 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Deep Learning for Real-Time 3D Human Pose Estimation and Action Recognition
Paper and Code
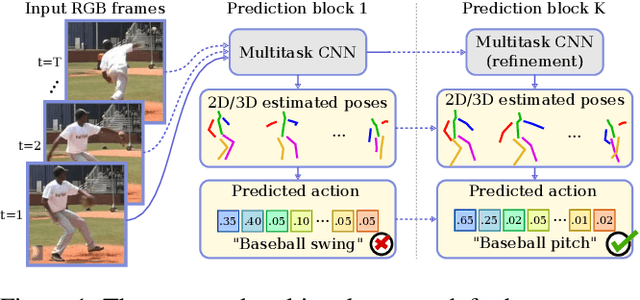
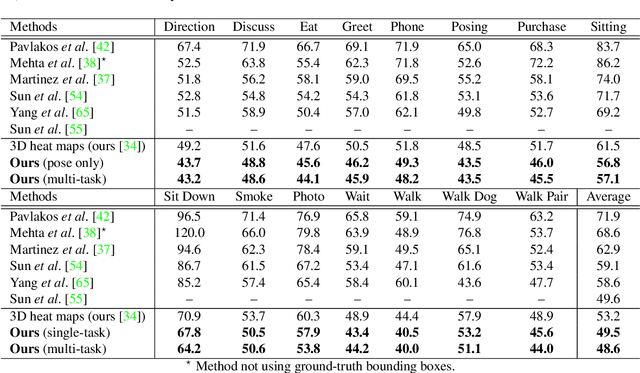
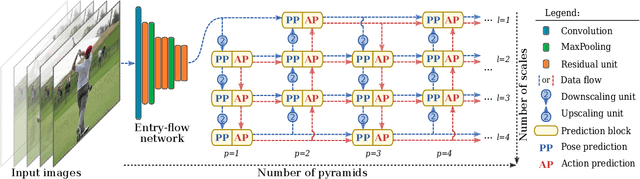
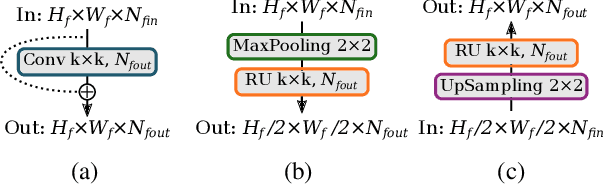
Human pose estimation and action recognition are related tasks since both problems are strongly dependent on the human body representation and analysis. Nonetheless, most recent methods in the literature handle the two problems separately. In this work, we propose a multi-task framework for jointly estimating 2D or 3D human poses from monocular color images and classifying human actions from video sequences. We show that a single architecture can be used to solve both problems in an efficient way and still achieves state-of-the-art or comparable results at each task while running at more than 100 frames per second. The proposed method benefits from high parameters sharing between the two tasks by unifying still images and video clips processing in a single pipeline, allowing the model to be trained with data from different categories simultaneously and in a seamlessly way. Additionally, we provide important insights for end-to-end training the proposed multi-task model by decoupling key prediction parts, which consistently leads to better accuracy on both tasks. The reported results on four datasets (MPII, Human3.6M, Penn Action and NTU RGB+D) demonstrate the effectiveness of our method on the targeted tasks. Our source code and trained weights are publicly available at https://github.com/dluvizon/deephar.