 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Similarity of Synthetic Image Utility
Dec 18, 2025Synthetic medical image data can unlock the potential of deep learning (DL)-based clinical decision support (CDS) systems through the creation of large scale, privacy-preserving, training sets. Despite the significant progress in this field, there is still a largely unanswered research question: "How can we quantitatively assess the similarity of a synthetically generated set of images with a set of real images in a given application domain?". Today, answers to this question are mainly provided via user evaluation studies, inception-based measures, and the classification performance achieved on synthetic images. This paper proposes a novel measure to assess the similarity between synthetically generated and real sets of images, in terms of their utility for the development of DL-based CDS systems. Inspired by generalized neural additive models, and unlike inception-based measures, the proposed measure is interpretable (Interpretable Utility Similarity, IUS), explaining why a synthetic dataset could be more useful than another one in the context of a CDS system based on clinically relevant image features. The experimental results on publicly available datasets from various color medical imaging modalities including endoscopic, dermoscopic and fundus imaging, indicate that selecting synthetic images of high utility similarity using IUS can result in relative improvements of up to 54.6% in terms of classification performance. The generality of IUS for synthetic data assessment is demonstrated also for greyscale X-ray and ultrasound imaging modalities. IUS implementation is available at https://github.com/innoisys/ius
DeepFEA: Deep Learning for Prediction of Transient Finite Element Analysis Solutions
Dec 05, 2024
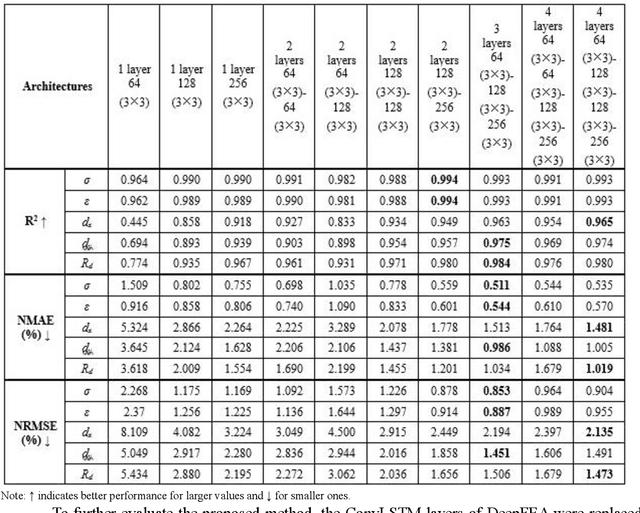
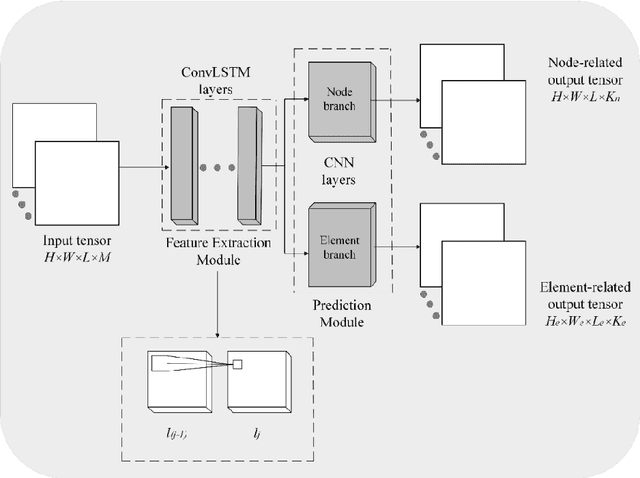
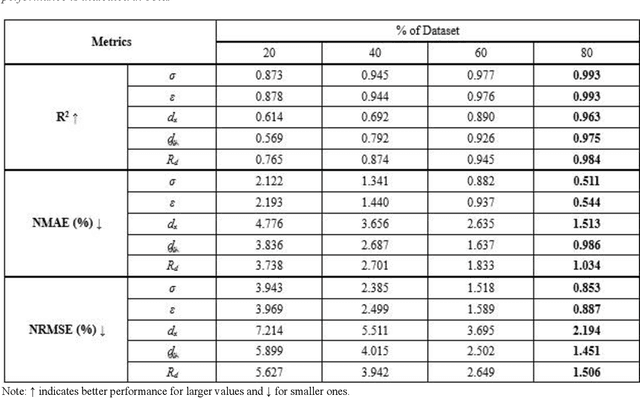
Finite Element Analysis (FEA) is a powerful but computationally intensive method for simulating physical phenomena. Recent advancements in machine learning have led to surrogate models capable of accelerating FEA. Yet there are still limitations in developing surrogates of transient FEA models that can simultaneously predict the solutions for both nodes and elements with applicability on both the 2D and 3D domains. Motivated by this research gap, this study proposes DeepFEA, a deep learning-based framework that leverages a multilayer Convolutional Long Short-Term Memory (ConvLSTM) network branching into two parallel convolutional neural networks to predict the solutions for both nodes and elements of FEA models. The proposed network is optimized using a novel adaptive learning algorithm, called Node-Element Loss Optimization (NELO). NELO minimizes the error occurring at both branches of the network enabling the prediction of solutions for transient FEA simulations. The experimental evaluation of DeepFEA is performed on three datasets in the context of structural mechanics, generated to serve as publicly available reference datasets. The results show that DeepFEA can achieve less than 3% normalized mean and root mean squared error for 2D and 3D simulation scenarios, and inference times that are two orders of magnitude faster than FEA. In contrast, relevant state-of-the-art methods face challenges with multi-dimensional output and dynamic input prediction. Furthermore, DeepFEA's robustness was demonstrated in a real-life biomedical scenario, confirming its suitability for accurate and efficient predictions of FEA simulations.
