 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Measure for Transparent Comparison of Linguistic Diversity in Multilingual NLP Data Sets
Mar 06, 2024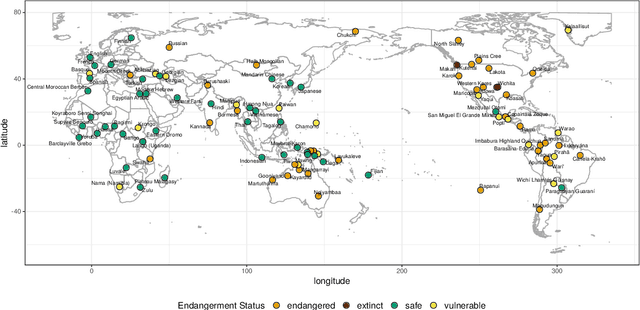
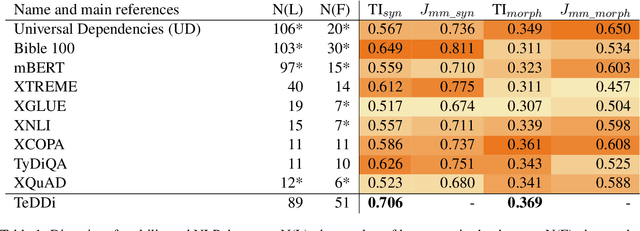
Typologically diverse benchmarks are increasingly created to track the progress achieved in multilingual NLP. Linguistic diversity of these data sets is typically measured as the number of languages or language families included in the sample, but such measures do not consider structural properties of the included languages. In this paper, we propose assessing linguistic diversity of a data set against a reference language sample as a means of maximising linguistic diversity in the long run. We represent languages as sets of features and apply a version of the Jaccard index suitable for comparing sets of measures. In addition to the features extracted from typological data bases, we propose an automatic text-based measure, which can be used as a means of overcoming the well-known problem of data sparsity in manually collected features. Our diversity score is interpretable in terms of linguistic features and can identify the types of languages that are not represented in a data set. Using our method, we analyse a range of popular multilingual data sets (UD, Bible100, mBERT, XTREME, XGLUE, XNLI, XCOPA, TyDiQA, XQuAD). In addition to ranking these data sets, we find, for example, that (poly)synthetic languages are missing in almost all of them.
The optimality of word lengths. Theoretical foundations and an empirical study
Aug 28, 2022
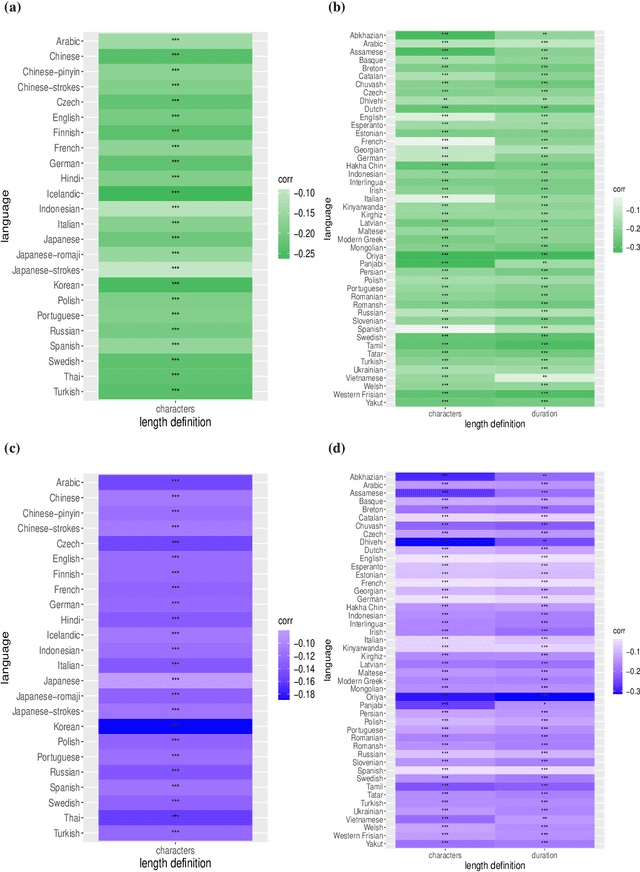
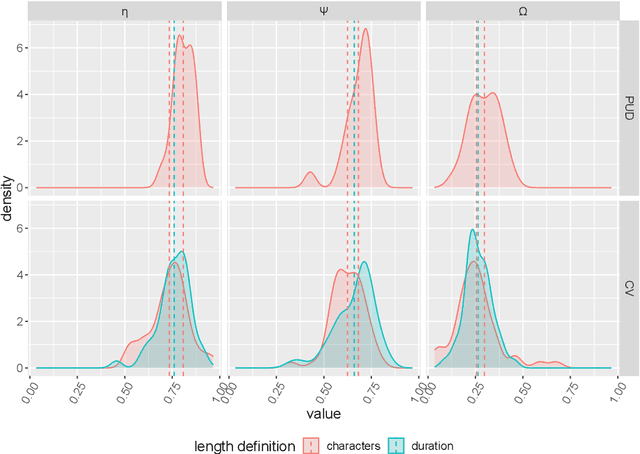
One of the most robust patterns found in human languages is Zipf's law of abbreviation, that is, the tendency of more frequent words to be shorter. Since Zipf's pioneering research, this law has been viewed as a manifestation of compression, i.e. the minimization of the length of forms - a universal principle of natural communication. Although the claim that languages are optimized has become trendy, attempts to measure the degree of optimization of languages have been rather scarce. Here we demonstrate that compression manifests itself in a wide sample of languages without exceptions, and independently of the unit of measurement. It is detectable for both word lengths in characters of written language as well as durations in time in spoken language. Moreover, to measure the degree of optimization, we derive a simple formula for a random baseline and present two scores that are dualy normalized, namely, they are normalized with respect to both the minimum and the random baseline. We analyze the theoretical and statistical pros and cons of these and other scores. Harnessing