 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution of Neural Architectures for Financial Forecasting: A Note on Data Incompatibility during Crisis Periods
Nov 24, 2023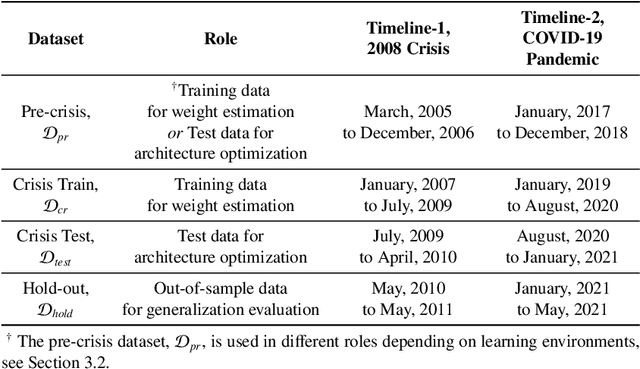
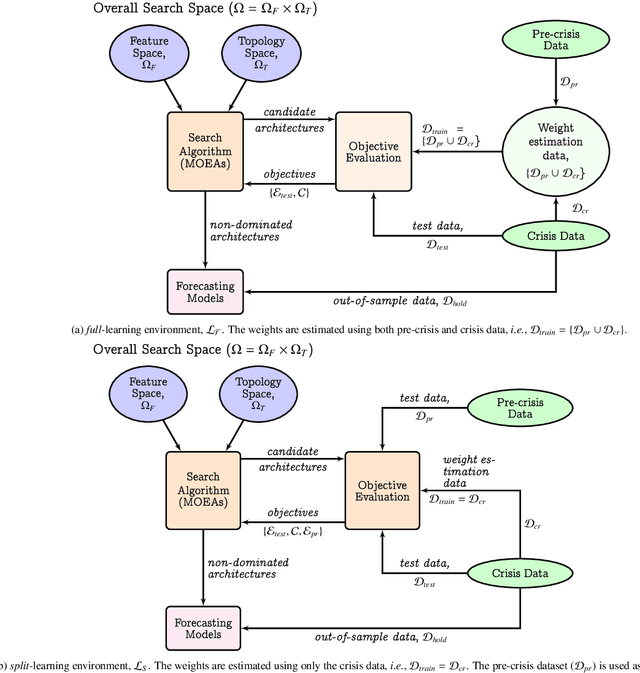
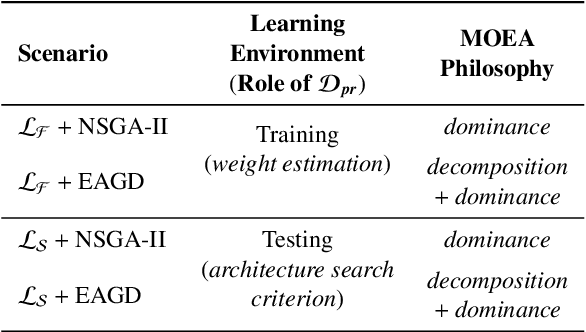
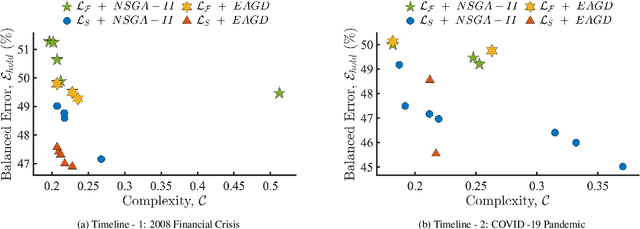
This note focuses on the optimization of neural architectures for stock index movement forecasting following a major market disruption or crisis. Given that such crises may introduce a shift in market dynamics, this study aims to investigate whether the training data from market dynamics prior to the crisis are compatible with the data during the crisis period. To this end, two distinct learning environments are designed to evaluate and reconcile the effects of possibly different market dynamics. These environments differ principally based on the role assigned to the pre-crisis data. In both environments, a set of non-dominated architectures are identified to satisfy the multi-criteria co-evolution problem, which simultaneously addresses the selection issues related to features and hidden layer topology. To test the hypothesis of pre-crisis data incompatibility, the day-ahead movement prediction of the NASDAQ index is considered during two recent and major market disruptions; the 2008 financial crisis and the COVID-19 pandemic. The results of a detailed comparative evaluation convincingly support the incompatibility hypothesis and highlight the need to select re-training windows carefully.
