 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Similarity of Synthetic Image Utility
Dec 18, 2025Synthetic medical image data can unlock the potential of deep learning (DL)-based clinical decision support (CDS) systems through the creation of large scale, privacy-preserving, training sets. Despite the significant progress in this field, there is still a largely unanswered research question: "How can we quantitatively assess the similarity of a synthetically generated set of images with a set of real images in a given application domain?". Today, answers to this question are mainly provided via user evaluation studies, inception-based measures, and the classification performance achieved on synthetic images. This paper proposes a novel measure to assess the similarity between synthetically generated and real sets of images, in terms of their utility for the development of DL-based CDS systems. Inspired by generalized neural additive models, and unlike inception-based measures, the proposed measure is interpretable (Interpretable Utility Similarity, IUS), explaining why a synthetic dataset could be more useful than another one in the context of a CDS system based on clinically relevant image features. The experimental results on publicly available datasets from various color medical imaging modalities including endoscopic, dermoscopic and fundus imaging, indicate that selecting synthetic images of high utility similarity using IUS can result in relative improvements of up to 54.6% in terms of classification performance. The generality of IUS for synthetic data assessment is demonstrated also for greyscale X-ray and ultrasound imaging modalities. IUS implementation is available at https://github.com/innoisys/ius
DeepFEA: Deep Learning for Prediction of Transient Finite Element Analysis Solutions
Dec 05, 2024
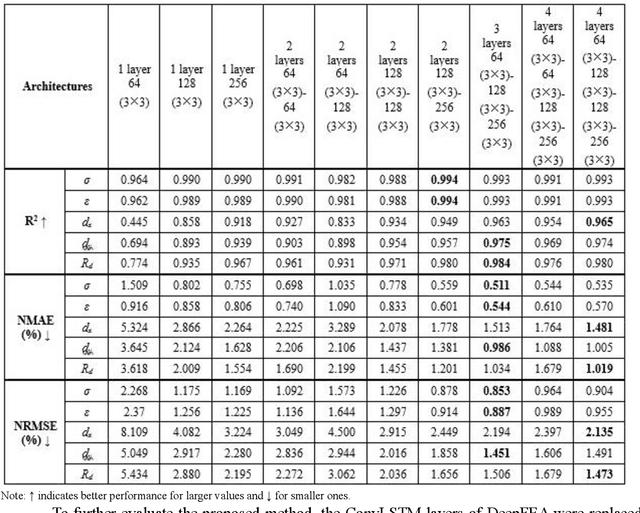
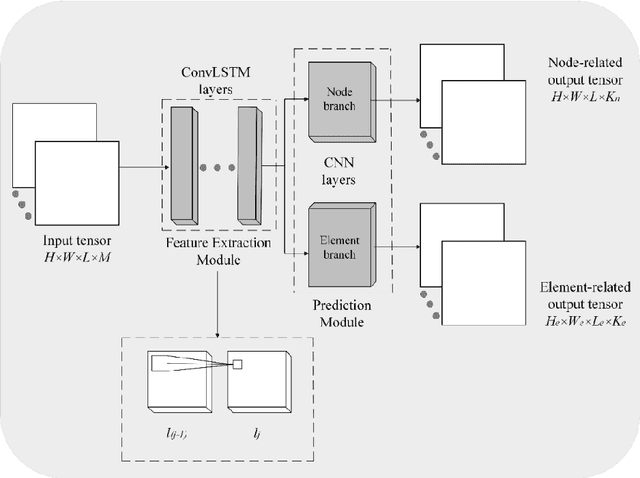
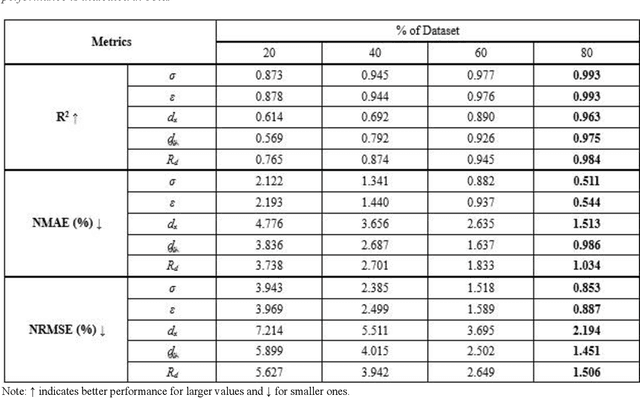
