 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice-Face Cross-modal Matching and Retrieval: A Benchmark
Dec 30, 2019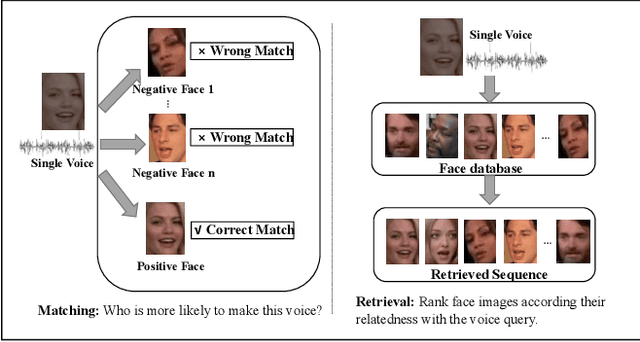
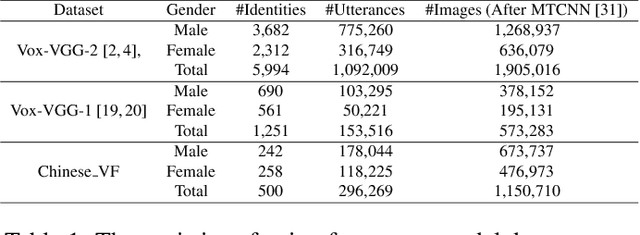
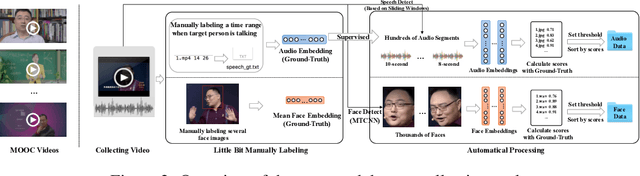
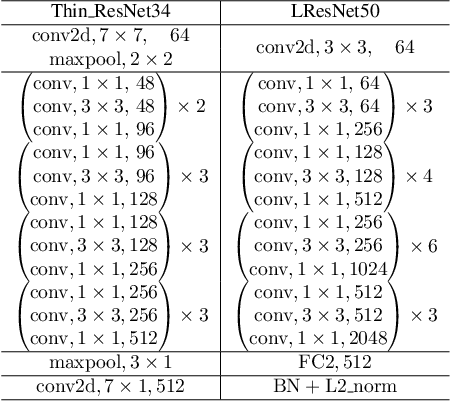
Cross-modal associations between voice and face from a person can be learnt algorithmically, which can benefit a lot of applications. The problem can be defined as voice-face matching and retrieval tasks. Much research attention has been paid on these tasks recently. However, this research is still in the early stage. Test schemes based on random tuple mining tend to have low test confidence. Generalization ability of models can not be evaluated by small scale datasets. Performance metrics on various tasks are scarce. A benchmark for this problem needs to be established. In this paper, first, a framework based on comprehensive studies is proposed for voice-face matching and retrieval. It achieves state-of-the-art performance with various performance metrics on different tasks and with high test confidence on large scale datasets, which can be taken as a baseline for the follow-up research. In this framework, a voice anchored L2-Norm constrained metric space is proposed, and cross-modal embeddings are learned with CNN-based networks and triplet loss in the metric space. The embedding learning process can be more effective and efficient with this strategy. Different network structures of the framework and the cross language transfer abilities of the model are also analyzed. Second, a voice-face dataset (with 1.15M face data and 0.29M audio data) from Chinese speakers is constructed, and a convenient and quality controllable dataset collection tool is developed. The dataset and source code of the paper will be published together with this paper.
Learning Document Embeddings by Predicting N-grams for Sentiment Classification of Long Movie Reviews
Apr 23, 2016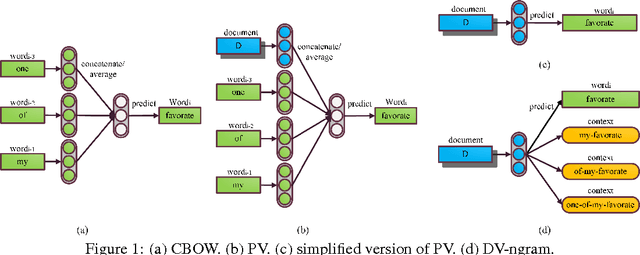
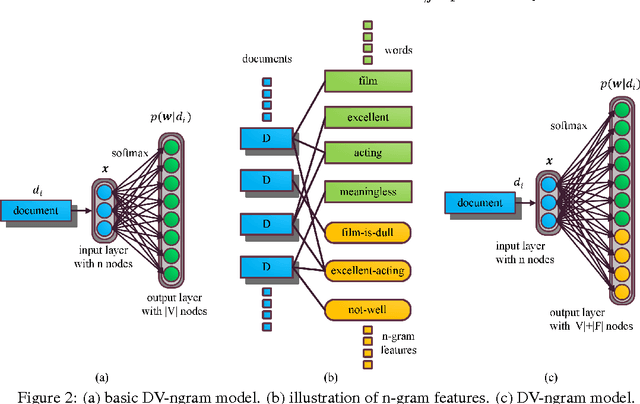

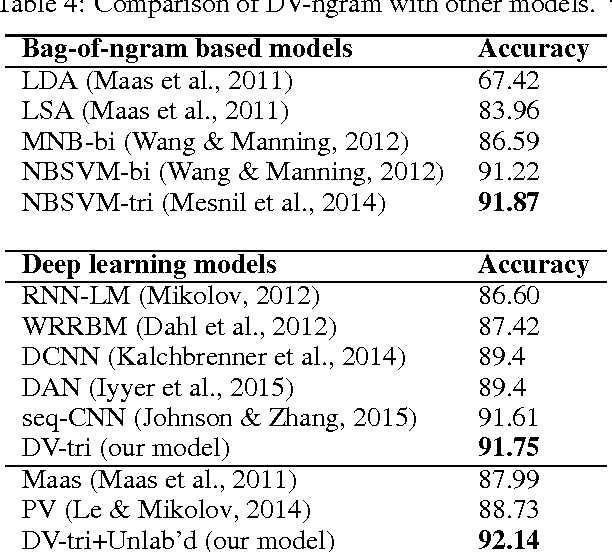
Despite the loss of semantic information, bag-of-ngram based methods still achieve state-of-the-art results for tasks such as sentiment classification of long movie reviews. Many document embeddings methods have been proposed to capture semantics, but they still can't outperform bag-of-ngram based methods on this task. In this paper, we modify the architecture of the recently proposed Paragraph Vector, allowing it to learn document vectors by predicting not only words, but n-gram features as well. Our model is able to capture both semantics and word order in documents while keeping the expressive power of learned vectors. Experimental results on IMDB movie review dataset shows that our model outperforms previous deep learning models and bag-of-ngram based models due to the above advantages. More robust results are also obtained when our model is combined with other models. The source code of our model will be also published together with this paper.