Clinical Evaluation of Medical Image Synthesis: A Case Study in Wireless Capsule Endoscopy
Oct 31, 2024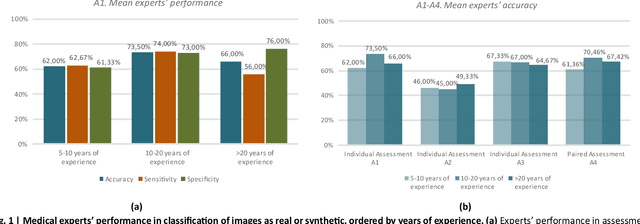

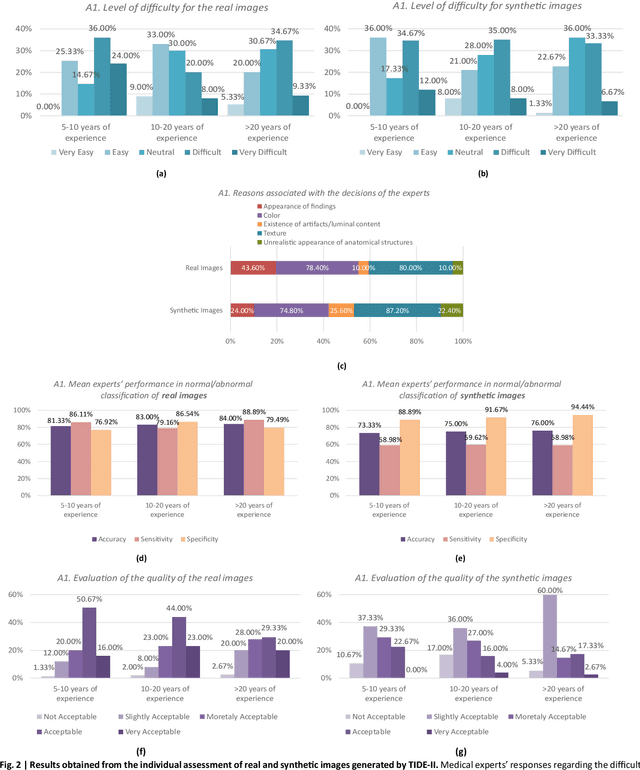

Sharing retrospectively acquired data is essential for both clinical research and training. Synthetic Data Generation (SDG), using Artificial Intelligence (AI) models, can overcome privacy barriers in sharing clinical data, enabling advancements in medical diagnostics. This study focuses on the clinical evaluation of medical SDG, with a proof-of-concept investigation on diagnosing Inflammatory Bowel Disease (IBD) using Wireless Capsule Endoscopy (WCE) images. The paper contributes by a) presenting a protocol for the systematic evaluation of synthetic images by medical experts and b) applying it to assess TIDE-II, a novel variational autoencoder-based model for high-resolution WCE image synthesis, with a comprehensive qualitative evaluation conducted by 10 international WCE specialists, focusing on image quality, diversity, realism, and clinical decision-making. The results show that TIDE-II generates clinically relevant WCE images, helping to address data scarcity and enhance diagnostic tools. The proposed protocol serves as a reference for future research on medical image-generation techniques.
