Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe word entropy of natural languages
Paper and Code

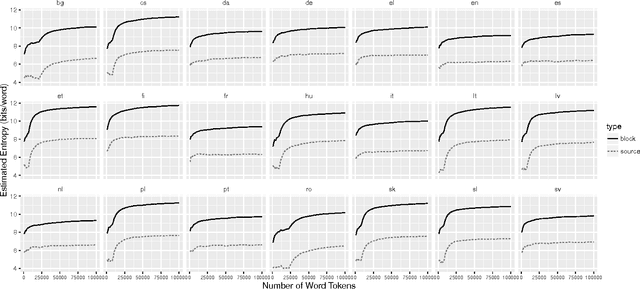
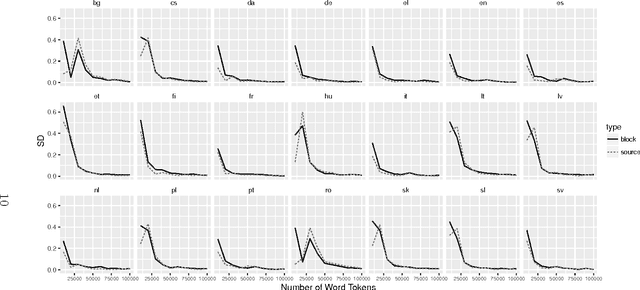

The average uncertainty associated with words is an information-theoretic concept at the heart of quantitative and computational linguistics. The entropy has been established as a measure of this average uncertainty - also called average information content. We here use parallel texts of 21 languages to establish the number of tokens at which word entropies converge to stable values. These convergence points are then used to select texts from a massively parallel corpus, and to estimate word entropies across more than 1000 languages. Our results help to establish quantitative language comparisons, to understand the performance of multilingual translation systems, and to normalize semantic similarity measures.
View paper on