 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Parkinson's disease evolution using deep learning
Jan 05, 2024


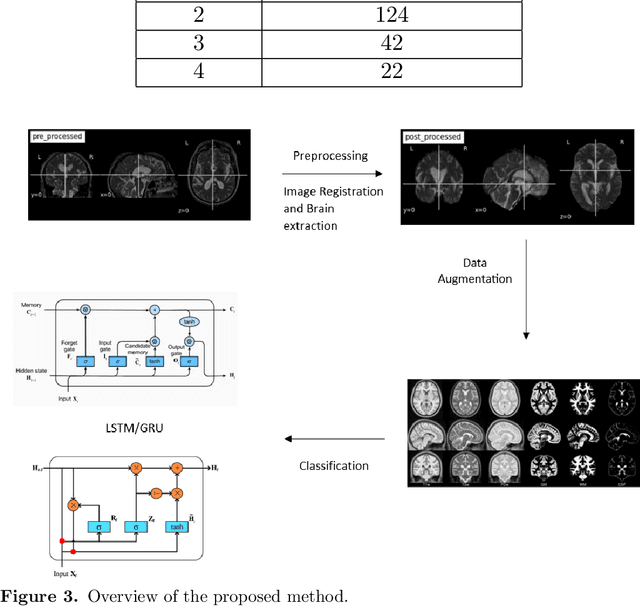
Parkinson's disease is a neurological condition that occurs in nearly 1% of the world's population. The disease is manifested by a drop in dopamine production, symptoms are cognitive and behavioural and include a wide range of personality changes, depressive disorders, memory problems, and emotional dysregulation, which can occur as the disease progresses. Early diagnosis and accurate staging of the disease are essential to apply the appropriate therapeutic approaches to slow cognitive and motor decline. Currently, there is not a single blood test or biomarker available to diagnose Parkinson's disease. Magnetic resonance imaging has been used for the past three decades to diagnose and distinguish between PD and other neurological conditions. However, in recent years new possibilities have arisen: several AI algorithms have been developed to increase the precision and accuracy of differential diagnosis of PD at an early stage. To our knowledge, no AI tools have been designed to identify the stage of progression. This paper aims to fill this gap. Using the "Parkinson's Progression Markers Initiative" dataset, which reports the patient's MRI and an indication of the disease stage, we developed a model to identify the level of progression. The images and the associated scores were used for training and assessing different deep-learning models. Our analysis distinguished four distinct disease progression levels based on a standard scale (Hoehn and Yah scale). The final architecture consists of the cascading of a 3DCNN network, adopted to reduce and extract the spatial characteristics of the RMI for efficient training of the successive LSTM layers, aiming at modelling the temporal dependencies among the data. Our results show that the proposed 3DCNN + LSTM model achieves state-of-the-art results by classifying the elements with 91.90\% as macro averaged OVR AUC on four classes
Coevolution of Neural Architectures and Features for Stock Market Forecasting: A Multi-objective Decision Perspective
Nov 23, 2023In a multi objective setting, a portfolio manager's highly consequential decisions can benefit from assessing alternative forecasting models of stock index movement. The present investigation proposes a new approach to identify a set of nondominated neural network models for further selection by the decision maker. A new coevolution approach is proposed to simultaneously select the features and topology of neural networks (collectively referred to as neural architecture), where the features are viewed from a topological perspective as input neurons. Further, the coevolution is posed as a multicriteria problem to evolve sparse and efficacious neural architectures. The well known dominance and decomposition based multiobjective evolutionary algorithms are augmented with a nongeometric crossover operator to diversify and balance the search for neural architectures across conflicting criteria. Moreover, the coevolution is augmented to accommodate the data based implications of distinct market behaviors prior to and during the ongoing COVID 19 pandemic. A detailed comparative evaluation is carried out with the conventional sequential approach of feature selection followed by neural topology design, as well as a scalarized coevolution approach. The results on the NASDAQ index in pre and peri COVID time windows convincingly demonstrate that the proposed coevolution approach can evolve a set of nondominated neural forecasting models with better generalization capabilities.
* 22 pages
Deep Learning with Multiple Data Set: A Weighted Goal Programming Approach
Dec 17, 2021
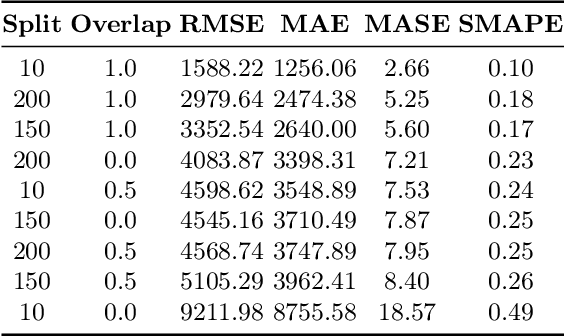
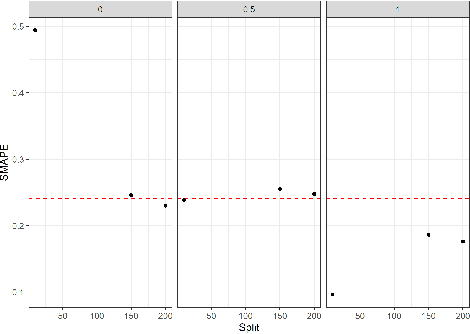
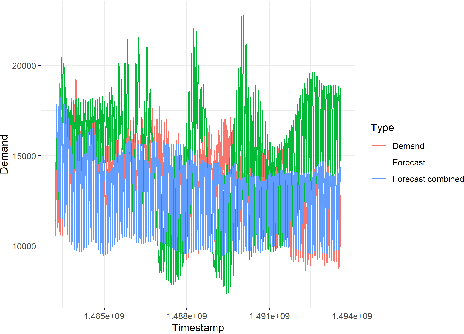
Large-scale data analysis is growing at an exponential rate as data proliferates in our societies. This abundance of data has the advantage of allowing the decision-maker to implement complex models in scenarios that were prohibitive before. At the same time, such an amount of data requires a distributed thinking approach. In fact, Deep Learning models require plenty of resources, and distributed training is needed. This paper presents a Multicriteria approach for distributed learning. Our approach uses the Weighted Goal Programming approach in its Chebyshev formulation to build an ensemble of decision rules that optimize aprioristically defined performance metrics. Such a formulation is beneficial because it is both model and metric agnostic and provides an interpretable output for the decision-maker. We test our approach by showing a practical application in electricity demand forecasting. Our results suggest that when we allow for dataset split overlapping, the performances of our methodology are consistently above the baseline model trained on the whole dataset.
