 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Document Embeddings by Predicting N-grams for Sentiment Classification of Long Movie Reviews
Paper and Code
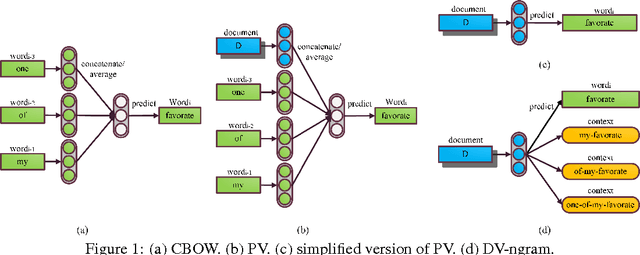
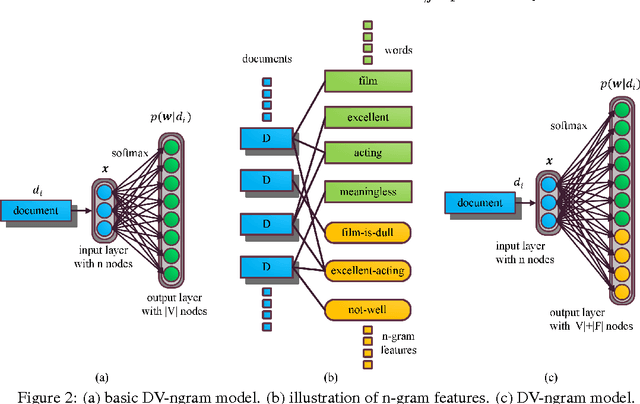

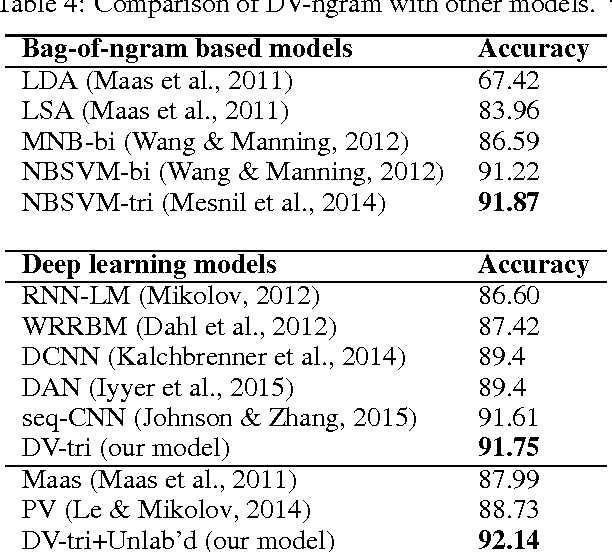
Despite the loss of semantic information, bag-of-ngram based methods still achieve state-of-the-art results for tasks such as sentiment classification of long movie reviews. Many document embeddings methods have been proposed to capture semantics, but they still can't outperform bag-of-ngram based methods on this task. In this paper, we modify the architecture of the recently proposed Paragraph Vector, allowing it to learn document vectors by predicting not only words, but n-gram features as well. Our model is able to capture both semantics and word order in documents while keeping the expressive power of learned vectors. Experimental results on IMDB movie review dataset shows that our model outperforms previous deep learning models and bag-of-ngram based models due to the above advantages. More robust results are also obtained when our model is combined with other models. The source code of our model will be also published together with this paper.