 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-level multi-label text classification dataset of 19th century Ottoman and Russian literary and critical texts
Jul 21, 2024This paper introduces a multi-level, multi-label text classification dataset comprising over 3000 documents. The dataset features literary and critical texts from 19th-century Ottoman Turkish and Russian. It is the first study to apply large language models (LLMs) to this dataset, sourced from prominent literary periodicals of the era. The texts have been meticulously organized and labeled. This was done according to a taxonomic framework that takes into account both their structural and semantic attributes. Articles are categorized and tagged with bibliometric metadata by human experts. We present baseline classification results using a classical bag-of-words (BoW) naive Bayes model and three modern LLMs: multilingual BERT, Falcon, and Llama-v2. We found that in certain cases, Bag of Words (BoW) outperforms Large Language Models (LLMs), emphasizing the need for additional research, especially in low-resource language settings. This dataset is expected to be a valuable resource for researchers in natural language processing and machine learning, especially for historical and low-resource languages. The dataset is publicly available^1.
Character Generation through Self-Supervised Vectorization
Aug 03, 2022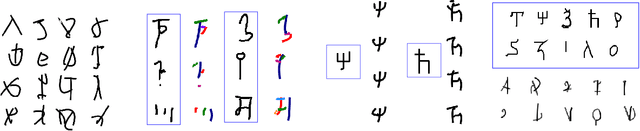

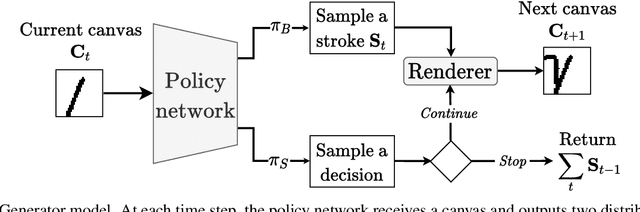
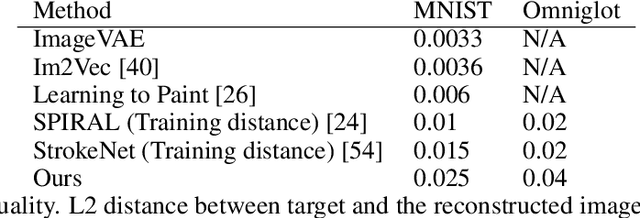
The prevalent approach in self-supervised image generation is to operate on pixel level representations. While this approach can produce high quality images, it cannot benefit from the simplicity and innate quality of vectorization. Here we present a drawing agent that operates on stroke-level representation of images. At each time step, the agent first assesses the current canvas and decides whether to stop or keep drawing. When a 'draw' decision is made, the agent outputs a program indicating the stroke to be drawn. As a result, it produces a final raster image by drawing the strokes on a canvas, using a minimal number of strokes and dynamically deciding when to stop. We train our agent through reinforcement learning on MNIST and Omniglot datasets for unconditional generation and parsing (reconstruction) tasks. We utilize our parsing agent for exemplar generation and type conditioned concept generation in Omniglot challenge without any further training. We present successful results on all three generation tasks and the parsing task. Crucially, we do not need any stroke-level or vector supervision; we only use raster images for training.