 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Learning Sound Events Classifiers using Gram Matrix Feature-wise Correlations
Feb 23, 2021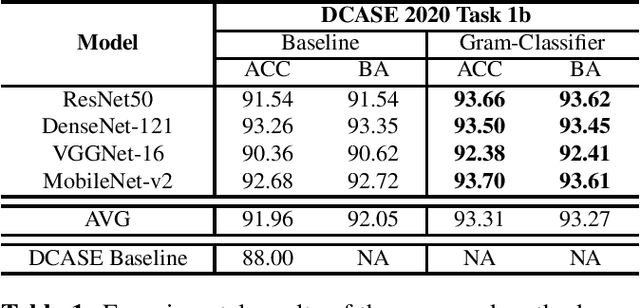
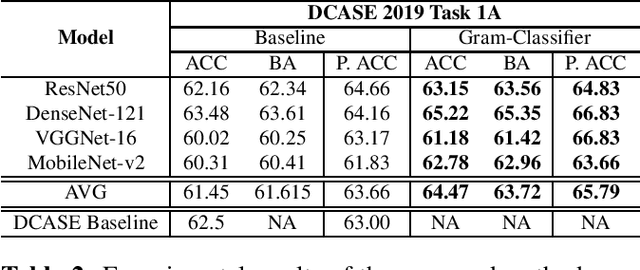
In this paper, we propose a new Sound Event Classification (SEC) method which is inspired in recent works for out-of-distribution detection. In our method, we analyse all the activations of a generic CNN in order to produce feature representations using Gram Matrices. The similarity metrics are evaluated considering all possible classes, and the final prediction is defined as the class that minimizes the deviation with respect to the features seeing during training. The proposed approach can be applied to any CNN and our experimental evaluation of four different architectures on two datasets demonstrated that our method consistently improves the baseline models.
Multi-task Deep Learning for Real-Time 3D Human Pose Estimation and Action Recognition
Dec 15, 2019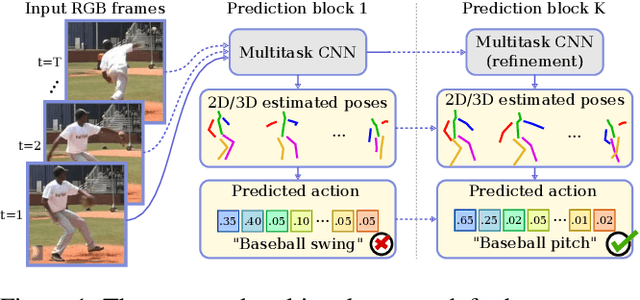
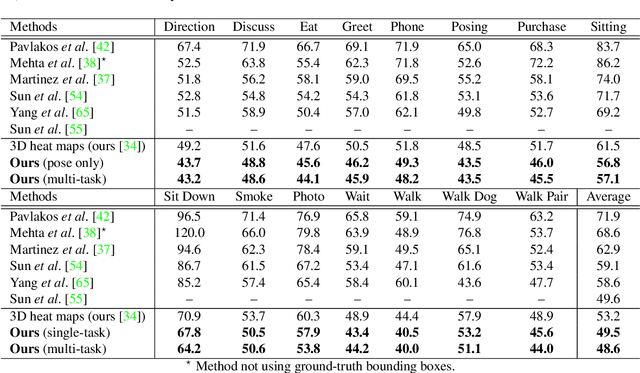
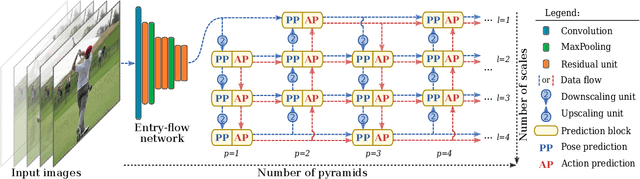
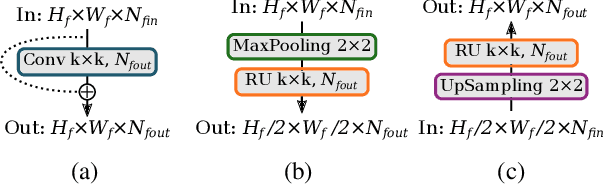
Human pose estimation and action recognition are related tasks since both problems are strongly dependent on the human body representation and analysis. Nonetheless, most recent methods in the literature handle the two problems separately. In this work, we propose a multi-task framework for jointly estimating 2D or 3D human poses from monocular color images and classifying human actions from video sequences. We show that a single architecture can be used to solve both problems in an efficient way and still achieves state-of-the-art or comparable results at each task while running at more than 100 frames per second. The proposed method benefits from high parameters sharing between the two tasks by unifying still images and video clips processing in a single pipeline, allowing the model to be trained with data from different categories simultaneously and in a seamlessly way. Additionally, we provide important insights for end-to-end training the proposed multi-task model by decoupling key prediction parts, which consistently leads to better accuracy on both tasks. The reported results on four datasets (MPII, Human3.6M, Penn Action and NTU RGB+D) demonstrate the effectiveness of our method on the targeted tasks. Our source code and trained weights are publicly available at https://github.com/dluvizon/deephar.
