Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Data Diversity with Iterative Sampling to Improve Performance
Paper and Code
Nov 05, 2021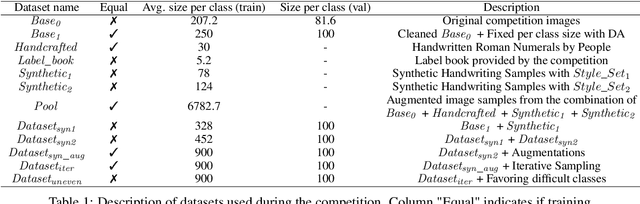

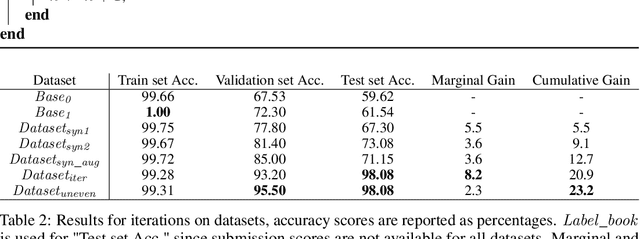
As a part of the Data-Centric AI Competition, we propose a data-centric approach to improve the diversity of the training samples by iterative sampling. The method itself relies strongly on the fidelity of augmented samples and the diversity of the augmentation methods. Moreover, we improve the performance further by introducing more samples for the difficult classes especially providing closer samples to edge cases potentially those the model at hand misclassifies.
* 5 pages, 2 (6) figures, to be published in 1st NeurIPS Data-Centric
AI Workshop
View paper on