 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Grammatical Error Correction
Oct 06, 2020
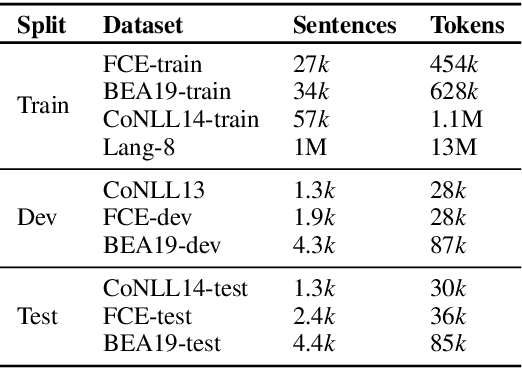
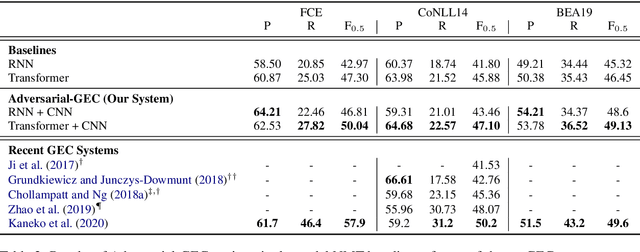
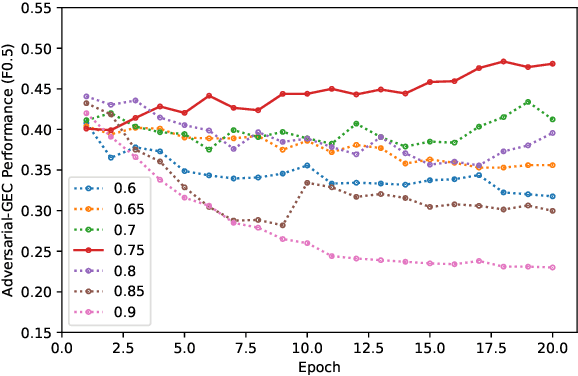
Recent works in Grammatical Error Correction (GEC) have leveraged the progress in Neural Machine Translation (NMT), to learn rewrites from parallel corpora of grammatically incorrect and corrected sentences, achieving state-of-the-art results. At the same time, Generative Adversarial Networks (GANs) have been successful in generating realistic texts across many different tasks by learning to directly minimize the difference between human-generated and synthetic text. In this work, we present an adversarial learning approach to GEC, using the generator-discriminator framework. The generator is a Transformer model, trained to produce grammatically correct sentences given grammatically incorrect ones. The discriminator is a sentence-pair classification model, trained to judge a given pair of grammatically incorrect-correct sentences on the quality of grammatical correction. We pre-train both the discriminator and the generator on parallel texts and then fine-tune them further using a policy gradient method that assigns high rewards to sentences which could be true corrections of the grammatically incorrect text. Experimental results on FCE, CoNLL-14, and BEA-19 datasets show that Adversarial-GEC can achieve competitive GEC quality compared to NMT-based baselines.
The Unreasonable Effectiveness of Transformer Language Models in Grammatical Error Correction
Jun 04, 2019
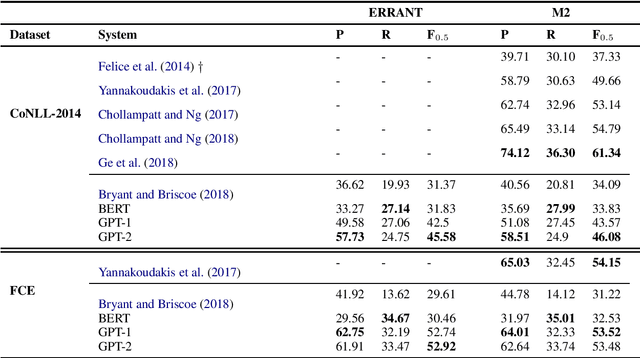