Coevolution of Neural Architectures and Features for Stock Market Forecasting: A Multi-objective Decision Perspective
Nov 23, 2023In a multi objective setting, a portfolio manager's highly consequential decisions can benefit from assessing alternative forecasting models of stock index movement. The present investigation proposes a new approach to identify a set of nondominated neural network models for further selection by the decision maker. A new coevolution approach is proposed to simultaneously select the features and topology of neural networks (collectively referred to as neural architecture), where the features are viewed from a topological perspective as input neurons. Further, the coevolution is posed as a multicriteria problem to evolve sparse and efficacious neural architectures. The well known dominance and decomposition based multiobjective evolutionary algorithms are augmented with a nongeometric crossover operator to diversify and balance the search for neural architectures across conflicting criteria. Moreover, the coevolution is augmented to accommodate the data based implications of distinct market behaviors prior to and during the ongoing COVID 19 pandemic. A detailed comparative evaluation is carried out with the conventional sequential approach of feature selection followed by neural topology design, as well as a scalarized coevolution approach. The results on the NASDAQ index in pre and peri COVID time windows convincingly demonstrate that the proposed coevolution approach can evolve a set of nondominated neural forecasting models with better generalization capabilities.
* 22 pages
A Multi-criteria Approach to Evolve Sparse Neural Architectures for Stock Market Forecasting
Nov 15, 2021
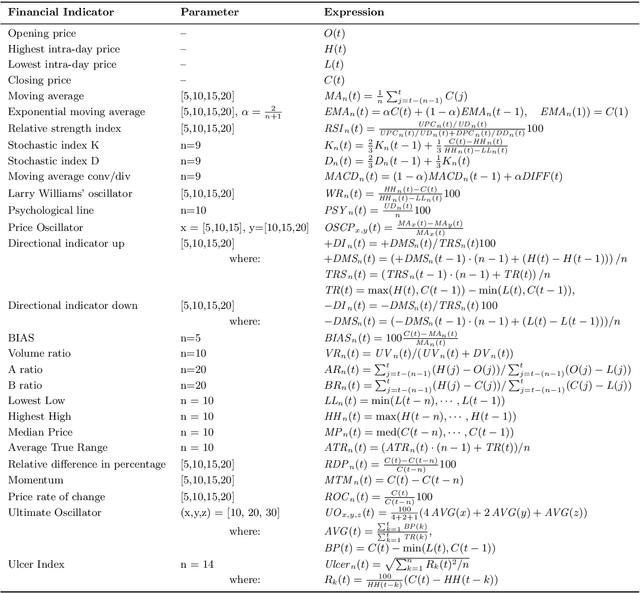
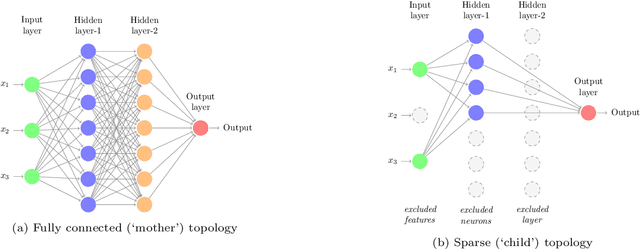
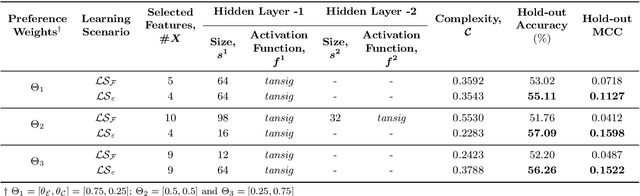
This study proposes a new framework to evolve efficacious yet parsimonious neural architectures for the movement prediction of stock market indices using technical indicators as inputs. In the light of a sparse signal-to-noise ratio under the Efficient Market hypothesis, developing machine learning methods to predict the movement of a financial market using technical indicators has shown to be a challenging problem. To this end, the neural architecture search is posed as a multi-criteria optimization problem to balance the efficacy with the complexity of architectures. In addition, the implications of different dominant trading tendencies which may be present in the pre-COVID and within-COVID time periods are investigated. An $\epsilon-$ constraint framework is proposed as a remedy to extract any concordant information underlying the possibly conflicting pre-COVID data. Further, a new search paradigm, Two-Dimensional Swarms (2DS) is proposed for the multi-criteria neural architecture search, which explicitly integrates sparsity as an additional search dimension in particle swarms. A detailed comparative evaluation of the proposed approach is carried out by considering genetic algorithm and several combinations of empirical neural design rules with a filter-based feature selection method (mRMR) as baseline approaches. The results of this study convincingly demonstrate that the proposed approach can evolve parsimonious networks with better generalization capabilities.
