 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Measure for Transparent Comparison of Linguistic Diversity in Multilingual NLP Data Sets
Mar 06, 2024
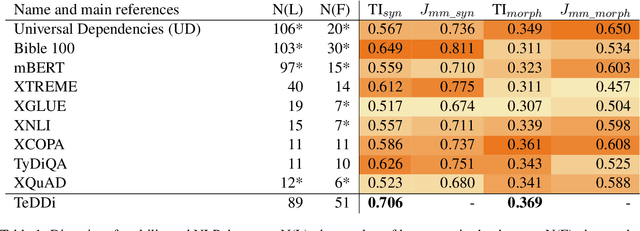
Typologically diverse benchmarks are increasingly created to track the progress achieved in multilingual NLP. Linguistic diversity of these data sets is typically measured as the number of languages or language families included in the sample, but such measures do not consider structural properties of the included languages. In this paper, we propose assessing linguistic diversity of a data set against a reference language sample as a means of maximising linguistic diversity in the long run. We represent languages as sets of features and apply a version of the Jaccard index suitable for comparing sets of measures. In addition to the features extracted from typological data bases, we propose an automatic text-based measure, which can be used as a means of overcoming the well-known problem of data sparsity in manually collected features. Our diversity score is interpretable in terms of linguistic features and can identify the types of languages that are not represented in a data set. Using our method, we analyse a range of popular multilingual data sets (UD, Bible100, mBERT, XTREME, XGLUE, XNLI, XCOPA, TyDiQA, XQuAD). In addition to ranking these data sets, we find, for example, that (poly)synthetic languages are missing in almost all of them.