 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisGeM: Distractor Generation for Multiple Choice Questions with Span Masking
Sep 26, 2024
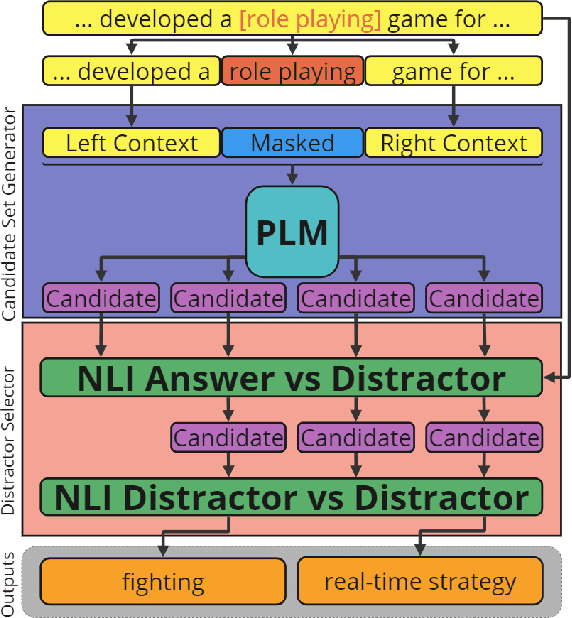

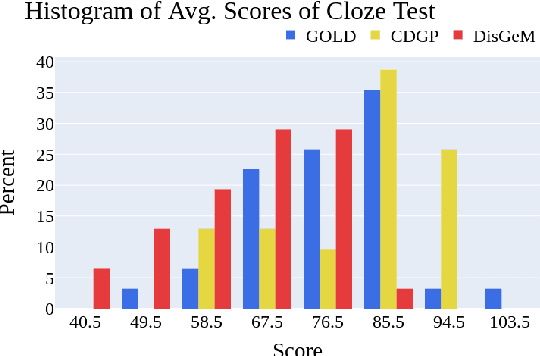
Recent advancements in Natural Language Processing (NLP) have impacted numerous sub-fields such as natural language generation, natural language inference, question answering, and more. However, in the field of question generation, the creation of distractors for multiple-choice questions (MCQ) remains a challenging task. In this work, we present a simple, generic framework for distractor generation using readily available Pre-trained Language Models (PLMs). Unlike previous methods, our framework relies solely on pre-trained language models and does not require additional training on specific datasets. Building upon previous research, we introduce a two-stage framework consisting of candidate generation and candidate selection. Our proposed distractor generation framework outperforms previous methods without the need for training or fine-tuning. Human evaluations confirm that our approach produces more effective and engaging distractors. The related codebase is publicly available at https://github.com/obss/disgem.
A multi-level multi-label text classification dataset of 19th century Ottoman and Russian literary and critical texts
Jul 21, 2024This paper introduces a multi-level, multi-label text classification dataset comprising over 3000 documents. The dataset features literary and critical texts from 19th-century Ottoman Turkish and Russian. It is the first study to apply large language models (LLMs) to this dataset, sourced from prominent literary periodicals of the era. The texts have been meticulously organized and labeled. This was done according to a taxonomic framework that takes into account both their structural and semantic attributes. Articles are categorized and tagged with bibliometric metadata by human experts. We present baseline classification results using a classical bag-of-words (BoW) naive Bayes model and three modern LLMs: multilingual BERT, Falcon, and Llama-v2. We found that in certain cases, Bag of Words (BoW) outperforms Large Language Models (LLMs), emphasizing the need for additional research, especially in low-resource language settings. This dataset is expected to be a valuable resource for researchers in natural language processing and machine learning, especially for historical and low-resource languages. The dataset is publicly available^1.
DroBoost: An Intelligent Score and Model Boosting Method for Drone Detection
Jun 30, 2024Drone detection is a challenging object detection task where visibility conditions and quality of the images may be unfavorable, and detections might become difficult due to complex backgrounds, small visible objects, and hard to distinguish objects. Both provide high confidence for drone detections, and eliminating false detections requires efficient algorithms and approaches. Our previous work, which uses YOLOv5, uses both real and synthetic data and a Kalman-based tracker to track the detections and increase their confidence using temporal information. Our current work improves on the previous approach by combining several improvements. We used a more diverse dataset combining multiple sources and combined with synthetic samples chosen from a large synthetic dataset based on the error analysis of the base model. Also, to obtain more resilient confidence scores for objects, we introduced a classification component that discriminates whether the object is a drone or not. Finally, we developed a more advanced scoring algorithm for object tracking that we use to adjust localization confidence. Furthermore, the proposed technique won 1st Place in the Drone vs. Bird Challenge (Workshop on Small-Drone Surveillance, Detection and Counteraction Techniques at ICIAP 2021).
Jury: A Comprehensive Evaluation Toolkit
Oct 03, 2023

