 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Bit Quantization and Sparsification for Multiclass Linear Classification via Regularized Regression
Paper and Code
Feb 16, 2024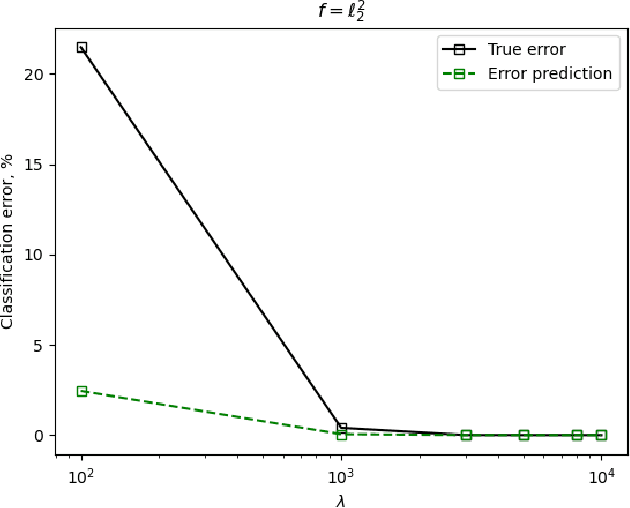
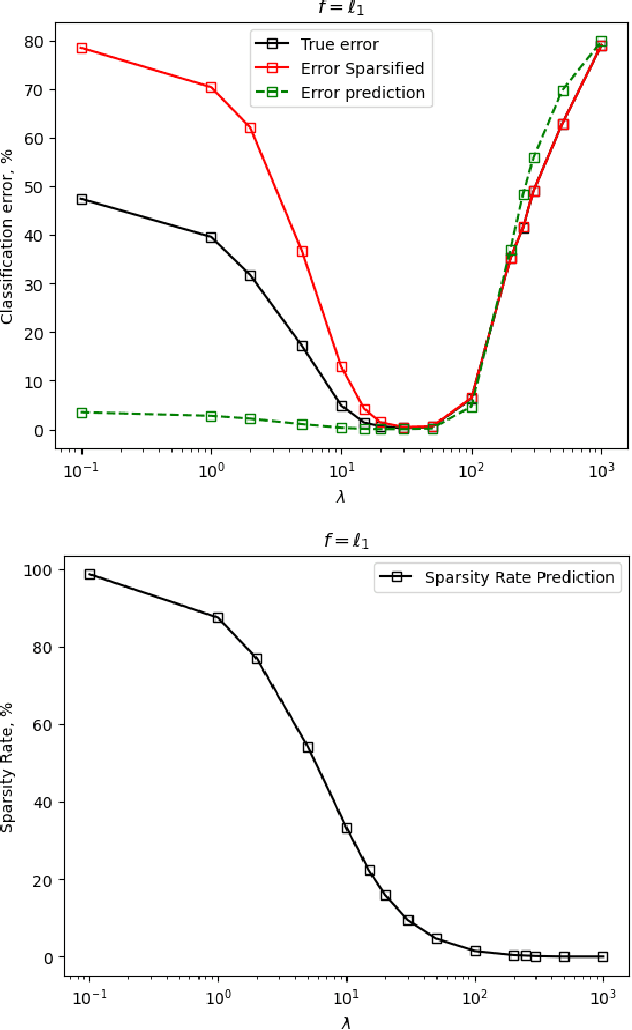
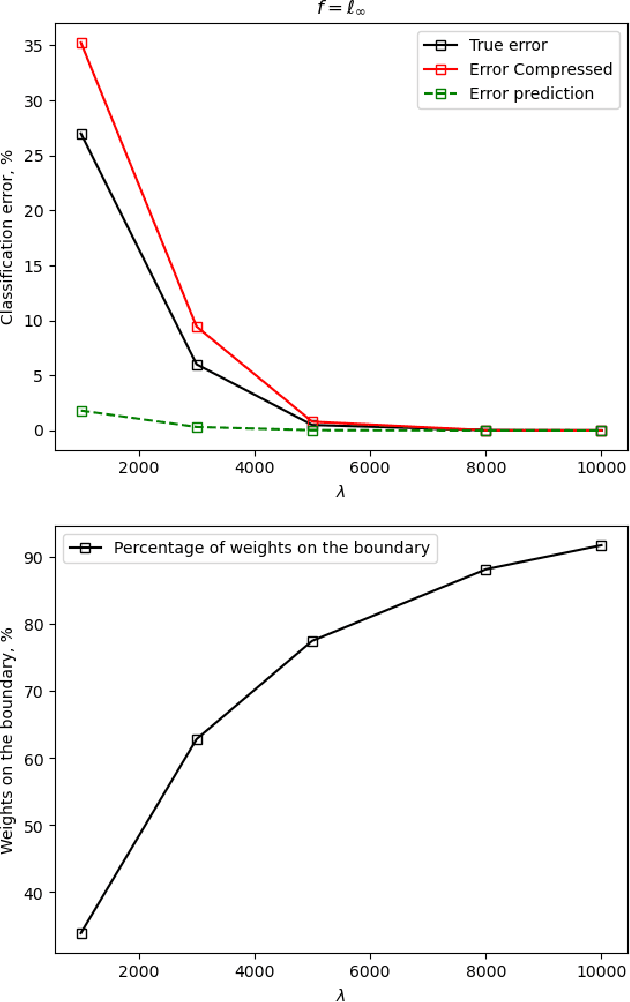
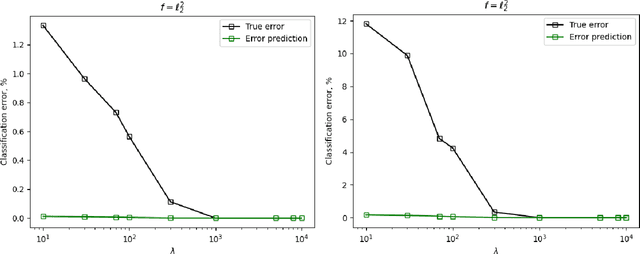
We study the use of linear regression for multiclass classification in the over-parametrized regime where some of the training data is mislabeled. In such scenarios it is necessary to add an explicit regularization term, $\lambda f(w)$, for some convex function $f(\cdot)$, to avoid overfitting the mislabeled data. In our analysis, we assume that the data is sampled from a Gaussian Mixture Model with equal class sizes, and that a proportion $c$ of the training labels is corrupted for each class. Under these assumptions, we prove that the best classification performance is achieved when $f(\cdot) = \|\cdot\|^2_2$ and $\lambda \to \infty$. We then proceed to analyze the classification errors for $f(\cdot) = \|\cdot\|_1$ and $f(\cdot) = \|\cdot\|_\infty$ in the large $\lambda$ regime and notice that it is often possible to find sparse and one-bit solutions, respectively, that perform almost as well as the one corresponding to $f(\cdot) = \|\cdot\|_2^2$.