 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Performance of Linear Denoisers in the Proportional Regime
Mar 19, 2026In the present paper we study the performance of linear denoisers for noisy data of the form $\mathbf{x} + \mathbf{z}$, where $\mathbf{x} \in \mathbb{R}^d$ is the desired data with zero mean and unknown covariance $\mathbfΣ$, and $\mathbf{z} \sim \mathcal{N}(0, \mathbfΣ_{\mathbf{z}})$ is additive noise. Since the covariance $\mathbfΣ$ is not known, the standard Wiener filter cannot be employed for denoising. Instead we assume we are given samples $\mathbf{x}_1,\dots,\mathbf{x}_n \in \mathbb{R}^d$ from the true distribution. A standard approach would then be to estimate $\mathbfΣ$ from the samples and use it to construct an ``empirical" Wiener filter. However, in this paper, motivated by the denoising step in diffusion models, we take a different approach whereby we train a linear denoiser $\mathbf{W}$ from the data itself. In particular, we synthetically construct noisy samples $\hat{\mathbf{x}}_i$ of the data by injecting the samples with Gaussian noise with covariance $\mathbfΣ_1 \neq \mathbfΣ_{\mathbf{z}}$ and find the best $\mathbf{W}$ that approximates $\mathbf{W}\hat{\mathbf{x}}_i \approx \mathbf{x}_i$ in a least-squares sense. In the proportional regime $\frac{n}{d} \rightarrow κ> 1$ we use the {\it Convex Gaussian Min-Max Theorem (CGMT)} to analytically find the closed form expression for the generalization error of the denoiser obtained from this process. Using this expression one can optimize over $\mathbfΣ_1$ to find the best possible denoiser. Our numerical simulations show that our denoiser outperforms the ``empirical" Wiener filter in many scenarios and approaches the optimal Wiener filter as $κ\rightarrow\infty$.
Dual Space Preconditioning for Gradient Descent in the Overparameterized Regime
Mar 11, 2026In this work we study the convergence properties of the Dual Space Preconditioned Gradient Descent, encompassing optimizers such as Normalized Gradient Descent, Gradient Clipping and Adam. We consider preconditioners of the form $\nabla K$, where $K: \mathbb{R}^p \to \mathbb{R}$ is convex and assume that the latter is applied to train an over-parameterized linear model with loss of the form $\ell({X} {W} - {Y})$, for weights ${W} \in \mathbb{R}^{d \times k}$, labels ${Y} \in \mathbb{R}^{n \times k}$ and data ${X} \in \mathbb{R}^{n \times d}$. Under the aforementioned assumptions, we prove that the iterates of the preconditioned gradient descent always converge to a point ${W}_{\infty} \in \mathbb{R}^{d \times k}$ satisfying ${X}{W}_{\infty} = {Y}$. Our proof techniques are of independent interest as we introduce a novel version of the Bregman Divergence with accompanying identities that allow us to establish convergence. We also study the implicit bias of Dual Space Preconditioned Gradient Descent. First, we demonstrate empirically that, for general $K(\cdot)$, ${W}_\infty$ depends on the chosen learning rate, hindering a precise characterization of the implicit bias. Then, for preconditioners of the form $K({G}) = h(\|{G}\|_F)$, known as \textit{isotropic preconditioners}, we show that ${W}_\infty$ minimizes $\|{W}_\infty - {W}_0\|_F^2$ subject to ${X}{W}_\infty = {Y}$, where ${W}_0$ is the initialization. Denoting the convergence point of GD initialized at ${W}_0$ by ${W}_{\text{GD}, \infty}$, we thus note ${W}_{\infty} = {W}_{\text{GD}, \infty}$ for isotropic preconditioners. Finally, we show that a similar fact holds for general preconditioners up to a multiplicative constant, namely, $\|{W}_0 - {W}_{\infty}\|_F \le c \|{W}_0 - {W}_{\text{GD}, \infty}\|_F$ for a constant $c>0$.
