 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Deep Learning and Multiple Criteria Optimization: An Application to Distributed Learning with Multiple Datasets
Paper and Code
Dec 02, 2021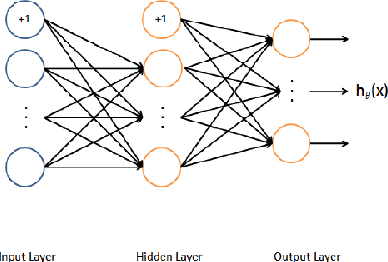
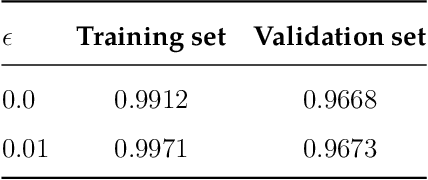

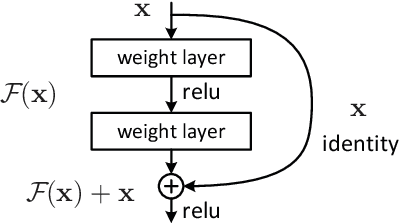
The training phase is the most important stage during the machine learning process. In the case of labeled data and supervised learning, machine training consists in minimizing the loss function subject to different constraints. In an abstract setting, it can be formulated as a multiple criteria optimization model in which each criterion measures the distance between the output associated with a specific input and its label. Therefore, the fitting term is a vector function and its minimization is intended in the Pareto sense. We provide stability results of the efficient solutions with respect to perturbations of input and output data. We then extend the same approach to the case of learning with multiple datasets. The multiple dataset environment is relevant when reducing the bias due to the choice of a specific training set. We propose a scalarization approach to implement this model and numerical experiments in digit classification using MNIST data.