 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Disentangled Framework for Transferable Named Entity Recognition
Dec 22, 2020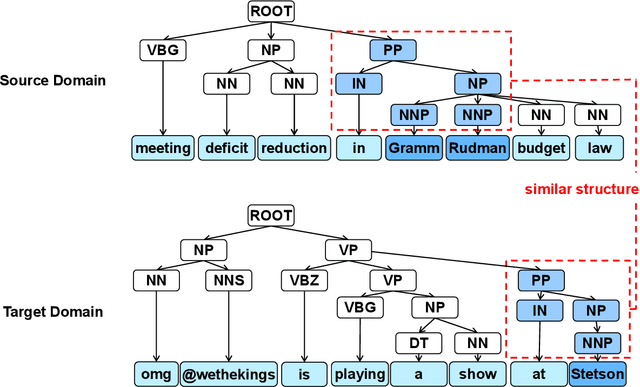
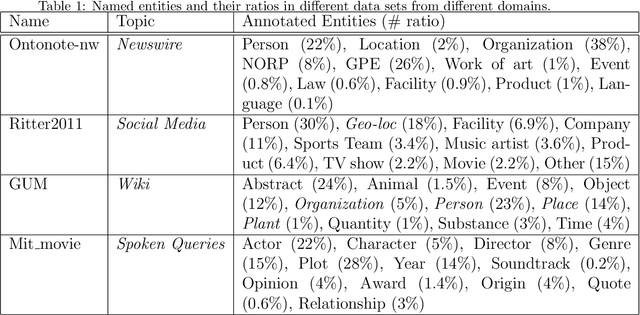
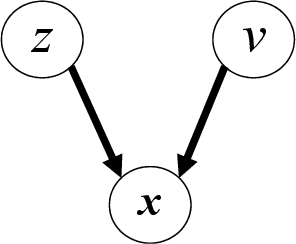
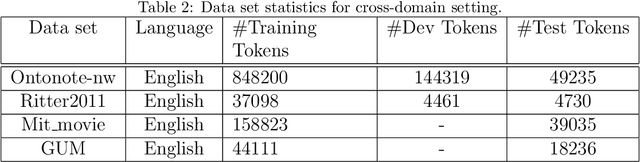
Named entity recognition (NER) for identifying proper nouns in unstructured text is one of the most important and fundamental tasks in natural language processing. However, despite the widespread use of NER models, they still require a large-scale labeled data set, which incurs a heavy burden due to manual annotation. Domain adaptation is one of the most promising solutions to this problem, where rich labeled data from the relevant source domain are utilized to strengthen the generalizability of a model based on the target domain. However, the mainstream cross-domain NER models are still affected by the following two challenges (1) Extracting domain-invariant information such as syntactic information for cross-domain transfer. (2) Integrating domain-specific information such as semantic information into the model to improve the performance of NER. In this study, we present a semi-supervised framework for transferable NER, which disentangles the domain-invariant latent variables and domain-specific latent variables. In the proposed framework, the domain-specific information is integrated with the domain-specific latent variables by using a domain predictor. The domain-specific and domain-invariant latent variables are disentangled using three mutual information regularization terms, i.e., maximizing the mutual information between the domain-specific latent variables and the original embedding, maximizing the mutual information between the domain-invariant latent variables and the original embedding, and minimizing the mutual information between the domain-specific and domain-invariant latent variables. Extensive experiments demonstrated that our model can obtain state-of-the-art performance with cross-domain and cross-lingual NER benchmark data sets.