Implicit Bias and Convergence of Matrix Stochastic Mirror Descent
Feb 22, 2026We investigate Stochastic Mirror Descent (SMD) with matrix parameters and vector-valued predictions, a framework relevant to multi-class classification and matrix completion problems. Focusing on the overparameterized regime, where the total number of parameters exceeds the number of training samples, we prove that SMD with matrix mirror functions $ψ(\cdot)$ converges exponentially to a global interpolator. Furthermore, we generalize classical implicit bias results of vector SMD by demonstrating that the matrix SMD algorithm converges to the unique solution minimizing the Bregman divergence induced by $ψ(\cdot)$ from initialization subject to interpolating the data. These findings reveal how matrix mirror maps dictate inductive bias in high-dimensional, multi-output problems.
Concentration of Measure for Distributions Generated via Diffusion Models
Jan 13, 2025We show via a combination of mathematical arguments and empirical evidence that data distributions sampled from diffusion models satisfy a Concentration of Measure Property saying that any Lipschitz $1$-dimensional projection of a random vector is not too far from its mean with high probability. This implies that such models are quite restrictive and gives an explanation for a fact previously observed in arXiv:2410.14171 that conventional diffusion models cannot capture "heavy-tailed" data (i.e. data $\mathbf{x}$ for which the norm $\|\mathbf{x}\|_2$ does not possess a subgaussian tail) well. We then proceed to train a generalized linear model using stochastic gradient descent (SGD) on the diffusion-generated data for a multiclass classification task and observe empirically that a Gaussian universality result holds for the test error. In other words, the test error depends only on the first and second order statistics of the diffusion-generated data in the linear setting. Results of such forms are desirable because they allow one to assume the data itself is Gaussian for analyzing performance of the trained classifier. Finally, we note that current approaches to proving universality do not apply to this case as the covariance matrices of the data tend to have vanishing minimum singular values for the diffusion-generated data, while the current proofs assume that this is not the case (see Subsection 3.4 for more details). This leaves extending previous mathematical universality results as an intriguing open question.
Universality in Transfer Learning for Linear Models
Oct 03, 2024


Transfer learning is an attractive framework for problems where there is a paucity of data, or where data collection is costly. One common approach to transfer learning is referred to as "model-based", and involves using a model that is pretrained on samples from a source distribution, which is easier to acquire, and then fine-tuning the model on a few samples from the target distribution. The hope is that, if the source and target distributions are ``close", then the fine-tuned model will perform well on the target distribution even though it has seen only a few samples from it. In this work, we study the problem of transfer learning in linear models for both regression and binary classification. In particular, we consider the use of stochastic gradient descent (SGD) on a linear model initialized with pretrained weights and using a small training data set from the target distribution. In the asymptotic regime of large models, we provide an exact and rigorous analysis and relate the generalization errors (in regression) and classification errors (in binary classification) for the pretrained and fine-tuned models. In particular, we give conditions under which the fine-tuned model outperforms the pretrained one. An important aspect of our work is that all the results are "universal", in the sense that they depend only on the first and second order statistics of the target distribution. They thus extend well beyond the standard Gaussian assumptions commonly made in the literature.
