 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning with Multiple Data Set: A Weighted Goal Programming Approach
Dec 17, 2021
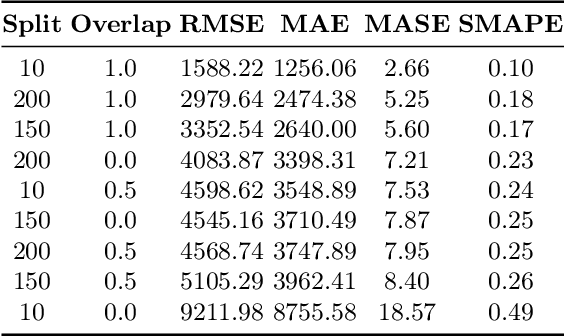
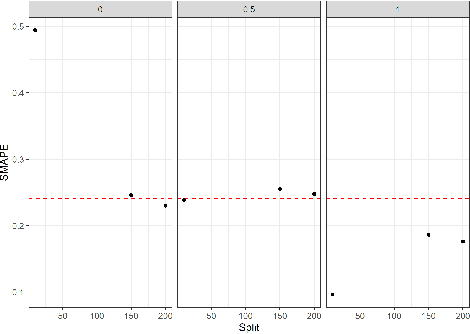
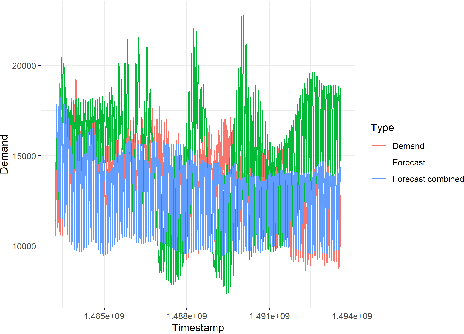
Large-scale data analysis is growing at an exponential rate as data proliferates in our societies. This abundance of data has the advantage of allowing the decision-maker to implement complex models in scenarios that were prohibitive before. At the same time, such an amount of data requires a distributed thinking approach. In fact, Deep Learning models require plenty of resources, and distributed training is needed. This paper presents a Multicriteria approach for distributed learning. Our approach uses the Weighted Goal Programming approach in its Chebyshev formulation to build an ensemble of decision rules that optimize aprioristically defined performance metrics. Such a formulation is beneficial because it is both model and metric agnostic and provides an interpretable output for the decision-maker. We test our approach by showing a practical application in electricity demand forecasting. Our results suggest that when we allow for dataset split overlapping, the performances of our methodology are consistently above the baseline model trained on the whole dataset.
Mixing Deep Learning and Multiple Criteria Optimization: An Application to Distributed Learning with Multiple Datasets
Dec 02, 2021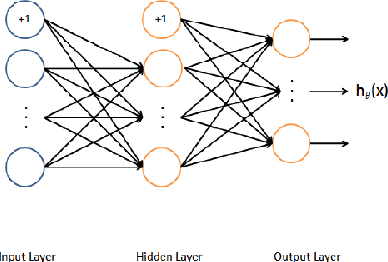
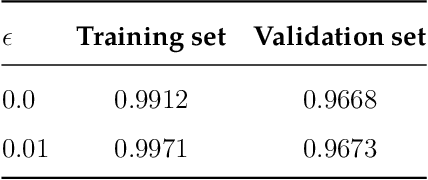

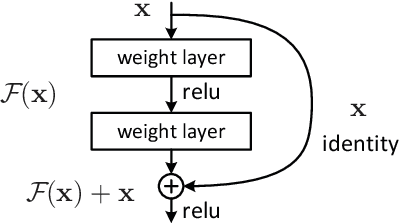
The training phase is the most important stage during the machine learning process. In the case of labeled data and supervised learning, machine training consists in minimizing the loss function subject to different constraints. In an abstract setting, it can be formulated as a multiple criteria optimization model in which each criterion measures the distance between the output associated with a specific input and its label. Therefore, the fitting term is a vector function and its minimization is intended in the Pareto sense. We provide stability results of the efficient solutions with respect to perturbations of input and output data. We then extend the same approach to the case of learning with multiple datasets. The multiple dataset environment is relevant when reducing the bias due to the choice of a specific training set. We propose a scalarization approach to implement this model and numerical experiments in digit classification using MNIST data.
Multicriteria interpretability driven Deep Learning
Nov 28, 2021

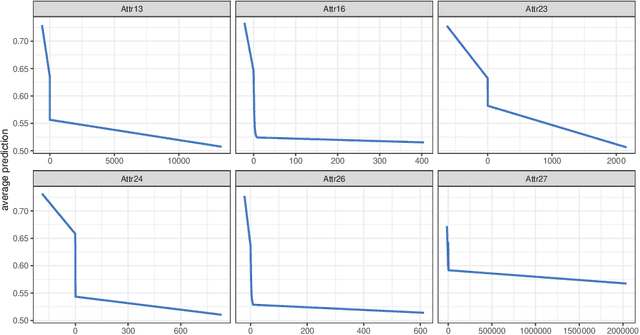

Deep Learning methods are renowned for their performances, yet their lack of interpretability prevents them from high-stakes contexts. Recent model agnostic methods address this problem by providing post-hoc interpretability methods by reverse-engineering the model's inner workings. However, in many regulated fields, interpretability should be kept in mind from the start, which means that post-hoc methods are valid only as a sanity check after model training. Interpretability from the start, in an abstract setting, means posing a set of soft constraints on the model's behavior by injecting knowledge and annihilating possible biases. We propose a Multicriteria technique that allows to control the feature effects on the model's outcome by injecting knowledge in the objective function. We then extend the technique by including a non-linear knowledge function to account for more complex effects and local lack of knowledge. The result is a Deep Learning model that embodies interpretability from the start and aligns with the recent regulations. A practical empirical example based on credit risk, suggests that our approach creates performant yet robust models capable of overcoming biases derived from data scarcity.
Look Who's Talking: Interpretable Machine Learning for Assessing Italian SMEs Credit Default
Sep 01, 2021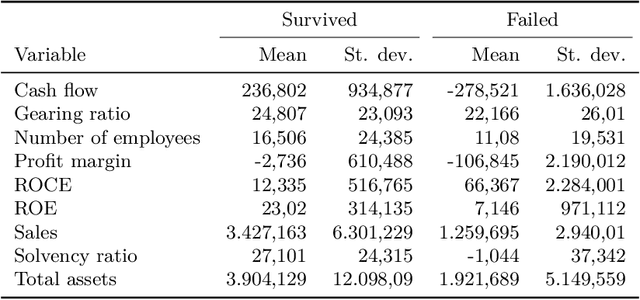



Academic research and the financial industry have recently paid great attention to Machine Learning algorithms due to their power to solve complex learning tasks. In the field of firms' default prediction, however, the lack of interpretability has prevented the extensive adoption of the black-box type of models. To overcome this drawback and maintain the high performances of black-boxes, this paper relies on a model-agnostic approach. Accumulated Local Effects and Shapley values are used to shape the predictors' impact on the likelihood of default and rank them according to their contribution to the model outcome. Prediction is achieved by two Machine Learning algorithms (eXtreme Gradient Boosting and FeedForward Neural Network) compared with three standard discriminant models. Results show that our analysis of the Italian Small and Medium Enterprises manufacturing industry benefits from the overall highest classification power by the eXtreme Gradient Boosting algorithm without giving up a rich interpretation framework.