 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide and Seek: Scaling Machine Learning for Combinatorial Optimization via the Probabilistic Method
Nov 21, 2022
Applying deep learning to solve real-life instances of hard combinatorial problems has tremendous potential. Research in this direction has focused on the Boolean satisfiability (SAT) problem, both because of its theoretical centrality and practical importance. A major roadblock faced, though, is that training sets are restricted to random formulas of size several orders of magnitude smaller than formulas of practical interest, raising serious concerns about generalization. This is because labeling random formulas of increasing size rapidly becomes intractable. By exploiting the probabilistic method in a fundamental way, we remove this roadblock entirely: we show how to generate correctly labeled random formulas of any desired size, without having to solve the underlying decision problem. Moreover, the difficulty of the classification task for the formulas produced by our generator is tunable by varying a simple scalar parameter. This opens up an entirely new level of sophistication for the machine learning methods that can be brought to bear on Satisfiability. Using our generator, we train existing state-of-the-art models for the task of predicting satisfiability on formulas with 10,000 variables. We find that they do no better than random guessing. As a first indication of what can be achieved with the new generator, we present a novel classifier that performs significantly better than random guessing 99% on the same datasets, for most difficulty levels. Crucially, unlike past approaches that learn based on syntactic features of a formula, our classifier performs its learning on a short prefix of a solver's computation, an approach that we expect to be of independent interest.
Bad Global Minima Exist and SGD Can Reach Them
Jun 06, 2019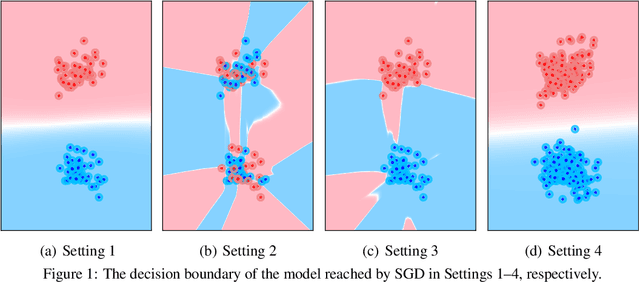
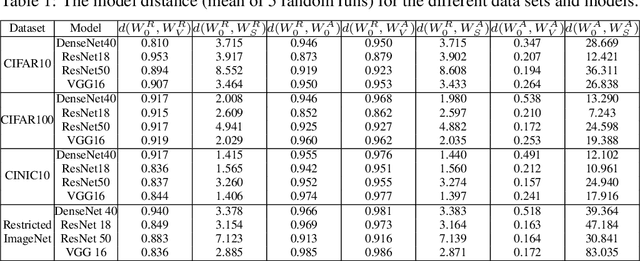
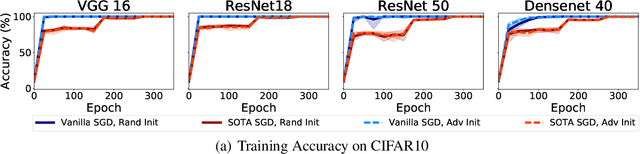
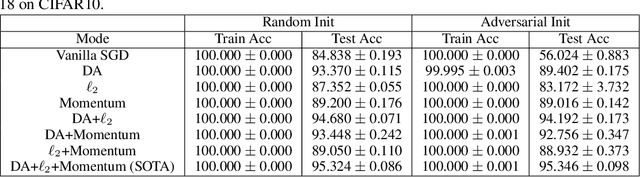
Several recent works have aimed to explain why severely overparameterized models, generalize well when trained by Stochastic Gradient Descent (SGD). The emergent consensus explanation has two parts: the first is that there are "no bad local minima", while the second is that SGD performs implicit regularization by having a bias towards low complexity models. We revisit both of these ideas in the context of image classification with common deep neural network architectures. Our first finding is that there exist bad global minima, i.e., models that fit the training set perfectly, yet have poor generalization. Our second finding is that given only unlabeled training data, we can easily construct initializations that will cause SGD to quickly converge to such bad global minima. For example, on CIFAR, CINIC10, and (Restricted) ImageNet, this can be achieved by starting SGD at a model derived by fitting random labels on the training data: while subsequent SGD training (with the correct labels) will reach zero training error, the resulting model will exhibit a test accuracy degradation of up to 40% compared to training from a random initialization. Finally, we show that regularization seems to provide SGD with an escape route: once heuristics such as data augmentation are used, starting from a complex model (adversarial initialization) has no effect on the test accuracy.