Generalizing Prototype Theory: A Formal Quantum Framework
Jan 25, 2016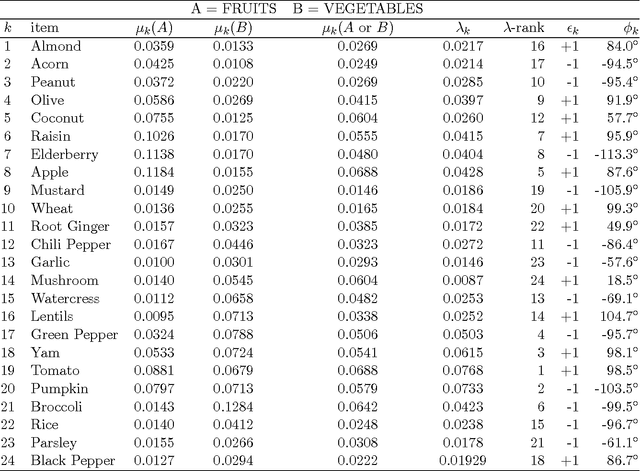
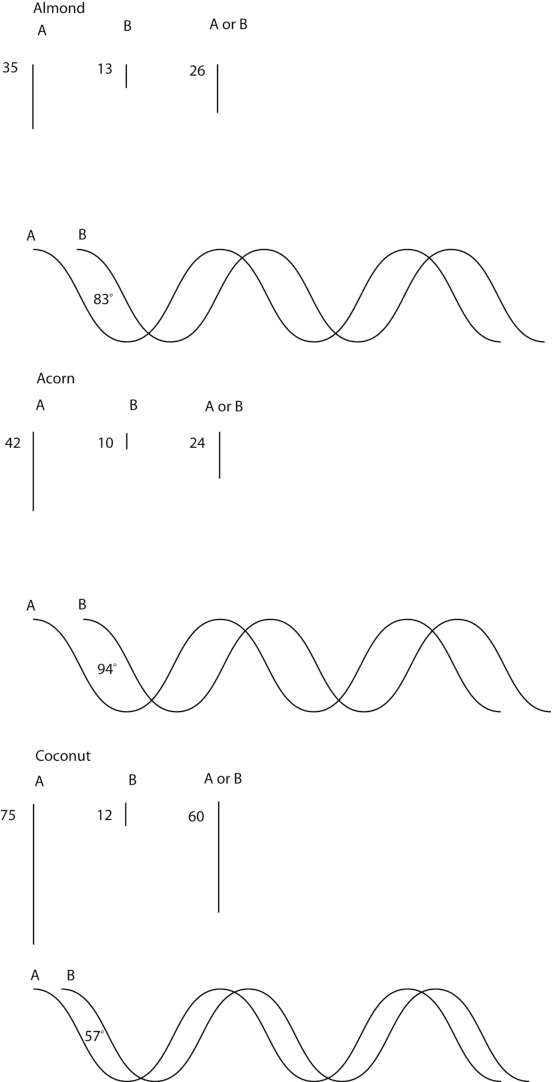
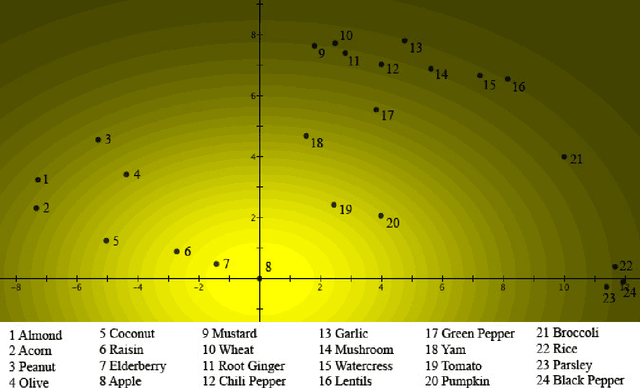
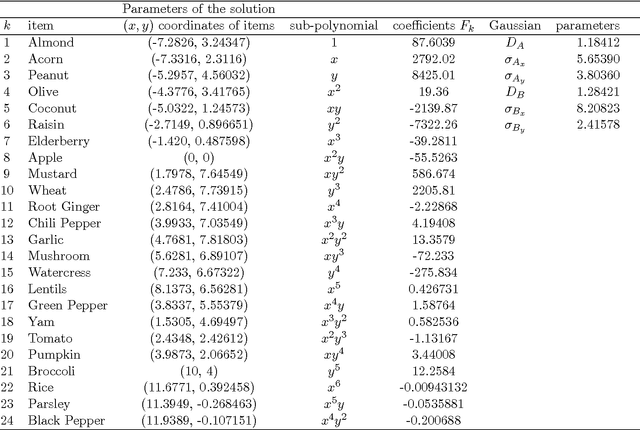
Theories of natural language and concepts have been unable to model the flexibility, creativity, context-dependence, and emergence, exhibited by words, concepts and their combinations. The mathematical formalism of quantum theory has instead been successful in capturing these phenomena such as graded membership, situational meaning, composition of categories, and also more complex decision making situations, which cannot be modeled in traditional probabilistic approaches. We show how a formal quantum approach to concepts and their combinations can provide a powerful extension of prototype theory. We explain how prototypes can interfere in conceptual combinations as a consequence of their contextual interactions, and provide an illustration of this using an intuitive wave-like diagram. This quantum-conceptual approach gives new life to original prototype theory, without however making it a privileged concept theory, as we explain at the end of our paper.
* 30 pages, 3 figures
The Quantum Challenge in Concept Theory and Natural Language Processing
Jun 12, 2013The mathematical formalism of quantum theory has been successfully used in human cognition to model decision processes and to deliver representations of human knowledge. As such, quantum cognition inspired tools have improved technologies for Natural Language Processing and Information Retrieval. In this paper, we overview the quantum cognition approach developed in our Brussels team during the last two decades, specifically our identification of quantum structures in human concepts