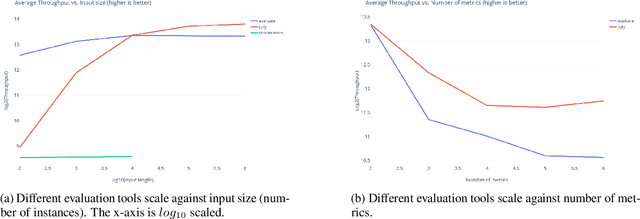
Evaluation plays a critical role in deep learning as a fundamental block of any prediction-based system. However, the vast number of Natural Language Processing (NLP) tasks and the development of various metrics have led to challenges in evaluating different systems with different metrics. To address these challenges, we introduce jury, a toolkit that provides a unified evaluation framework with standardized structures for performing evaluation across different tasks and metrics. The objective of jury is to standardize and improve metric evaluation for all systems and aid the community in overcoming the challenges in evaluation. Since its open-source release, jury has reached a wide audience and is available at https://github.com/obss/jury.
Automated question generation and question answering from Turkish texts using text-to-text transformers
Nov 21, 2021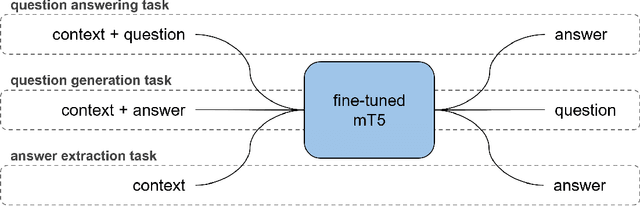
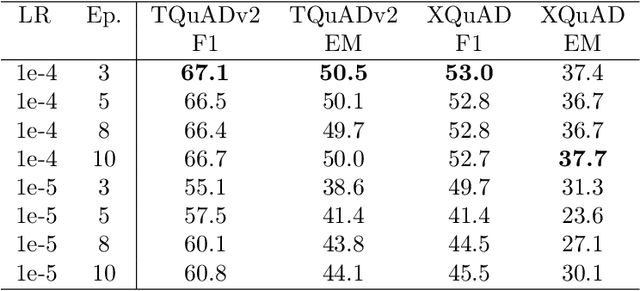
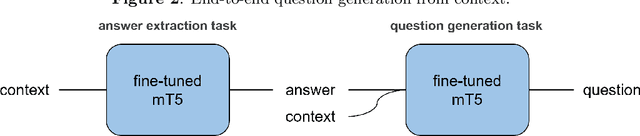
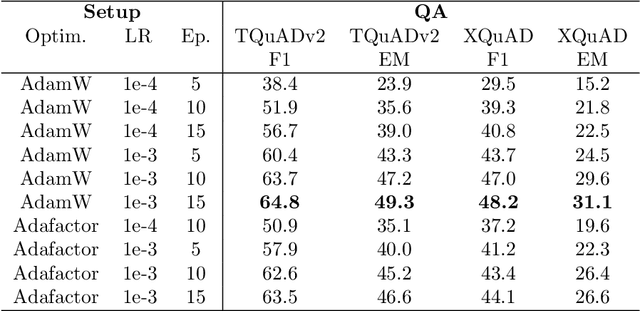
While exam-style questions are a fundamental educational tool serving a variety of purposes, manual construction of questions is a complex process that requires training, experience and resources. To reduce the expenses associated with the manual construction of questions and to satisfy the need for a continuous supply of new questions, automatic question generation (QG) techniques can be utilized. However, compared to automatic question answering (QA), QG is a more challenging task. In this work, we fine-tune a multilingual T5 (mT5) transformer in a multi-task setting for QA, QG and answer extraction tasks using a Turkish QA dataset. To the best of our knowledge, this is the first academic work that attempts to perform automated text-to-text question generation from Turkish texts. Evaluation results show that the proposed multi-task setting achieves state-of-the-art Turkish question answering and question generation performance over TQuADv1, TQuADv2 datasets and XQuAD Turkish split. The source code and pre-trained models are available at https://github.com/obss/turkish-question-generation.
Increasing Data Diversity with Iterative Sampling to Improve Performance
Nov 05, 2021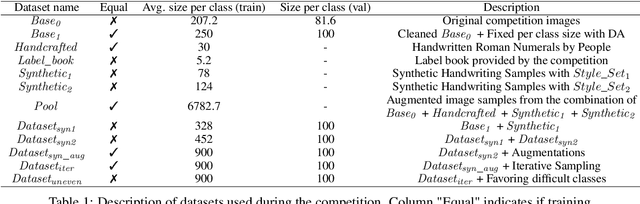

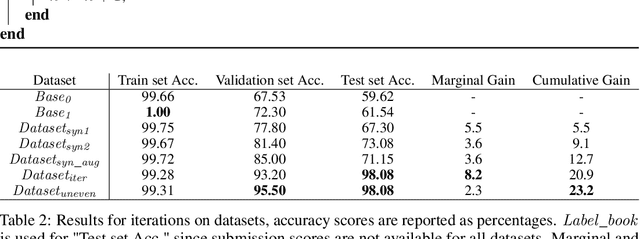
As a part of the Data-Centric AI Competition, we propose a data-centric approach to improve the diversity of the training samples by iterative sampling. The method itself relies strongly on the fidelity of augmented samples and the diversity of the augmentation methods. Moreover, we improve the performance further by introducing more samples for the difficult classes especially providing closer samples to edge cases potentially those the model at hand misclassifies.