One-Bit Quantization and Sparsification for Multiclass Linear Classification via Regularized Regression
Feb 16, 2024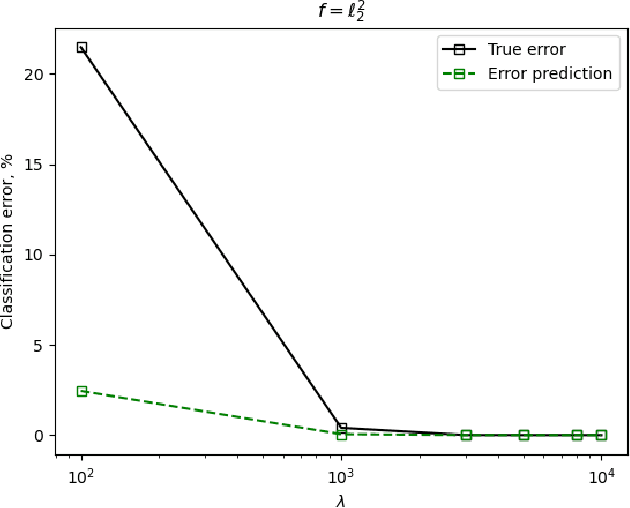
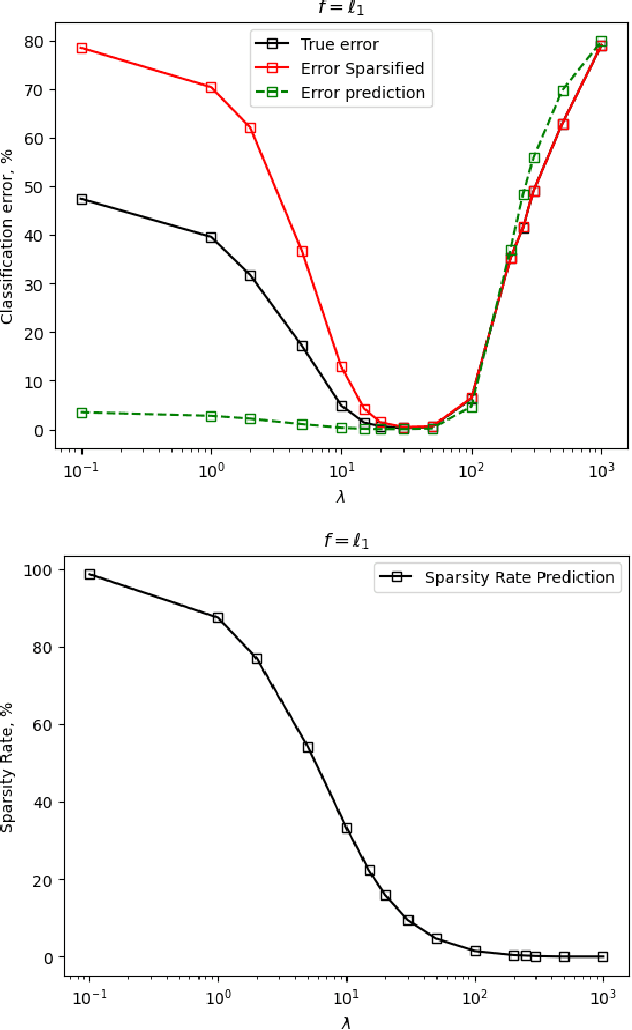
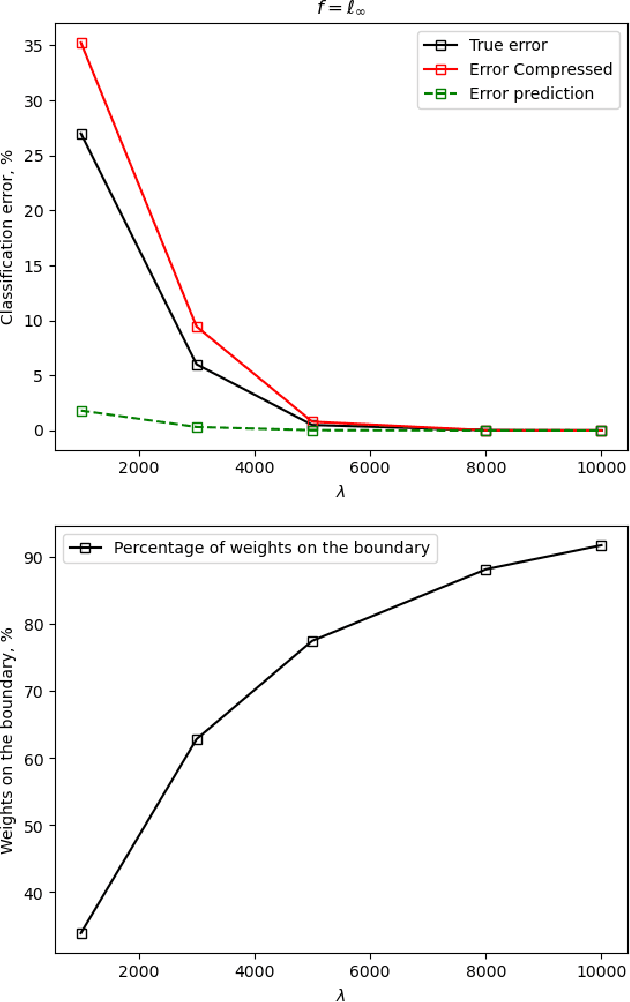
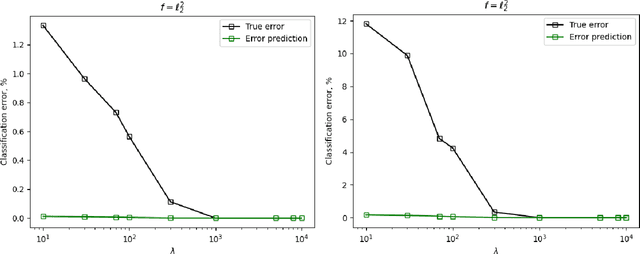
We study the use of linear regression for multiclass classification in the over-parametrized regime where some of the training data is mislabeled. In such scenarios it is necessary to add an explicit regularization term, $\lambda f(w)$, for some convex function $f(\cdot)$, to avoid overfitting the mislabeled data. In our analysis, we assume that the data is sampled from a Gaussian Mixture Model with equal class sizes, and that a proportion $c$ of the training labels is corrupted for each class. Under these assumptions, we prove that the best classification performance is achieved when $f(\cdot) = \|\cdot\|^2_2$ and $\lambda \to \infty$. We then proceed to analyze the classification errors for $f(\cdot) = \|\cdot\|_1$ and $f(\cdot) = \|\cdot\|_\infty$ in the large $\lambda$ regime and notice that it is often possible to find sparse and one-bit solutions, respectively, that perform almost as well as the one corresponding to $f(\cdot) = \|\cdot\|_2^2$.