and language, and the modeling of data from psychological and corpus-text-based experiments. We discuss our quantum-theoretic framework for concepts and their conjunctions/disjunctions in a Fock-Hilbert space structure, adequately modeling a large amount of data collected on concept combinations. Inspired by this modeling, we put forward elements for a quantum contextual and meaning-based approach to information technologies in which 'entities of meaning' are inversely reconstructed from texts, which are considered as traces of these entities' states.
* 5 pages
Meaning-focused and Quantum-inspired Information Retrieval
Mar 30, 2013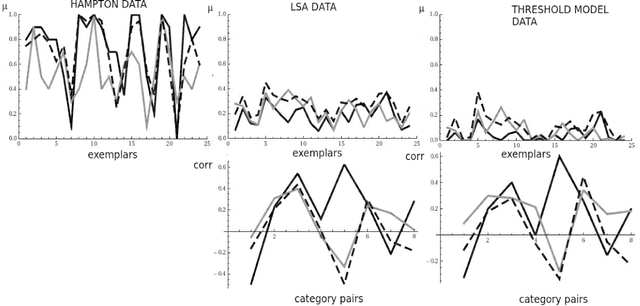
In recent years, quantum-based methods have promisingly integrated the traditional procedures in information retrieval (IR) and natural language processing (NLP). Inspired by our research on the identification and application of quantum structures in cognition, more specifically our work on the representation of concepts and their combinations, we put forward a 'quantum meaning based' framework for structured query retrieval in text corpora and standardized testing corpora. This scheme for IR rests on considering as basic notions, (i) 'entities of meaning', e.g., concepts and their combinations and (ii) traces of such entities of meaning, which is how documents are considered in this approach. The meaning content of these 'entities of meaning' is reconstructed by solving an 'inverse problem' in the quantum formalism, consisting of reconstructing the full states of the entities of meaning from their collapsed states identified as traces in relevant documents. The advantages with respect to traditional approaches, such as Latent Semantic Analysis (LSA), are discussed by means of concrete examples.