Mixing Deep Learning and Multiple Criteria Optimization: An Application to Distributed Learning with Multiple Datasets
Dec 02, 2021
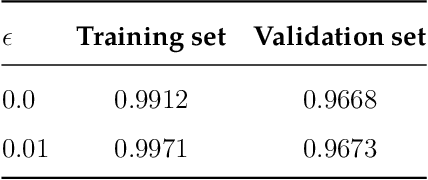

The training phase is the most important stage during the machine learning process. In the case of labeled data and supervised learning, machine training consists in minimizing the loss function subject to different constraints. In an abstract setting, it can be formulated as a multiple criteria optimization model in which each criterion measures the distance between the output associated with a specific input and its label. Therefore, the fitting term is a vector function and its minimization is intended in the Pareto sense. We provide stability results of the efficient solutions with respect to perturbations of input and output data. We then extend the same approach to the case of learning with multiple datasets. The multiple dataset environment is relevant when reducing the bias due to the choice of a specific training set. We propose a scalarization approach to implement this model and numerical experiments in digit classification using MNIST data.
A Multi-criteria Approach to Evolve Sparse Neural Architectures for Stock Market Forecasting
Nov 15, 2021
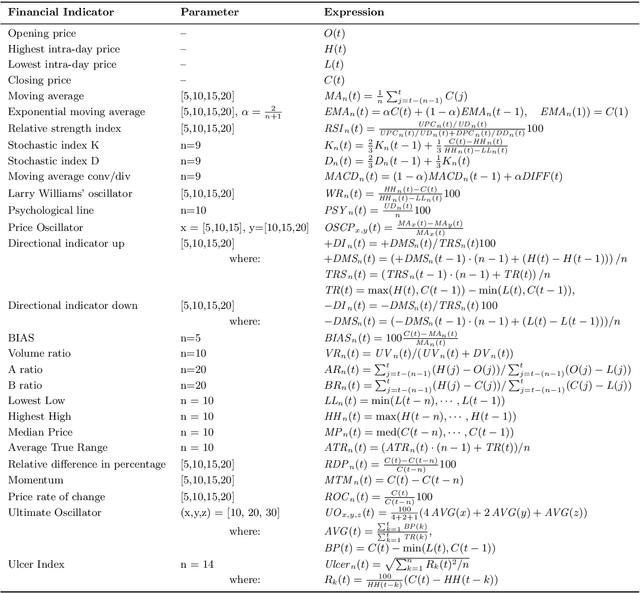
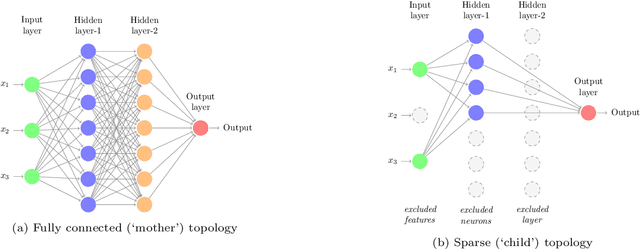
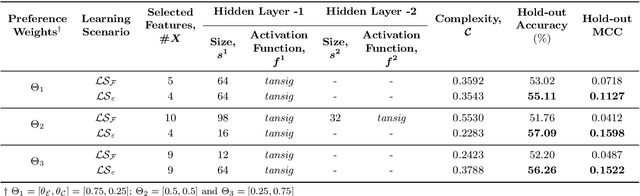
This study proposes a new framework to evolve efficacious yet parsimonious neural architectures for the movement prediction of stock market indices using technical indicators as inputs. In the light of a sparse signal-to-noise ratio under the Efficient Market hypothesis, developing machine learning methods to predict the movement of a financial market using technical indicators has shown to be a challenging problem. To this end, the neural architecture search is posed as a multi-criteria optimization problem to balance the efficacy with the complexity of architectures. In addition, the implications of different dominant trading tendencies which may be present in the pre-COVID and within-COVID time periods are investigated. An $\epsilon-$ constraint framework is proposed as a remedy to extract any concordant information underlying the possibly conflicting pre-COVID data. Further, a new search paradigm, Two-Dimensional Swarms (2DS) is proposed for the multi-criteria neural architecture search, which explicitly integrates sparsity as an additional search dimension in particle swarms. A detailed comparative evaluation of the proposed approach is carried out by considering genetic algorithm and several combinations of empirical neural design rules with a filter-based feature selection method (mRMR) as baseline approaches. The results of this study convincingly demonstrate that the proposed approach can evolve parsimonious networks with better generalization capabilities.