Recent work on Grammatical Error Correction (GEC) has highlighted the importance of language modeling in that it is certainly possible to achieve good performance by comparing the probabilities of the proposed edits. At the same time, advancements in language modeling have managed to generate linguistic output, which is almost indistinguishable from that of human-generated text. In this paper, we up the ante by exploring the potential of more sophisticated language models in GEC and offer some key insights on their strengths and weaknesses. We show that, in line with recent results in other NLP tasks, Transformer architectures achieve consistently high performance and provide a competitive baseline for future machine learning models.
A Distributional Semantics Approach to Implicit Language Learning
Jun 29, 2016
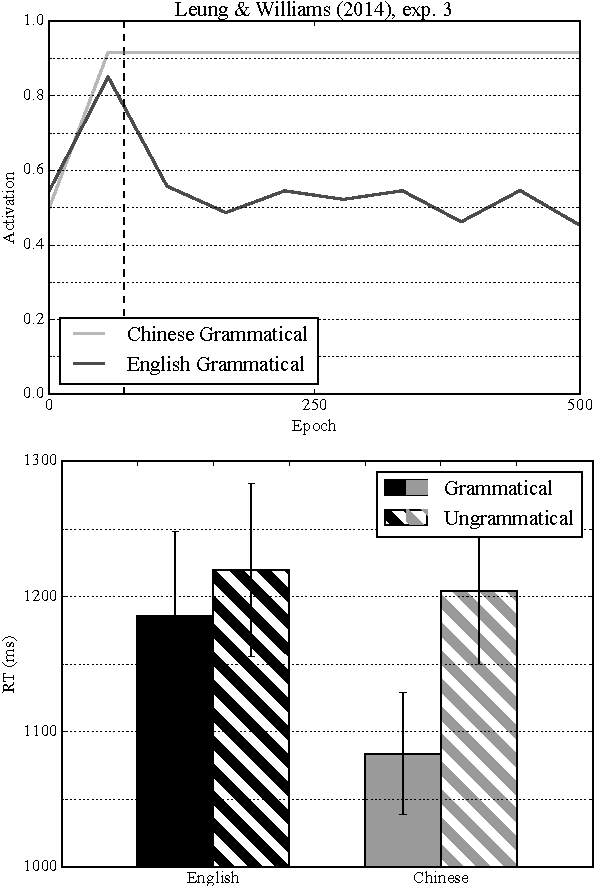
In the present paper we show that distributional information is particularly important when considering concept availability under implicit language learning conditions. Based on results from different behavioural experiments we argue that the implicit learnability of semantic regularities depends on the degree to which the relevant concept is reflected in language use. In our simulations, we train a Vector-Space model on either an English or a Chinese corpus and then feed the resulting representations to a feed-forward neural network. The task of the neural network was to find a mapping between the word representations and the novel words. Using datasets from four behavioural experiments, which used different semantic manipulations, we were able to obtain learning patterns very similar to those obtained by humans.
The word entropy of natural languages
Jun 22, 2016
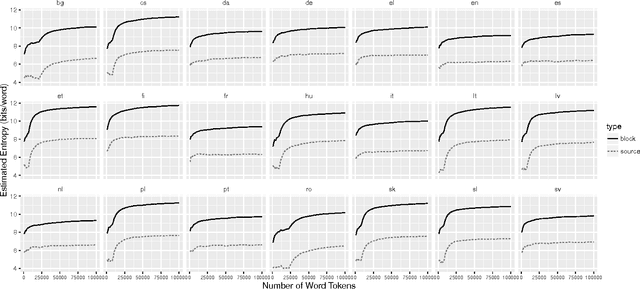

The average uncertainty associated with words is an information-theoretic concept at the heart of quantitative and computational linguistics. The entropy has been established as a measure of this average uncertainty - also called average information content. We here use parallel texts of 21 languages to establish the number of tokens at which word entropies converge to stable values. These convergence points are then used to select texts from a massively parallel corpus, and to estimate word entropies across more than 1000 languages. Our results help to establish quantitative language comparisons, to understand the performance of multilingual translation systems, and to normalize semantic similarity measures.
Automatic Text Scoring Using Neural Networks
Jun 16, 2016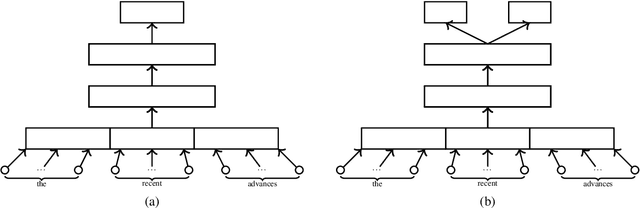
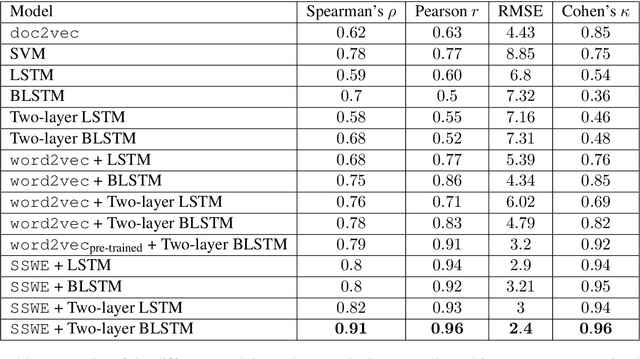
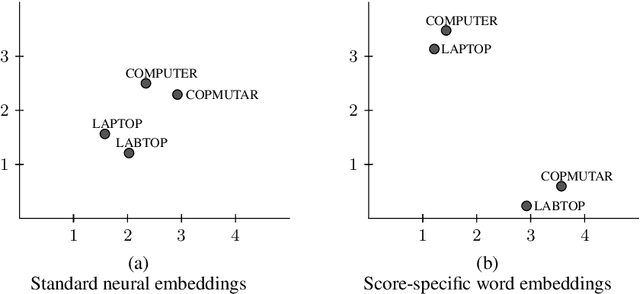

Automated Text Scoring (ATS) provides a cost-effective and consistent alternative to human marking. However, in order to achieve good performance, the predictive features of the system need to be manually engineered by human experts. We introduce a model that forms word representations by learning the extent to which specific words contribute to the text's score. Using Long-Short Term Memory networks to represent the meaning of texts, we demonstrate that a fully automated framework is able to achieve excellent results over similar approaches. In an attempt to make our results more interpretable, and inspired by recent advances in visualizing neural networks, we introduce a novel method for identifying the regions of the text that the model has found more discriminative.