 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging convergence behavior to balance conflicting tasks in multi-task learning
Apr 14, 2022
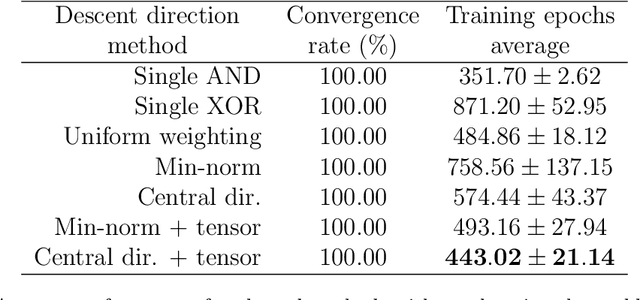
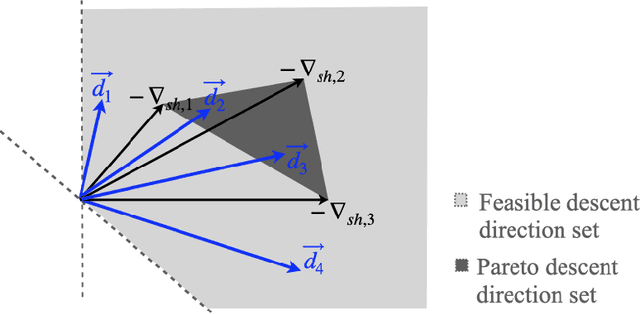

Multi-Task Learning is a learning paradigm that uses correlated tasks to improve performance generalization. A common way to learn multiple tasks is through the hard parameter sharing approach, in which a single architecture is used to share the same subset of parameters, creating an inductive bias between them during the training process. Due to its simplicity, potential to improve generalization, and reduce computational cost, it has gained the attention of the scientific and industrial communities. However, tasks often conflict with each other, which makes it challenging to define how the gradients of multiple tasks should be combined to allow simultaneous learning. To address this problem, we use the idea of multi-objective optimization to propose a method that takes into account temporal behaviour of the gradients to create a dynamic bias that adjust the importance of each task during the backpropagation. The result of this method is to give more attention to the tasks that are diverging or that are not being benefited during the last iterations, allowing to ensure that the simultaneous learning is heading to the performance maximization of all tasks. As a result, we empirically show that the proposed method outperforms the state-of-art approaches on learning conflicting tasks. Unlike the adopted baselines, our method ensures that all tasks reach good generalization performances.