Near-Optimal Entrywise Sampling for Data Matrices
Nov 19, 2013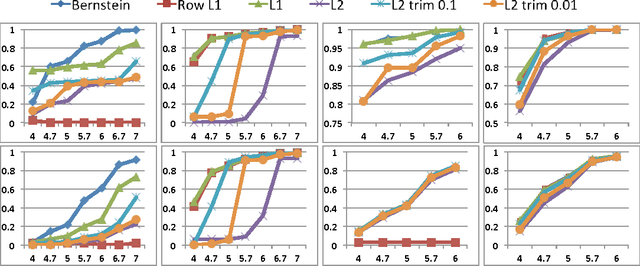
We consider the problem of selecting non-zero entries of a matrix $A$ in order to produce a sparse sketch of it, $B$, that minimizes $\|A-B\|_2$. For large $m \times n$ matrices, such that $n \gg m$ (for example, representing $n$ observations over $m$ attributes) we give sampling distributions that exhibit four important properties. First, they have closed forms computable from minimal information regarding $A$. Second, they allow sketching of matrices whose non-zeros are presented to the algorithm in arbitrary order as a stream, with $O(1)$ computation per non-zero. Third, the resulting sketch matrices are not only sparse, but their non-zero entries are highly compressible. Lastly, and most importantly, under mild assumptions, our distributions are provably competitive with the optimal offline distribution. Note that the probabilities in the optimal offline distribution may be complex functions of all the entries in the matrix. Therefore, regardless of computational complexity, the optimal distribution might be impossible to compute in the streaming model.
Hiding Satisfying Assignments: Two are Better than One
Mar 20, 2005
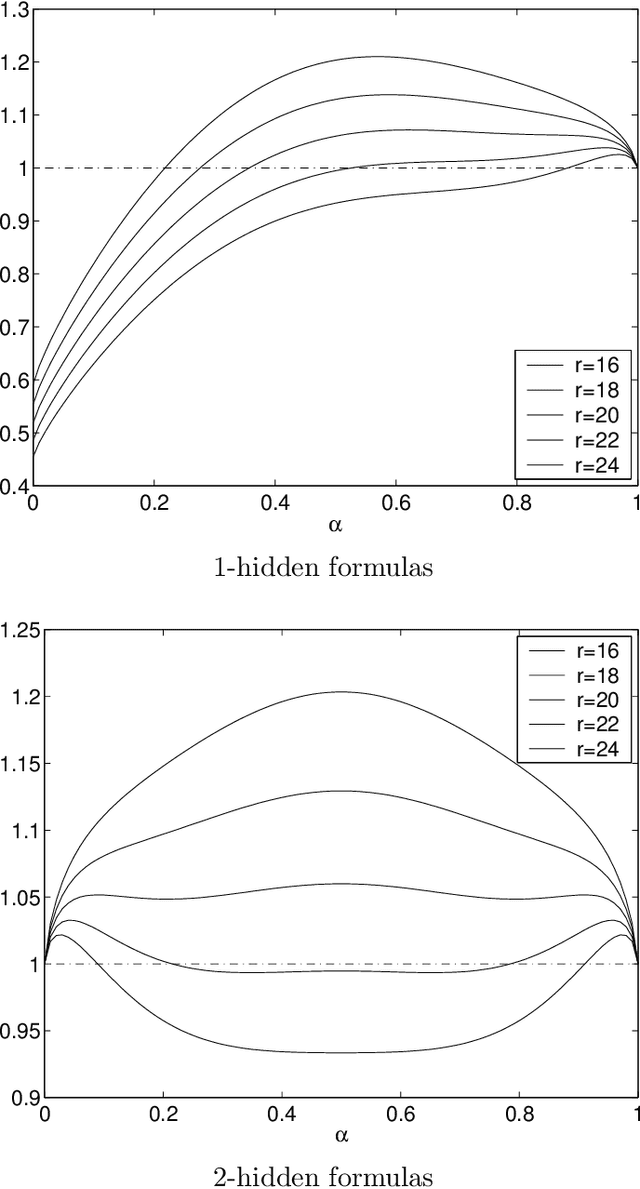