A Novel Gaussian Min-Max Theorem and its Applications
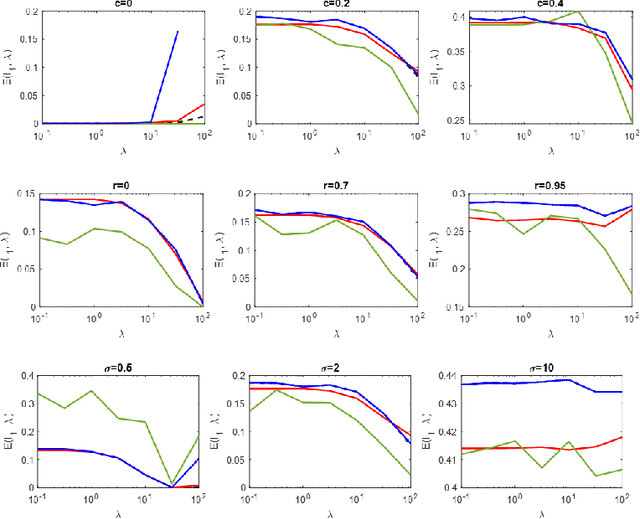
Feb 12, 2024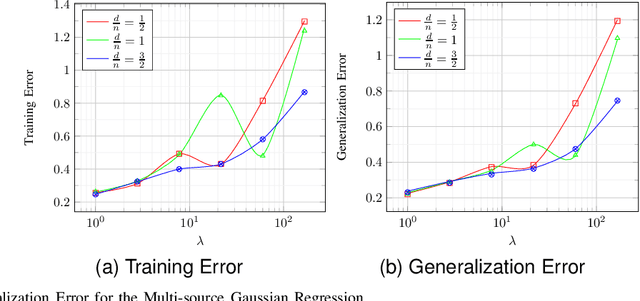
A celebrated result by Gordon allows one to compare the min-max behavior of two Gaussian processes if certain inequality conditions are met. The consequences of this result include the Gaussian min-max (GMT) and convex Gaussian min-max (CGMT) theorems which have had far-reaching implications in high-dimensional statistics, machine learning, non-smooth optimization, and signal processing. Both theorems rely on a pair of Gaussian processes, first identified by Slepian, that satisfy Gordon's comparison inequalities. To date, no other pair of Gaussian processes satisfying these inequalities has been discovered. In this paper, we identify such a new pair. The resulting theorems extend the classical GMT and CGMT Theorems from the case where the underlying Gaussian matrix in the primary process has iid rows to where it has independent but non-identically-distributed ones. The new CGMT is applied to the problems of multi-source Gaussian regression, as well as to binary classification of general Gaussian mixture models.
