 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFFD: A Light and Fast Face Detector for Edge Devices
May 09, 2019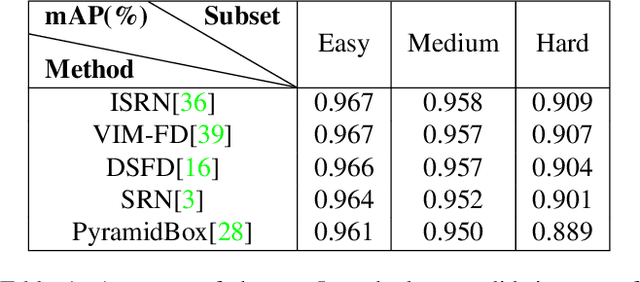
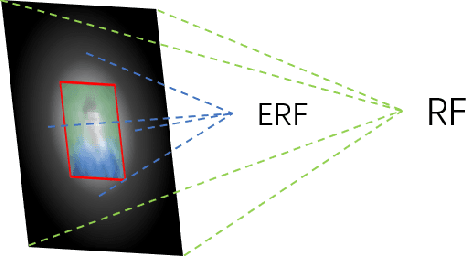
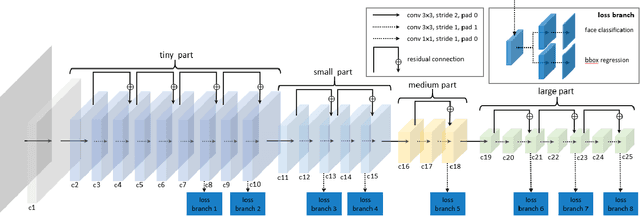
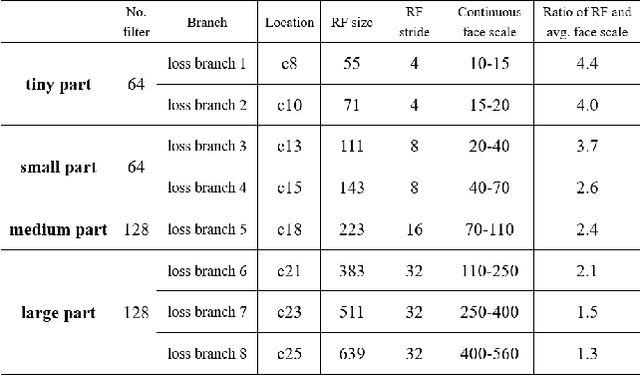
Face detection, as a fundamental technology for various applications, is always deployed on edge devices. There-fore, face detectors are supposed to have limited model size and fast inference speed. This paper introduces a Light and Fast Face Detector (LFFD) for edge devices. We rethink the receptive field (RF) in context of face detection and find that RFs can be used as inherent anchors instead of manually construction. Combining RF anchors and appropriate strides, the proposed method can cover a large range of continuous face scales with nearly 100% hit rate, rather than discrete scales. The insightful understanding of relations between effective receptive field (ERF) and face scales motivates an efficient backbone for one-stage detection. The backbone is characterized by eight detection branches and common building blocks, resulting in efficient computation. Comprehensive and extensive experiments on popular benchmarks: WIDER FACE and FDDB are conducted. A new evaluation schema is proposed for practical applications. Under the new schema, the proposed method can achieve superior accuracy (WIDER FACE Val/Test - Easy: 0.910/0.896, Medium: 0.880/0.865, Hard: 0.780/0.770; FDDB - discontinuous: 0.965, continuous: 0.719). Multiple hardware platforms are introduced to evaluate the running efficiency. The proposed methods can obtain fast inference speed (NVIDIA TITAN Xp: 131.45 FPS at 640480; NVIDIA TX2: 136.99 FPS at 160120; Raspberry Pi 3 Model B+: 8.44 FPS at 160120) with model size of 9 MB.
Ontology Based Global and Collective Motion Patterns for Event Classification in Basketball Videos
Mar 19, 2019
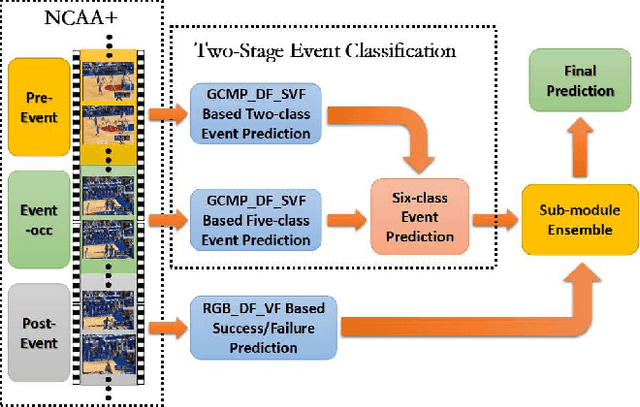

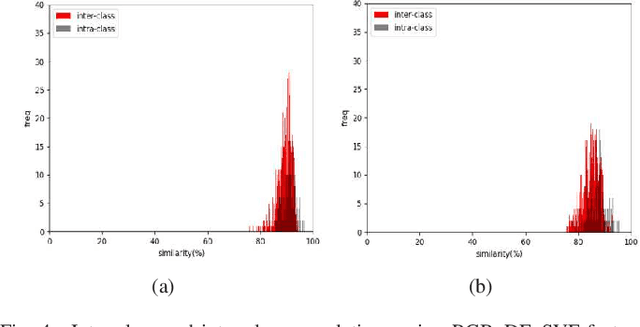
In multi-person videos, especially team sport videos, a semantic event is usually represented as a confrontation between two teams of players, which can be represented as collective motion. In broadcast basketball videos, specific camera motions are used to present specific events. Therefore, a semantic event in broadcast basketball videos is closely related to both the global motion (camera motion) and the collective motion. A semantic event in basketball videos can be generally divided into three stages: pre-event, event occurrence (event-occ), and post-event. In this paper, we propose an ontology-based global and collective motion pattern (On_GCMP) algorithm for basketball event classification. First, a two-stage GCMP based event classification scheme is proposed. The GCMP is extracted using optical flow. The two-stage scheme progressively combines a five-class event classification algorithm on event-occs and a two-class event classification algorithm on pre-events. Both algorithms utilize sequential convolutional neural networks (CNNs) and long short-term memory (LSTM) networks to extract the spatial and temporal features of GCMP for event classification. Second, we utilize post-event segments to predict success/failure using deep features of images in the video frames (RGB_DF_VF) based algorithms. Finally the event classification results and success/failure classification results are integrated to obtain the final results. To evaluate the proposed scheme, we collected a new dataset called NCAA+, which is automatically obtained from the NCAA dataset by extending the fixed length of video clips forward and backward of the corresponding semantic events. The experimental results demonstrate that the proposed scheme achieves the mean average precision of 58.10% on NCAA+. It is higher by 6.50% than state-of-the-art on NCAA.