the best score, we quantify for the first time the degree of optimality of word lengths in languages. This indicates that languages are optimized to 62 or 67 percent on average (depending on the source) when word lengths are measured in characters, and to 65 percent on average when word lengths are measured in time. In general, spoken word durations are more optimized than written word lengths in characters. Beyond the analyses reported here, our work paves the way to measure the degree of optimality of the vocalizations or gestures of other species, and to compare them against written, spoken, or signed human languages.
Optimal coding and the origins of Zipfian laws
Jul 05, 2019



The problem of compression in standard information theory consists of assigning codes as short as possible to numbers. Here we consider the problem of optimal coding -- under an arbitrary coding scheme -- and show that it predicts Zipf's law of abbreviation, namely a tendency in natural languages for more frequent words to be shorter. We apply this result to investigate optimal coding also under so-called non-singular coding, a scheme where unique segmentation is not warranted but codes stand for a distinct number. Optimal non-singular coding predicts that the length of a word should grow approximately as the logarithm of its frequency rank, which is again consistent with Zipf's law of abbreviation. Optimal non-singular coding in combination with the maximum entropy principle also predicts Zipf's rank-frequency distribution. Furthermore, our findings on optimal non-singular coding challenge common beliefs about random typing. It turns out that random typing is in fact an optimal coding process, in stark contrast with the common assumption that it is detached from cost cutting considerations. Finally, we discuss the implications of optimal coding for the construction of a compact theory of Zipfian laws and other linguistic laws.
The word entropy of natural languages
Jun 22, 2016
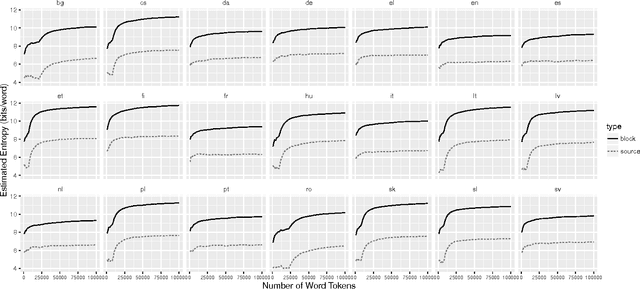

The average uncertainty associated with words is an information-theoretic concept at the heart of quantitative and computational linguistics. The entropy has been established as a measure of this average uncertainty - also called average information content. We here use parallel texts of 21 languages to establish the number of tokens at which word entropies converge to stable values. These convergence points are then used to select texts from a massively parallel corpus, and to estimate word entropies across more than 1000 languages. Our results help to establish quantitative language comparisons, to understand the performance of multilingual translation systems, and to normalize semantic similarity measures.