* 11 pages
The Guppy Effect as Interference
Aug 11, 2012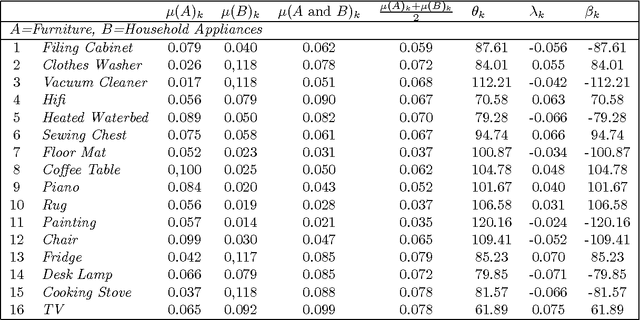
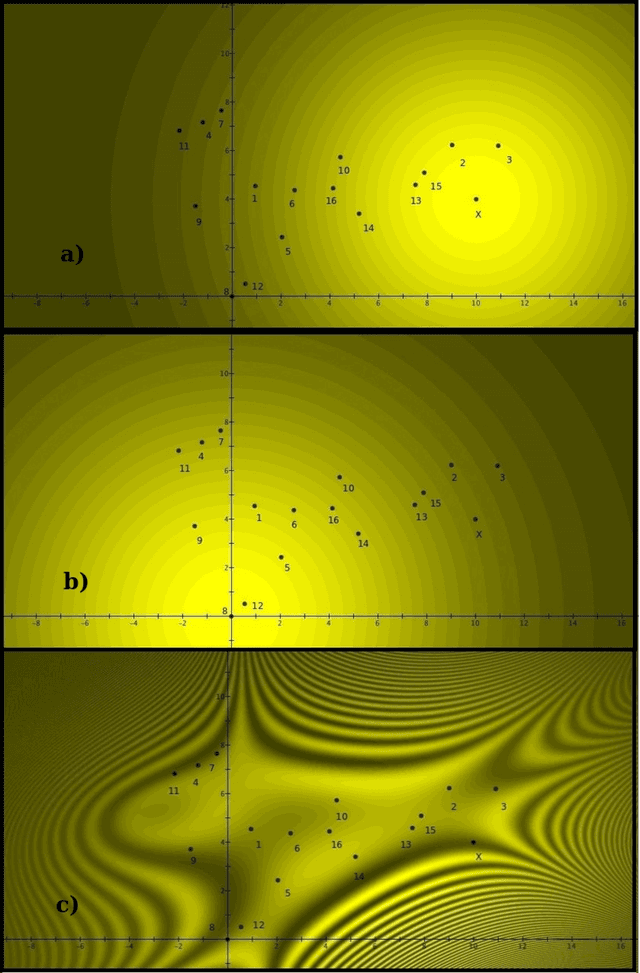
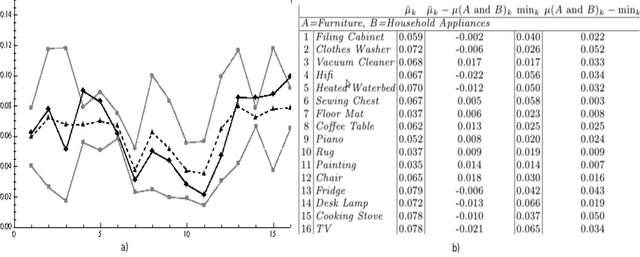
People use conjunctions and disjunctions of concepts in ways that violate the rules of classical logic, such as the law of compositionality. Specifically, they overextend conjunctions of concepts, a phenomenon referred to as the Guppy Effect. We build on previous efforts to develop a quantum model that explains the Guppy Effect in terms of interference. Using a well-studied data set with 16 exemplars that exhibit the Guppy Effect, we developed a 17-dimensional complex Hilbert space H that models the data and demonstrates the relationship between overextension and interference. We view the interference effect as, not a logical fallacy on the conjunction, but a signal that out of the two constituent concepts, a new concept has emerged.
* 10 pages