Driving Style Recognition Using Interval Type-2 Fuzzy Inference System and Multiple Experts Decision Making
Oct 26, 2021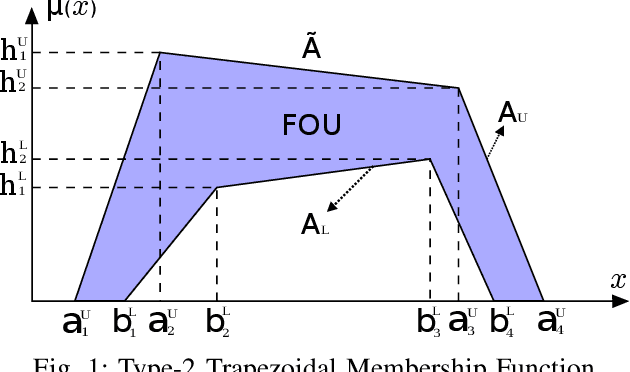
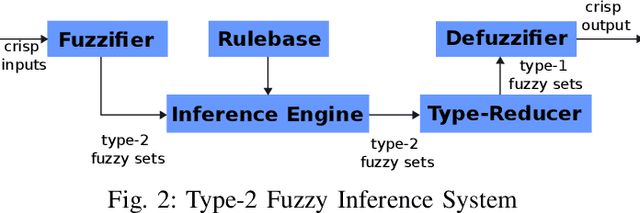
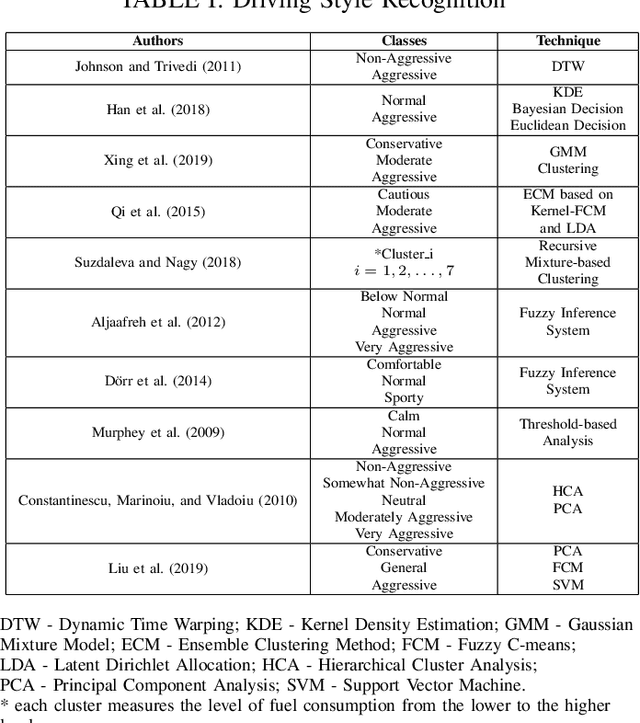
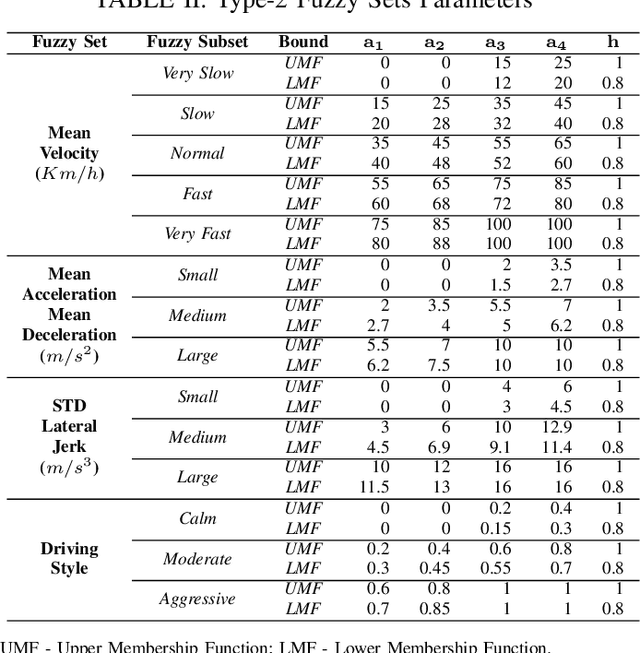
Driving styles summarize different driving behaviors that reflect in the movements of the vehicles. These behaviors may indicate a tendency to perform riskier maneuvers, consume more fuel or energy, break traffic rules, or drive carefully. Therefore, this paper presents a driving style recognition using Interval Type-2 Fuzzy Inference System with Multiple Experts Decision-Making for classifying drivers into calm, moderate and aggressive. This system receives as input features longitudinal and lateral kinematic parameters of the vehicle motion. The type-2 fuzzy sets are more robust than type-1 fuzzy sets when handling noisy data, because their membership function are also fuzzy sets. In addition, a multiple experts approach can reduce the bias and imprecision while building the fuzzy rulebase, which stores the knowledge of the fuzzy system. The proposed approach was evaluated using descriptive statistics analysis, and compared with clustering algorithms and a type-1 fuzzy inference system. The results show the tendency to associate lower kinematic profiles for the driving styles classified with the type-2 fuzzy inference system when compared to other algorithms, which is in line with the more conservative approach adopted in the aggregation of the experts' opinions.