Finite Element Analysis (FEA) is a powerful but computationally intensive method for simulating physical phenomena. Recent advancements in machine learning have led to surrogate models capable of accelerating FEA. Yet there are still limitations in developing surrogates of transient FEA models that can simultaneously predict the solutions for both nodes and elements with applicability on both the 2D and 3D domains. Motivated by this research gap, this study proposes DeepFEA, a deep learning-based framework that leverages a multilayer Convolutional Long Short-Term Memory (ConvLSTM) network branching into two parallel convolutional neural networks to predict the solutions for both nodes and elements of FEA models. The proposed network is optimized using a novel adaptive learning algorithm, called Node-Element Loss Optimization (NELO). NELO minimizes the error occurring at both branches of the network enabling the prediction of solutions for transient FEA simulations. The experimental evaluation of DeepFEA is performed on three datasets in the context of structural mechanics, generated to serve as publicly available reference datasets. The results show that DeepFEA can achieve less than 3% normalized mean and root mean squared error for 2D and 3D simulation scenarios, and inference times that are two orders of magnitude faster than FEA. In contrast, relevant state-of-the-art methods face challenges with multi-dimensional output and dynamic input prediction. Furthermore, DeepFEA's robustness was demonstrated in a real-life biomedical scenario, confirming its suitability for accurate and efficient predictions of FEA simulations.
E Pluribus Unum Interpretable Convolutional Neural Networks
Aug 10, 2022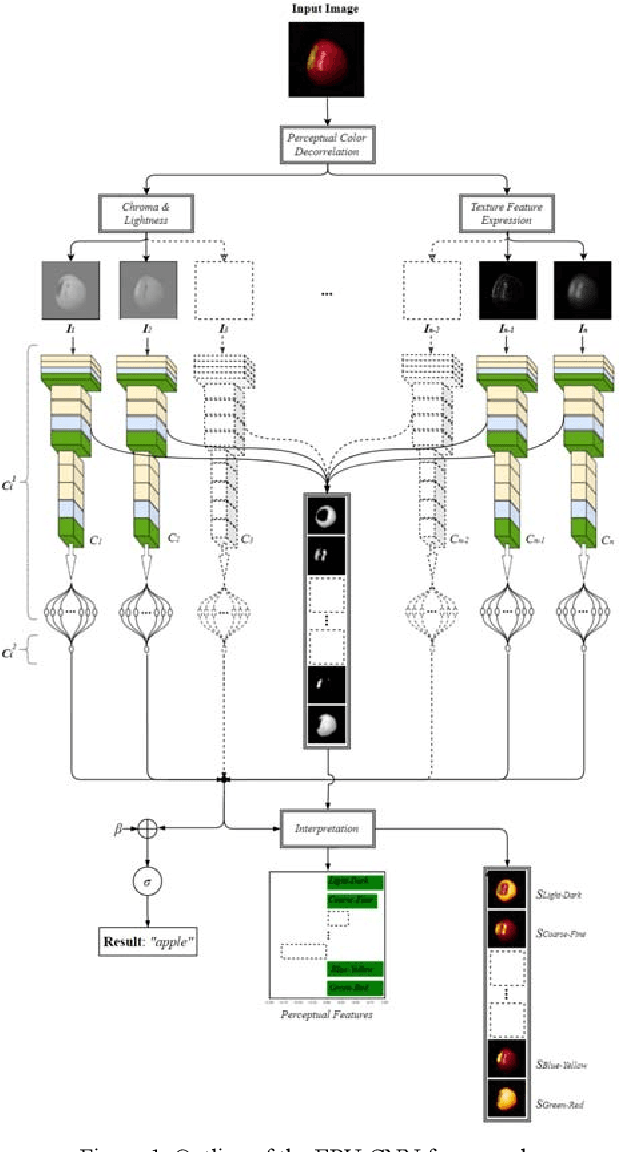
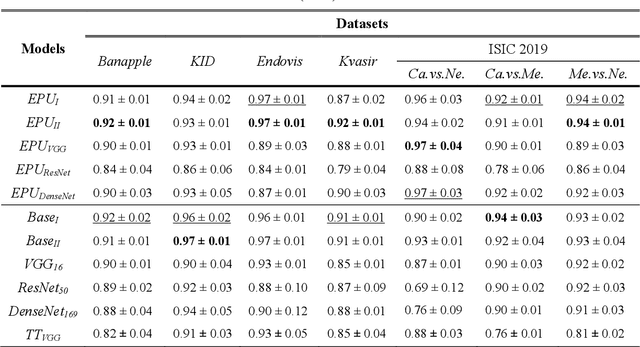
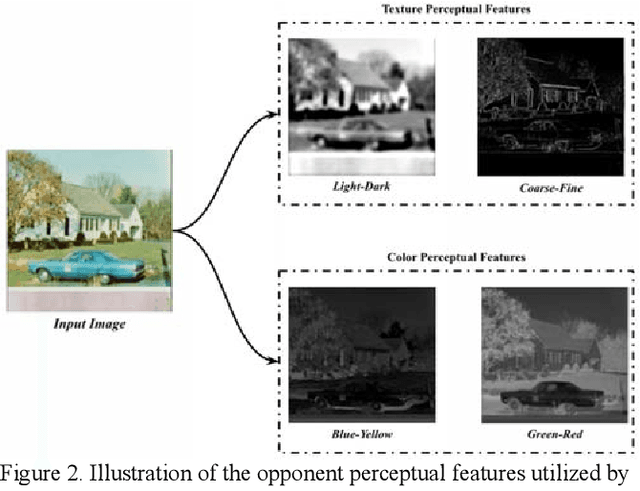

The adoption of Convolutional Neural Network (CNN) models in high-stake domains is hindered by their inability to meet society's demand for transparency in decision-making. So far, a growing number of methodologies have emerged for developing CNN models that are interpretable by design. However, such models are not capable of providing interpretations in accordance with human perception, while maintaining competent performance. In this paper, we