Consensus-based Optimization for 3D Human Pose Estimation in Camera Coordinates
Nov 28, 2019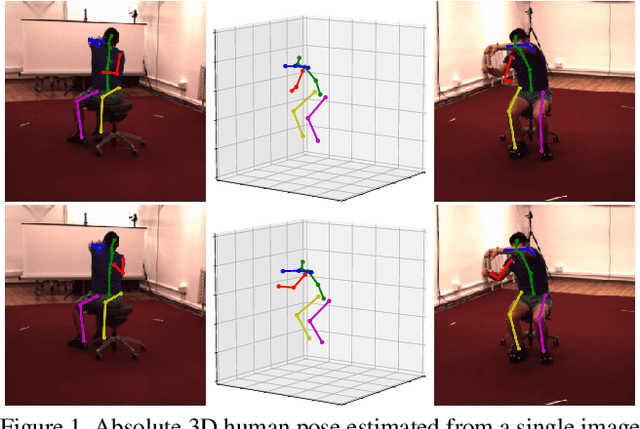
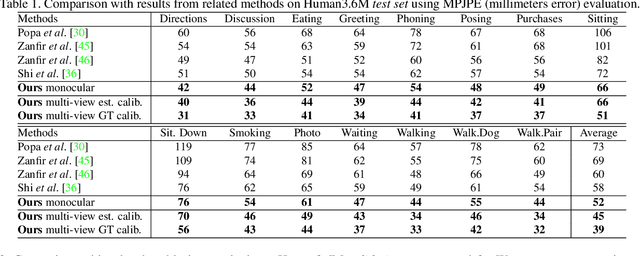
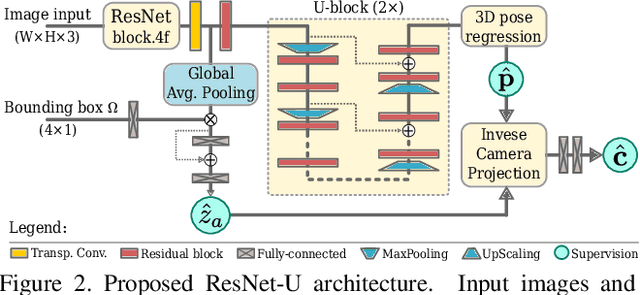
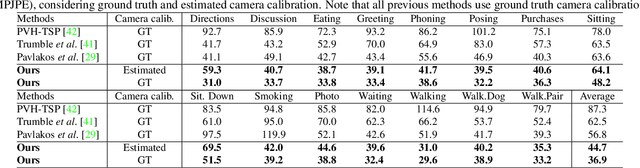
3D human pose estimation is frequently seen as the task of estimating 3D poses relative to the root body joint. Alternatively, in this paper, we propose a 3D human pose estimation method in camera coordinates, which allows effective combination of 2D annotated data and 3D poses, as well as a straightforward multi-view generalization. To that end, we cast the problem into a different perspective, where 3D poses are predicted in the image plane, in pixels, and the absolute depth is estimated in millimeters. Based on this, we propose a consensus-based optimization algorithm for multi-view predictions from uncalibrated images, which requires a single monocular training procedure. Our method improves the state-of-the-art on well known 3D human pose datasets, reducing the prediction error by 32% in the most common benchmark. In addition, we also reported our results in absolute pose position error, achieving 80mm for monocular estimations and 51mm for multi-view, on average.