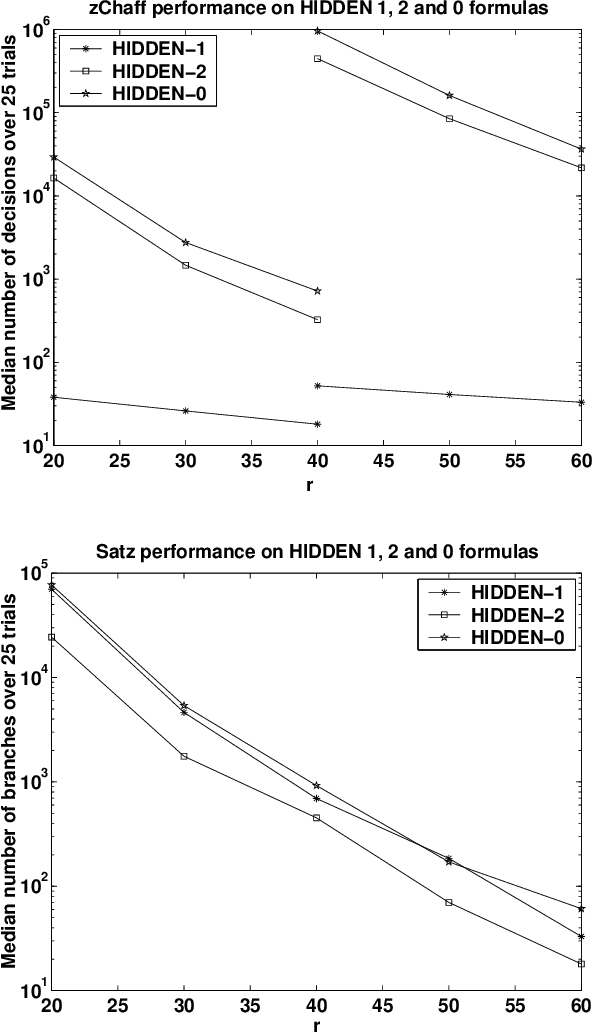
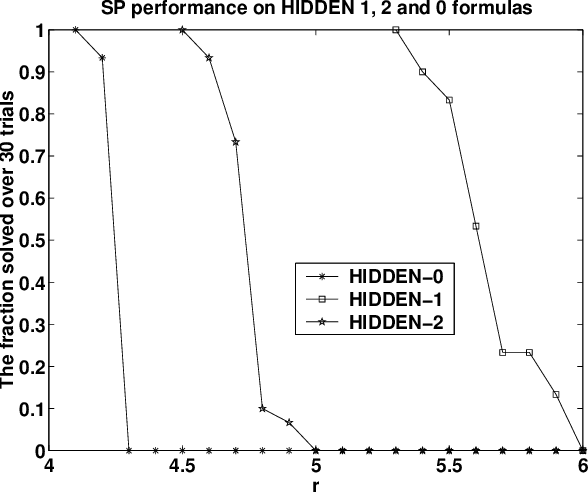
The evaluation of incomplete satisfiability solvers depends critically on the availability of hard satisfiable instances. A plausible source of such instances consists of random k-SAT formulas whose clauses are chosen uniformly from among all clauses satisfying some randomly chosen truth assignment A. Unfortunately, instances generated in this manner tend to be relatively easy and can be solved efficiently by practical heuristics. Roughly speaking, as the formula's density increases, for a number of different algorithms, A acts as a stronger and stronger attractor. Motivated by recent results on the geometry of the space of satisfying truth assignments of random k-SAT and NAE-k-SAT formulas, we introduce a simple twist on this basic model, which appears to dramatically increase its hardness. Namely, in addition to forbidding the clauses violated by the hidden assignment A, we also forbid the clauses violated by its complement, so that both A and complement of A are satisfying. It appears that under this "symmetrization'' the effects of the two attractors largely cancel out, making it much harder for algorithms to find any truth assignment. We give theoretical and experimental evidence supporting this assertion.