 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Hard Attention U-Net Model and Benchmark Dataset for Multiscale Image Shadow Removal
Aug 07, 2024


Effective shadow removal is pivotal in enhancing the visual quality of images in various applications, ranging from computer vision to digital photography. During the last decades physics and machine learning -based methodologies have been proposed; however, most of them have limited capacity in capturing complex shadow patterns due to restrictive model assumptions, neglecting the fact that shadows usually appear at different scales. Also, current datasets used for benchmarking shadow removal are composed of a limited number of images with simple scenes containing mainly uniform shadows cast by single objects, whereas only a few of them include both manual shadow annotations and paired shadow-free images. Aiming to address all these limitations in the context of natural scene imaging, including urban environments with complex scenes, the contribution of this study is twofold: a) it proposes a novel deep learning architecture, named Soft-Hard Attention U-net (SHAU), focusing on multiscale shadow removal; b) it provides a novel synthetic dataset, named Multiscale Shadow Removal Dataset (MSRD), containing complex shadow patterns of multiple scales, aiming to serve as a privacy-preserving dataset for a more comprehensive benchmarking of future shadow removal methodologies. Key architectural components of SHAU are the soft and hard attention modules, which along with multiscale feature extraction blocks enable effective shadow removal of different scales and intensities. The results demonstrate the effectiveness of SHAU over the relevant state-of-the-art shadow removal methods across various benchmark datasets, improving the Peak Signal-to-Noise Ratio and Root Mean Square Error for the shadow area by 25.1% and 61.3%, respectively.
E Pluribus Unum Interpretable Convolutional Neural Networks
Aug 10, 2022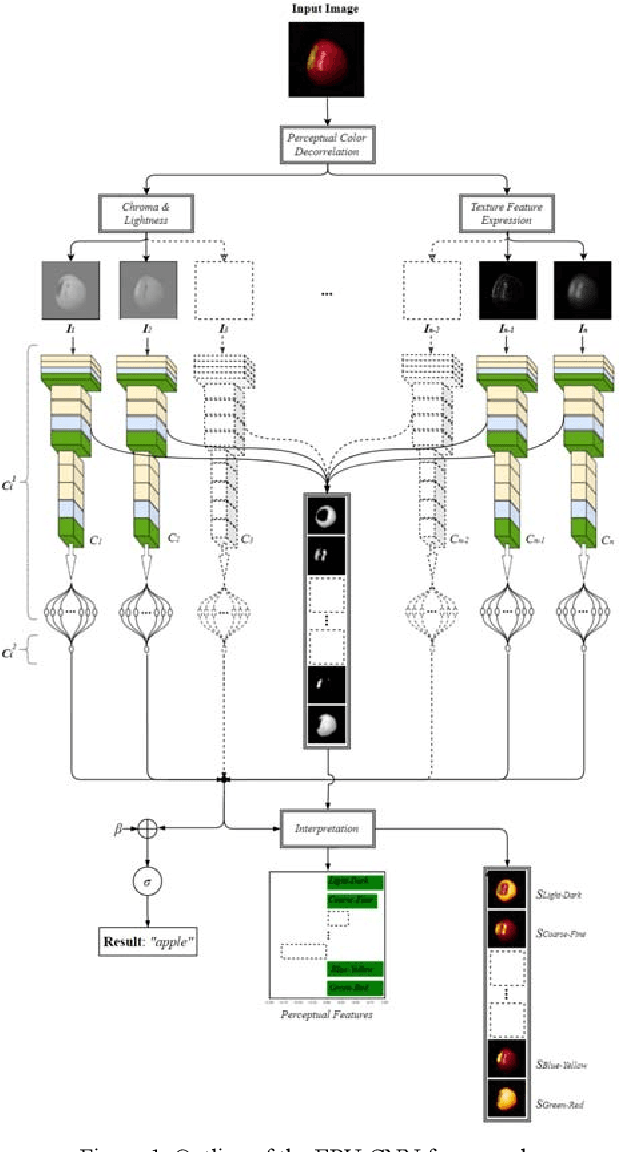
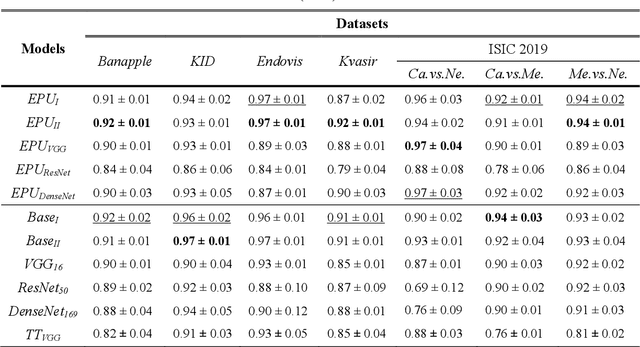
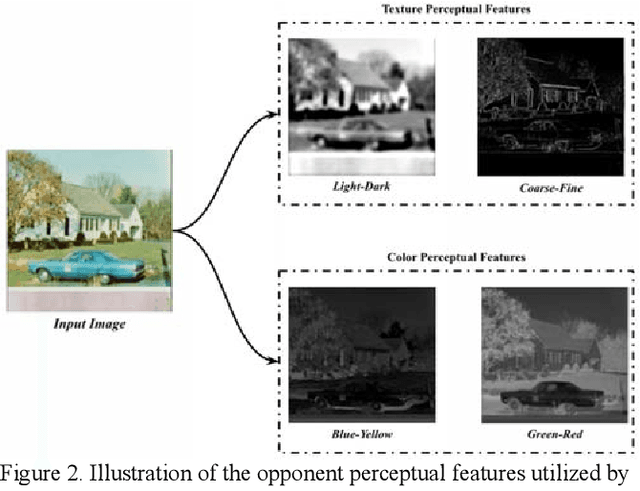

The adoption of Convolutional Neural Network (CNN) models in high-stake domains is hindered by their inability to meet society's demand for transparency in decision-making. So far, a growing number of methodologies have emerged for developing CNN models that are interpretable by design. However, such models are not capable of providing interpretations in accordance with human perception, while maintaining competent performance. In this paper, we tackle these challenges with a novel, general framework for instantiating inherently interpretable CNN models, named E Pluribus Unum Interpretable CNN (EPU-CNN). An EPU-CNN model consists of CNN sub-networks, each of which receives a different representation of an input image expressing a perceptual feature, such as color or texture. The output of an EPU-CNN model consists of the classification prediction and its interpretation, in terms of relative contributions of perceptual features in different regions of the input image. EPU-CNN models have been extensively evaluated on various publicly available datasets, as well as a contributed benchmark dataset. Medical datasets are used to demonstrate the applicability of EPU-CNN for risk-sensitive decisions in medicine. The experimental results indicate that EPU-CNN models can achieve a comparable or better classification performance than other CNN architectures while providing humanly perceivable interpretations.