A Software Architecture for Autonomous Vehicles: Team LRM-B Entry in the First CARLA Autonomous Driving Challenge
Oct 23, 2020The objective of the first CARLA autonomous driving challenge was to deploy autonomous driving systems to lead with complex traffic scenarios where all participants faced the same challenging traffic situations. According to the organizers, this competition emerges as a way to democratize and to accelerate the research and development of autonomous vehicles around the world using the CARLA simulator contributing to the development of the autonomous vehicle area. Therefore, this paper presents the architecture design for the navigation of an autonomous vehicle in a simulated urban environment that attempts to commit the least number of traffic infractions, which used as the baseline the original architecture of the platform for autonomous navigation CaRINA 2. Our agent traveled in simulated scenarios for several hours, demonstrating his capabilities, winning three out of the four tracks of the challenge, and being ranked second in the remaining track. Our architecture was made towards meeting the requirements of CARLA Autonomous Driving Challenge and has components for obstacle detection using 3D point clouds, traffic signs detection and classification which employs Convolutional Neural Networks (CNN) and depth information, risk assessment with collision detection using short-term motion prediction, decision-making with Markov Decision Process (MDP), and control using Model Predictive Control (MPC).
Vision-Based Road Detection using Contextual Blocks
Sep 03, 2015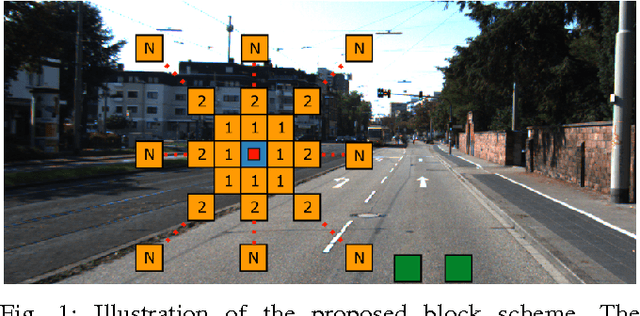
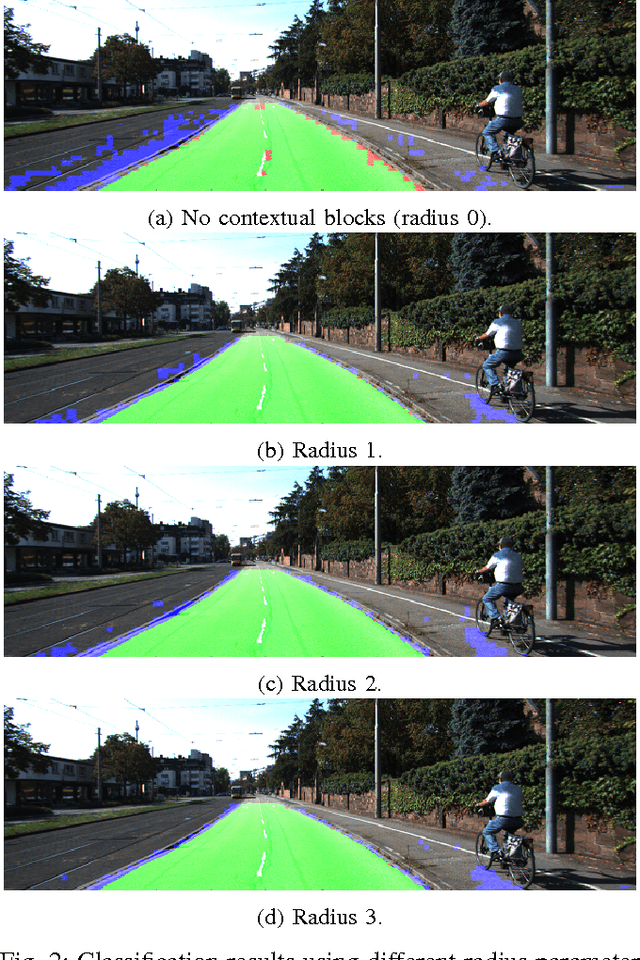


Road detection is a fundamental task in autonomous navigation systems. In this paper, we consider the case of monocular road detection, where images are segmented into road and non-road regions. Our starting point is the well-known machine learning approach, in which a classifier is trained to distinguish road and non-road regions based on hand-labeled images. We proceed by introducing the use of "contextual blocks" as an efficient way of providing contextual information to the classifier. Overall, the proposed methodology, including its image feature selection and classifier, was conceived with computational cost in mind, leaving room for optimized implementations. Regarding experiments, we perform a sensible evaluation of each phase and feature subset that composes our system. The results show a great benefit from using contextual blocks and demonstrate their computational efficiency. Finally, we submit our results to the KITTI road detection benchmark achieving scores comparable with state of the art methods.