 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-based Optimization for 3D Human Pose Estimation in Camera Coordinates
Paper and Code
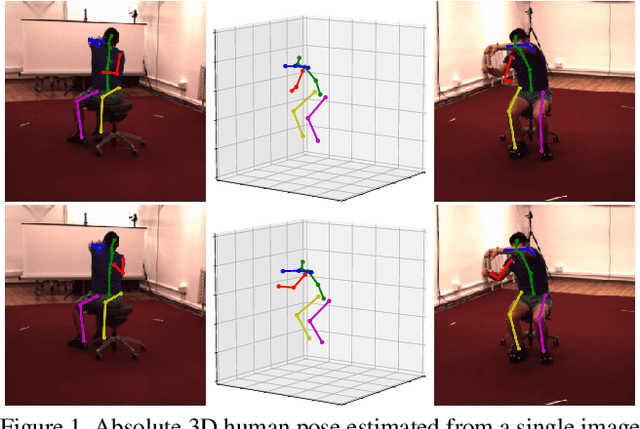
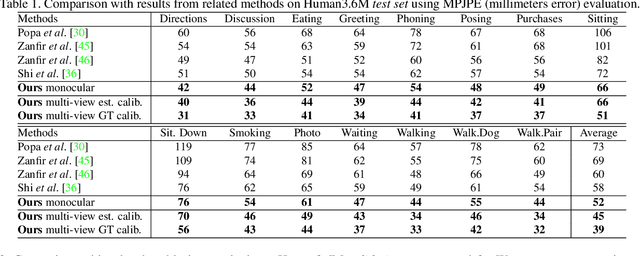
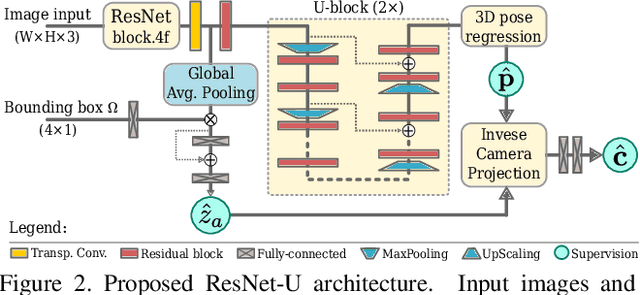
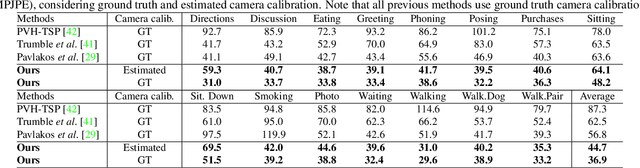
3D human pose estimation is frequently seen as the task of estimating 3D poses relative to the root body joint. Alternatively, in this paper, we propose a 3D human pose estimation method in camera coordinates, which allows effective combination of 2D annotated data and 3D poses, as well as a straightforward multi-view generalization. To that end, we cast the problem into a different perspective, where 3D poses are predicted in the image plane, in pixels, and the absolute depth is estimated in millimeters. Based on this, we propose a consensus-based optimization algorithm for multi-view predictions from uncalibrated images, which requires a single monocular training procedure. Our method improves the state-of-the-art on well known 3D human pose datasets, reducing the prediction error by 32% in the most common benchmark. In addition, we also reported our results in absolute pose position error, achieving 80mm for monocular estimations and 51mm for multi-view, on average.