Regularized Linear Regression for Binary Classification
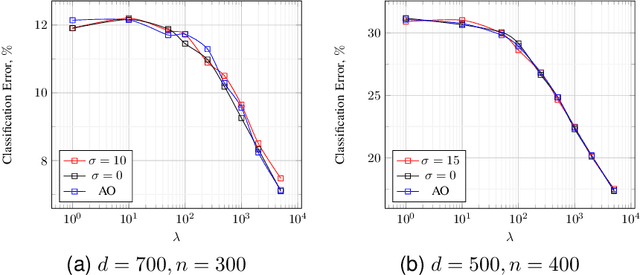
Nov 03, 2023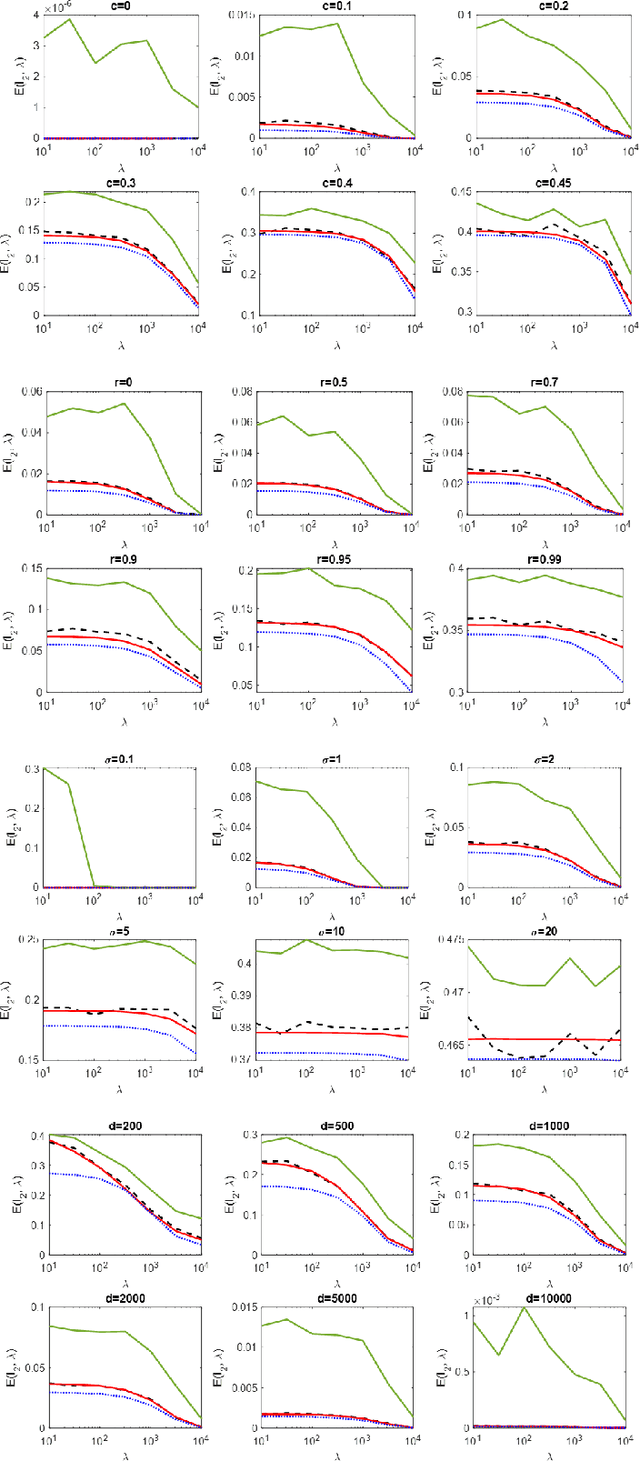
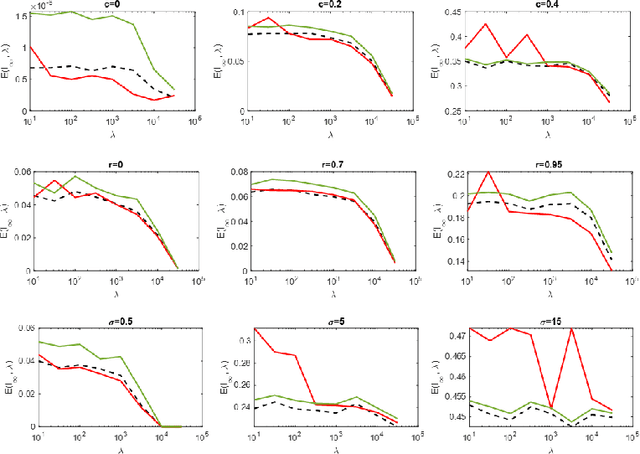
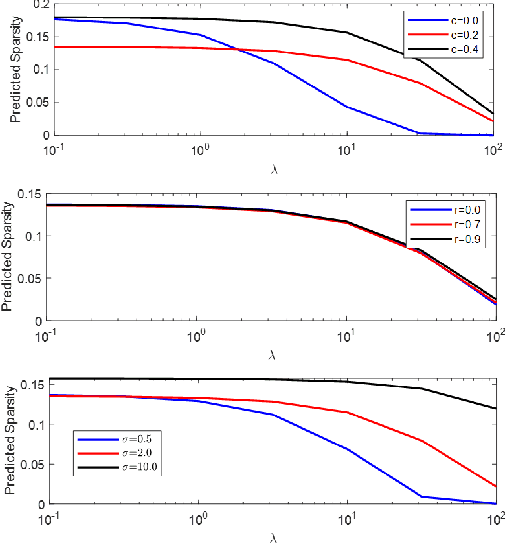
Regularized linear regression is a promising approach for binary classification problems in which the training set has noisy labels since the regularization term can help to avoid interpolating the mislabeled data points. In this paper we provide a systematic study of the effects of the regularization strength on the performance of linear classifiers that are trained to solve binary classification problems by minimizing a regularized least-squares objective. We consider the over-parametrized regime and assume that the classes are generated from a Gaussian Mixture Model (GMM) where a fraction $c<\frac{1}{2}$ of the training data is mislabeled. Under these assumptions, we rigorously analyze the classification errors resulting from the application of ridge, $\ell_1$, and $\ell_\infty$ regression. In particular, we demonstrate that ridge regression invariably improves the classification error. We prove that $\ell_1$ regularization induces sparsity and observe that in many cases one can sparsify the solution by up to two orders of magnitude without any considerable loss of performance, even though the GMM has no underlying sparsity structure. For $\ell_\infty$ regularization we show that, for large enough regularization strength, the optimal weights concentrate around two values of opposite sign. We observe that in many cases the corresponding "compression" of each weight to a single bit leads to very little loss in performance. These latter observations can have significant practical ramifications.
The Generalization Error of Stochastic Mirror Descent on Over-Parametrized Linear Models
Feb 18, 2023Despite being highly over-parametrized, and having the ability to fully interpolate the training data, deep networks are known to generalize well to unseen data. It is now understood that part of the reason for this is that the training algorithms used have certain implicit regularization properties that ensure interpolating solutions with "good" properties are found. This is best understood in linear over-parametrized models where it has been shown that the celebrated stochastic gradient descent (SGD) algorithm finds an interpolating solution that is closest in Euclidean distance to the initial weight vector. Different regularizers, replacing Euclidean distance with Bregman divergence, can be obtained if we replace SGD with stochastic mirror descent (SMD). Empirical observations have shown that in the deep network setting, SMD achieves a generalization performance that is different from that of SGD (and which depends on the choice of SMD's potential function. In an attempt to begin to understand this behavior, we obtain the generalization error of SMD for over-parametrized linear models for a binary classification problem where the two classes are drawn from a Gaussian mixture model. We present simulation results that validate the theory and, in particular, introduce two data models, one for which SMD with an $\ell_2$ regularizer (i.e., SGD) outperforms SMD with an $\ell_1$ regularizer, and one for which the reverse happens.