Intuitionistic Fuzzy Cognitive Maps for Interpretable Image Classification
Aug 07, 2024The interpretability of machine learning models is critical, as users may be reluctant to rely on their inferences. Intuitionistic FCMs (iFCMs) have been proposed as an extension of FCMs offering a natural mechanism to assess the quality of their output through the estimation of hesitancy, a concept resembling to human hesitation in decision making. To address the challenge of interpretable image classification, this paper introduces a novel framework, named Interpretable Intuitionistic FCM (I2FCM) which is domain-independent, simple to implement, and can be applied on Convolutional Neural Network (CNN) models, rendering them interpretable. To the best of our knowledge this is the first time iFCMs are applied for image classification. Further novel contributions include: a feature extraction process focusing on the most informative image regions; a learning algorithm for data-driven determination of the intuitionistic fuzzy interconnections of the iFCM; an inherently interpretable classification approach based on image contents. In the context of image classification, hesitancy is considered as a degree of inconfidence with which an image is categorized to a class. The constructed iFCM model distinguishes the most representative image semantics and analyses them utilizing cause-and-effect relations. The effectiveness of the introduced framework is evaluated on publicly available datasets, and the experimental results confirm that it can provide enhanced classification performance, while providing interpretable inferences.
Soft-Hard Attention U-Net Model and Benchmark Dataset for Multiscale Image Shadow Removal
Aug 07, 2024


Effective shadow removal is pivotal in enhancing the visual quality of images in various applications, ranging from computer vision to digital photography. During the last decades physics and machine learning -based methodologies have been proposed; however, most of them have limited capacity in capturing complex shadow patterns due to restrictive model assumptions, neglecting the fact that shadows usually appear at different scales. Also, current datasets used for benchmarking shadow removal are composed of a limited number of images with simple scenes containing mainly uniform shadows cast by single objects, whereas only a few of them include both manual shadow annotations and paired shadow-free images. Aiming to address all these limitations in the context of natural scene imaging, including urban environments with complex scenes, the contribution of this study is twofold: a) it proposes a novel deep learning architecture, named Soft-Hard Attention U-net (SHAU), focusing on multiscale shadow removal; b) it provides a novel synthetic dataset, named Multiscale Shadow Removal Dataset (MSRD), containing complex shadow patterns of multiple scales, aiming to serve as a privacy-preserving dataset for a more comprehensive benchmarking of future shadow removal methodologies. Key architectural components of SHAU are the soft and hard attention modules, which along with multiscale feature extraction blocks enable effective shadow removal of different scales and intensities. The results demonstrate the effectiveness of SHAU over the relevant state-of-the-art shadow removal methods across various benchmark datasets, improving the Peak Signal-to-Noise Ratio and Root Mean Square Error for the shadow area by 25.1% and 61.3%, respectively.
This Intestine Does Not Exist: Multiscale Residual Variational Autoencoder for Realistic Wireless Capsule Endoscopy Image Generation
Feb 07, 2023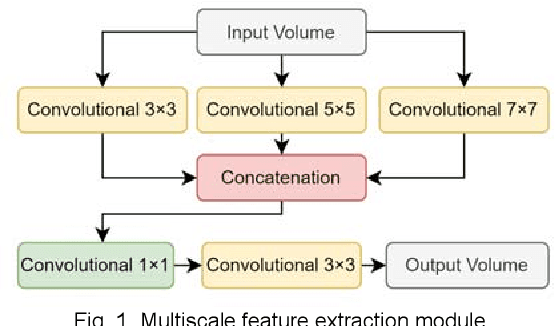



Medical image synthesis has emerged as a promising solution to address the limited availability of annotated medical data needed for training machine learning algorithms in the context of image-based Clinical Decision Support (CDS) systems. To this end, Generative Adversarial Networks (GANs) have been mainly applied to support the algorithm training process by generating synthetic images for data augmentation. However, in the field of Wireless Capsule Endoscopy (WCE), the limited content diversity and size of existing publicly available annotated datasets, adversely affect both the training stability and synthesis performance of GANs. Aiming to a viable solution for WCE image synthesis, a novel Variational Autoencoder architecture is proposed, namely "This Intestine Does not Exist" (TIDE). The proposed architecture comprises multiscale feature extraction convolutional blocks and residual connections, which enable the generation of high-quality and diverse datasets even with a limited number of training images. Contrary to the current approaches, which are oriented towards the augmentation of the available datasets, this study demonstrates that using TIDE, real WCE datasets can be fully substituted by artificially generated ones, without compromising classification performance. Furthermore, qualitative and user evaluation studies by experienced WCE specialists, validate from a medical viewpoint that both the normal and abnormal WCE images synthesized by TIDE are sufficiently realistic.
