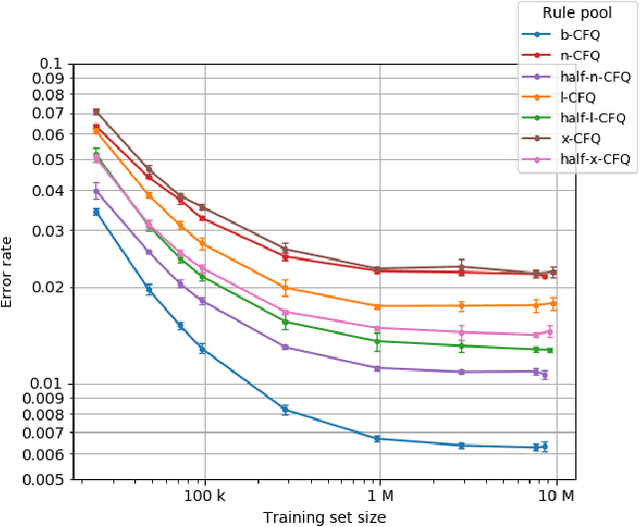

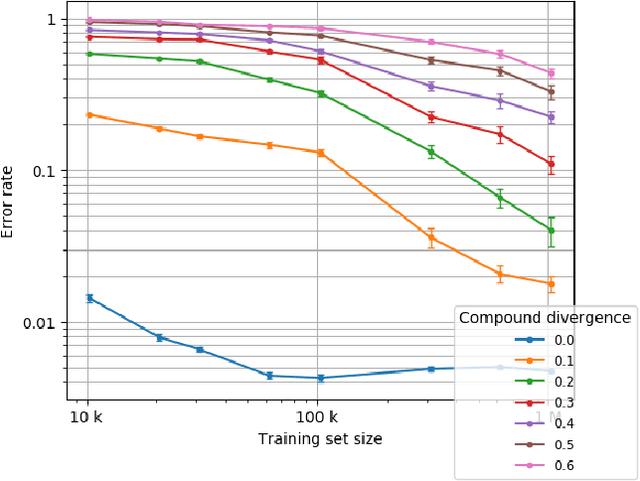
We present *-CFQ ("star-CFQ"): a suite of large-scale datasets of varying scope based on the CFQ semantic parsing benchmark, designed for principled investigation of the scalability of machine learning systems in a realistic compositional task setting. Using this suite, we conduct a series of experiments investigating the ability of Transformers to benefit from increased training size under conditions of fixed computational cost. We show that compositional generalization remains a challenge at all training sizes, and we show that increasing the scope of natural language leads to consistently higher error rates, which are only partially offset by increased training data. We further show that while additional training data from a related domain improves the accuracy in data-starved situations, this improvement is limited and diminishes as the distance from the related domain to the target domain increases.