 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Analysis for the Subgradient Methods Minimizing Composite Nonconvex, Nonsmooth and Non-Lipschitz Functions
Aug 30, 2023In this paper we propose a proximal subgradient method (Prox-SubGrad) for solving nonconvex and nonsmooth optimization problems without assuming Lipschitz continuity conditions. A number of subgradient upper bounds and their relationships are presented. By means of these upper bounding conditions, we establish some uniform recursive relations for the Moreau envelopes for weakly convex optimization. This uniform scheme simplifies and unifies the proof schemes to establish rate of convergence for Prox-SubGrad without assuming Lipschitz continuity. We present a novel convergence analysis in this context. Furthermore, we propose some new stochastic subgradient upper bounding conditions and establish convergence and iteration complexity rates for the stochastic subgradient method (Sto-SubGrad) to solve non-Lipschitz and nonsmooth stochastic optimization problems. In particular, for both deterministic and stochastic subgradient methods on weakly convex optimization problems without Lipschitz continuity, under any of the subgradient upper bounding conditions to be introduced in the paper, we show that $O(1/\sqrt{T})$ convergence rate holds in terms of the square of gradient of the Moreau envelope function, which further improves to be $O(1/{T})$ if, in addition, the uniform KL condition with exponent $1/2$ holds.
An Augmented Lagrangian Approach to Conically Constrained Non-monotone Variational Inequality Problems
Jun 02, 2023In this paper we consider a non-monotone (mixed) variational inequality model with (nonlinear) convex conic constraints. Through developing an equivalent Lagrangian function-like primal-dual saddle-point system for the VI model in question, we introduce an augmented Lagrangian primal-dual method, to be called ALAVI in the current paper, for solving a general constrained VI model. Under an assumption, to be called the primal-dual variational coherence condition in the paper, we prove the convergence of ALAVI. Next, we show that many existing generalized monotonicity properties are sufficient -- though by no means necessary -- to imply the above mentioned coherence condition, thus are sufficient to ensure convergence of ALAVI. Under that assumption, we further show that ALAVI has in fact an $o(1/\sqrt{k})$ global rate of convergence where $k$ is the iteration count. By introducing a new gap function, this rate further improves to be $O(1/k)$ if the mapping is monotone. Finally, we show that under a metric subregularity condition, even if the VI model may be non-monotone the local convergence rate of ALAVI improves to be linear. Numerical experiments on some randomly generated highly nonlinear and non-monotone VI problems show practical efficacy of the newly proposed method.
Revisiting Subgradient Method: Complexity and Convergence Beyond Lipschitz Continuity
May 23, 2023The subgradient method is one of the most fundamental algorithmic schemes for nonsmooth optimization. The existing complexity and convergence results for this algorithm are mainly derived for Lipschitz continuous objective functions. In this work, we first extend the typical complexity results for the subgradient method to convex and weakly convex minimization without assuming Lipschitz continuity. Specifically, we establish $\mathcal{O}(1/\sqrt{T})$ bound in terms of the suboptimality gap ``$f(x) - f^*$'' for convex case and $\mathcal{O}(1/{T}^{1/4})$ bound in terms of the gradient of the Moreau envelope function for weakly convex case. Furthermore, we provide convergence results for non-Lipschitz convex and weakly convex objective functions using proper diminishing rules on the step sizes. In particular, when $f$ is convex, we show $\mathcal{O}(\log(k)/\sqrt{k})$ rate of convergence in terms of the suboptimality gap. With an additional quadratic growth condition, the rate is improved to $\mathcal{O}(1/k)$ in terms of the squared distance to the optimal solution set. When $f$ is weakly convex, asymptotic convergence is derived. The central idea is that the dynamics of properly chosen step sizes rule fully controls the movement of the subgradient method, which leads to boundedness of the iterates, and then a trajectory-based analysis can be conducted to establish the desired results. To further illustrate the wide applicability of our framework, we extend the complexity results to the truncated subgradient, the stochastic subgradient, the incremental subgradient, and the proximal subgradient methods for non-Lipschitz functions.
Randomized Coordinate Subgradient Method for Nonsmooth Optimization
Jun 30, 2022
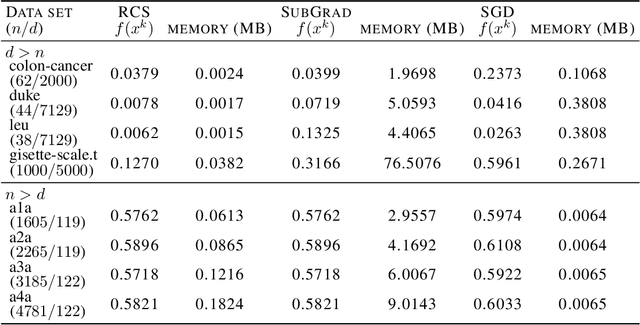
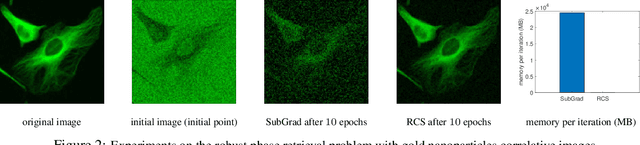
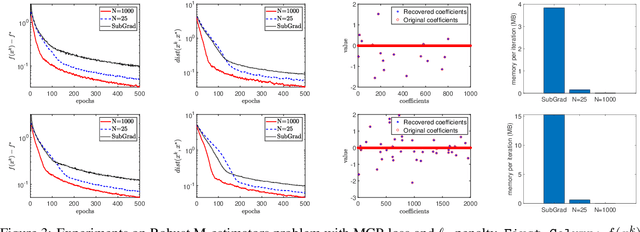
Nonsmooth optimization finds wide applications in many engineering fields. In this work, we propose to utilize the {Randomized Coordinate Subgradient Method} (RCS) for solving both nonsmooth convex and nonsmooth nonconvex (nonsmooth weakly convex) optimization problems. At each iteration, RCS randomly selects one block coordinate rather than all the coordinates to update. Motivated by practical applications, we consider the {linearly bounded subgradients assumption} for the objective function, which is much more general than the Lipschitz continuity assumption. Under such a general assumption, we conduct thorough convergence analysis for RCS in both convex and nonconvex cases and establish both expected convergence rate and almost sure asymptotic convergence results. In order to derive these convergence results, we establish a convergence lemma and the relationship between the global metric subregularity properties of a weakly convex function and its Moreau envelope, which are fundamental and of independent interests. Finally, we conduct several experiments to show the possible superiority of RCS over the subgradient method.