E Pluribus Unum Interpretable Convolutional Neural Networks
Aug 10, 2022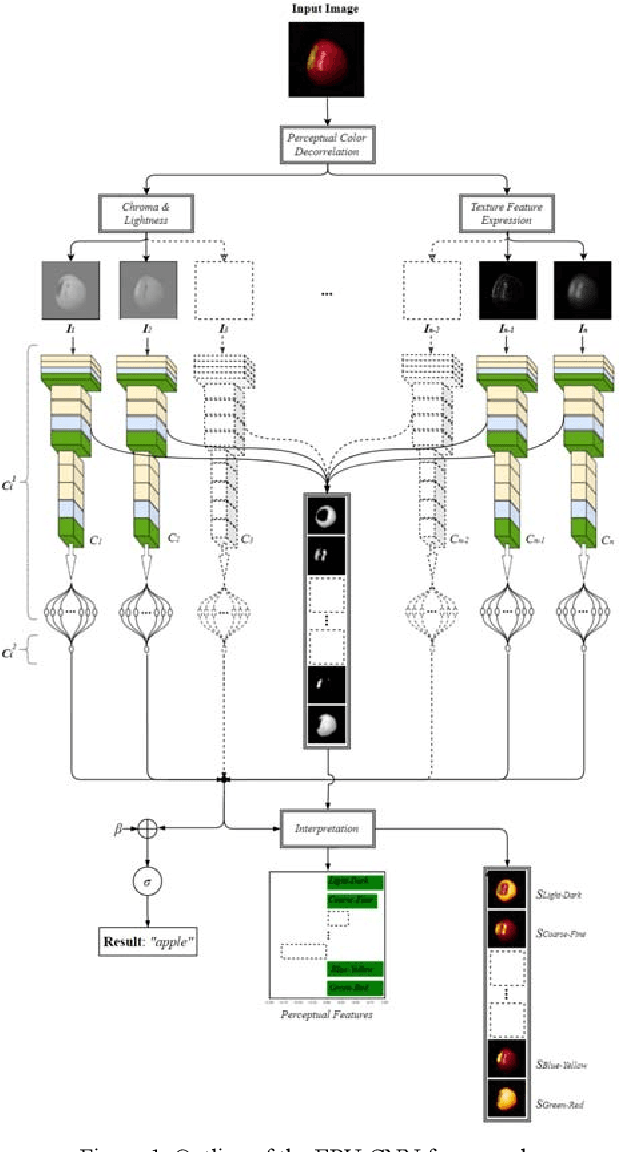
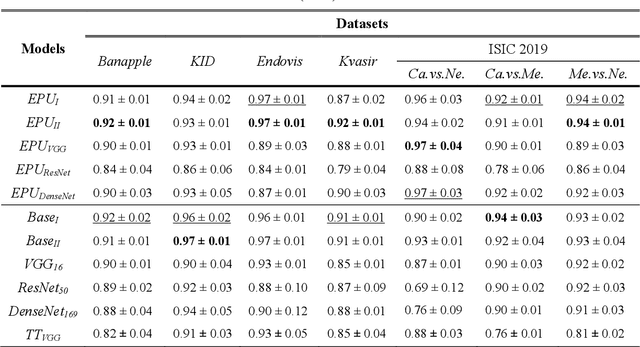
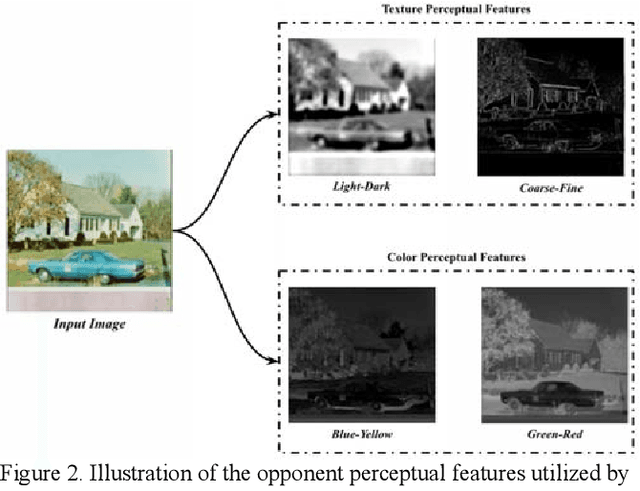

The adoption of Convolutional Neural Network (CNN) models in high-stake domains is hindered by their inability to meet society's demand for transparency in decision-making. So far, a growing number of methodologies have emerged for developing CNN models that are interpretable by design. However, such models are not capable of providing interpretations in accordance with human perception, while maintaining competent performance. In this paper, we tackle these challenges with a novel, general framework for instantiating inherently interpretable CNN models, named E Pluribus Unum Interpretable CNN (EPU-CNN). An EPU-CNN model consists of CNN sub-networks, each of which receives a different representation of an input image expressing a perceptual feature, such as color or texture. The output of an EPU-CNN model consists of the classification prediction and its interpretation, in terms of relative contributions of perceptual features in different regions of the input image. EPU-CNN models have been extensively evaluated on various publicly available datasets, as well as a contributed benchmark dataset. Medical datasets are used to demonstrate the applicability of EPU-CNN for risk-sensitive decisions in medicine. The experimental results indicate that EPU-CNN models can achieve a comparable or better classification performance than other CNN architectures while providing humanly perceivable interpretations.
