 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Road Detection using Contextual Blocks
Paper and Code
Sep 03, 2015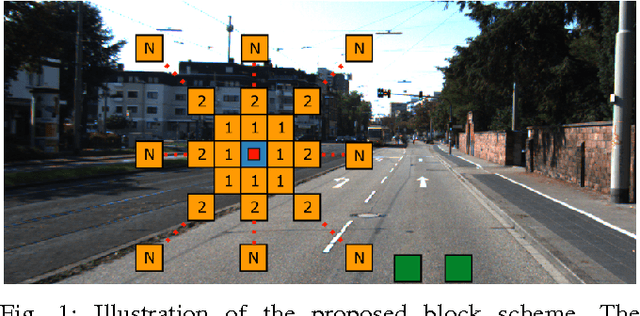
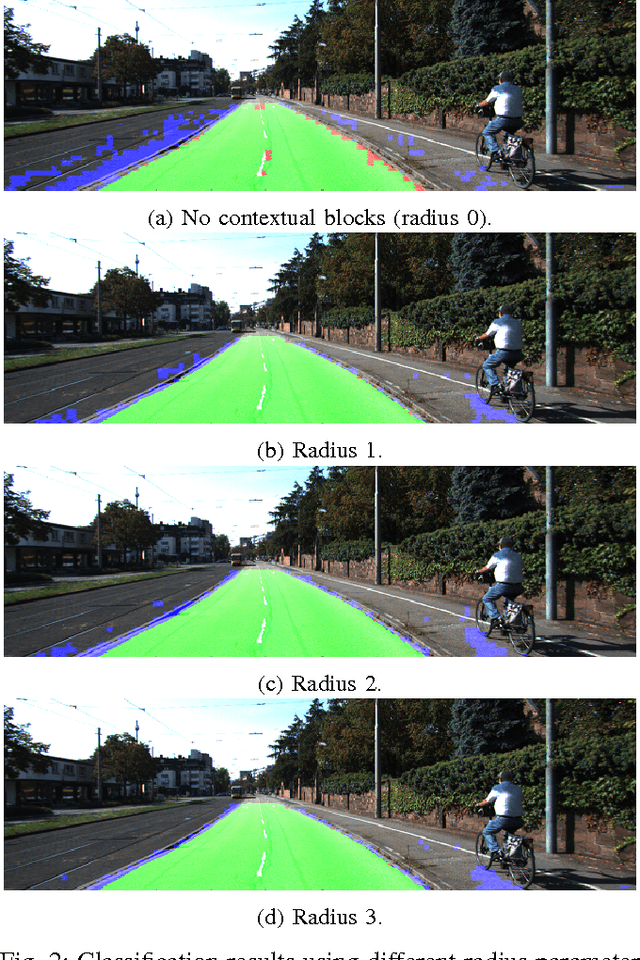


Road detection is a fundamental task in autonomous navigation systems. In this paper, we consider the case of monocular road detection, where images are segmented into road and non-road regions. Our starting point is the well-known machine learning approach, in which a classifier is trained to distinguish road and non-road regions based on hand-labeled images. We proceed by introducing the use of "contextual blocks" as an efficient way of providing contextual information to the classifier. Overall, the proposed methodology, including its image feature selection and classifier, was conceived with computational cost in mind, leaving room for optimized implementations. Regarding experiments, we perform a sensible evaluation of each phase and feature subset that composes our system. The results show a great benefit from using contextual blocks and demonstrate their computational efficiency. Finally, we submit our results to the KITTI road detection benchmark achieving scores comparable with state of the art methods.