tackle these challenges with a novel, general framework for instantiating inherently interpretable CNN models, named E Pluribus Unum Interpretable CNN (EPU-CNN). An EPU-CNN model consists of CNN sub-networks, each of which receives a different representation of an input image expressing a perceptual feature, such as color or texture. The output of an EPU-CNN model consists of the classification prediction and its interpretation, in terms of relative contributions of perceptual features in different regions of the input image. EPU-CNN models have been extensively evaluated on various publicly available datasets, as well as a contributed benchmark dataset. Medical datasets are used to demonstrate the applicability of EPU-CNN for risk-sensitive decisions in medicine. The experimental results indicate that EPU-CNN models can achieve a comparable or better classification performance than other CNN architectures while providing humanly perceivable interpretations.
SalSum: Saliency-based Video Summarization using Generative Adversarial Networks
Nov 20, 2020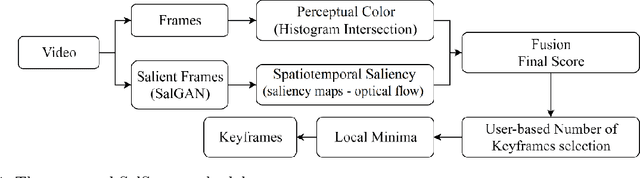

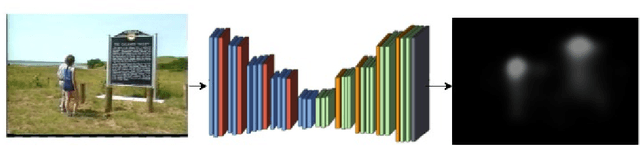

The huge amount of video data produced daily by camera-based systems, such as surveilance, medical and telecommunication systems, emerges the need for effective video summarization (VS) methods. These methods should be capable of creating an overview of the video content. In this paper, we propose a novel VS method based on a Generative Adversarial Network (GAN) model pre-trained with human eye fixations. The main contribution of the proposed method is that it can provide perceptually compatible video summaries by combining both perceived color and spatiotemporal visual attention cues in a unsupervised scheme. Several fusion approaches are considered for robustness under uncertainty, and personalization. The proposed method is evaluated in comparison to state-of-the-art VS approaches on the benchmark dataset VSUMM. The experimental results conclude that SalSum outperforms the state-of-the-art approaches by providing the highest f-measure score on the VSUMM benchmark.