Fuzzy Pooling
Feb 12, 2022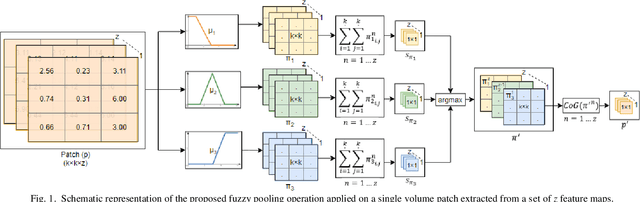



Convolutional Neural Networks (CNNs) are artificial learning systems typically based on two operations: convolution, which implements feature extraction through filtering, and pooling, which implements dimensionality reduction. The impact of pooling in the classification performance of the CNNs has been highlighted in several previous works, and a variety of alternative pooling operators have been proposed. However, only a few of them tackle with the uncertainty that is naturally propagated from the input layer to the feature maps of the hidden layers through convolutions. In this paper we present a novel pooling operation based on (type-1) fuzzy sets to cope with the local imprecision of the feature maps, and we investigate its performance in the context of image classification. Fuzzy pooling is performed by fuzzification, aggregation and defuzzification of feature map neighborhoods. It is used for the construction of a fuzzy pooling layer that can be applied as a drop-in replacement of the current, crisp, pooling layers of CNN architectures. Several experiments using publicly available datasets show that the proposed approach can enhance the classification performance of a CNN. A comparative evaluation shows that it outperforms state-of-the-art pooling approaches.
* The final version of the paper has been published in https://ieeexplore.ieee.org/document/9197689
SalSum: Saliency-based Video Summarization using Generative Adversarial Networks
Nov 20, 2020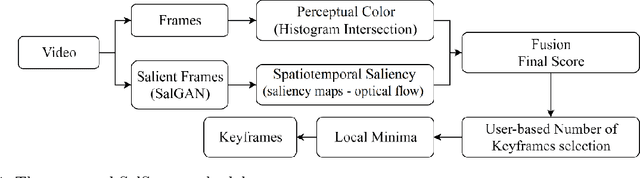

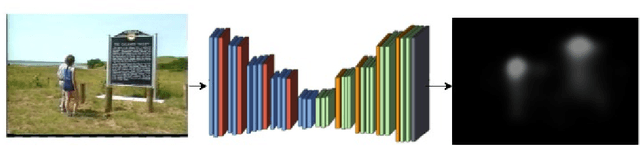

The huge amount of video data produced daily by camera-based systems, such as surveilance, medical and telecommunication systems, emerges the need for effective video summarization (VS) methods. These methods should be capable of creating an overview of the video content. In this paper, we propose a novel VS method based on a Generative Adversarial Network (GAN) model pre-trained with human eye fixations. The main contribution of the proposed method is that it can provide perceptually compatible video summaries by combining both perceived color and spatiotemporal visual attention cues in a unsupervised scheme. Several fusion approaches are considered for robustness under uncertainty, and personalization. The proposed method is evaluated in comparison to state-of-the-art VS approaches on the benchmark dataset VSUMM. The experimental results conclude that SalSum outperforms the state-of-the-art approaches by providing the highest f-measure score on the VSUMM benchmark.