 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Ensembling: Insights from Online Optimization and Empirical Bayes
May 21, 2025We revisit the classical problem of Bayesian ensembles and address the challenge of learning optimal combinations of Bayesian models in an online, continual learning setting. To this end, we reinterpret existing approaches such as Bayesian model averaging (BMA) and Bayesian stacking through a novel empirical Bayes lens, shedding new light on the limitations and pathologies of BMA. Further motivated by insights from online optimization, we propose Online Bayesian Stacking (OBS), a method that optimizes the log-score over predictive distributions to adaptively combine Bayesian models. A key contribution of our work is establishing a novel connection between OBS and portfolio selection, bridging Bayesian ensemble learning with a rich, well-studied theoretical framework that offers efficient algorithms and extensive regret analysis. We further clarify the relationship between OBS and online BMA, showing that they optimize related but distinct cost functions. Through theoretical analysis and empirical evaluation, we identify scenarios where OBS outperforms online BMA and provide principled guidance on when practitioners should prefer one approach over the other.
Decentralized Online Ensembles of Gaussian Processes for Multi-Agent Systems
Feb 07, 2025Flexible and scalable decentralized learning solutions are fundamentally important in the application of multi-agent systems. While several recent approaches introduce (ensembles of) kernel machines in the distributed setting, Bayesian solutions are much more limited. We introduce a fully decentralized, asymptotically exact solution to computing the random feature approximation of Gaussian processes. We further address the choice of hyperparameters by introducing an ensembling scheme for Bayesian multiple kernel learning based on online Bayesian model averaging. The resulting algorithm is tested against Bayesian and frequentist methods on simulated and real-world datasets.
Tangent Space Causal Inference: Leveraging Vector Fields for Causal Discovery in Dynamical Systems
Oct 30, 2024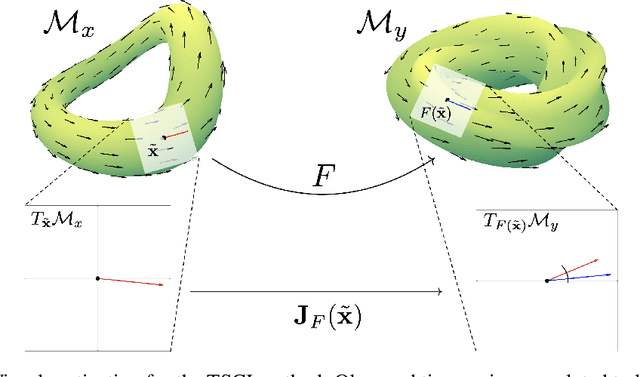
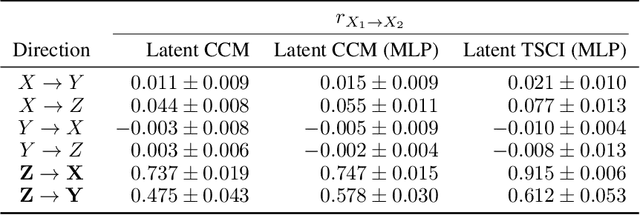
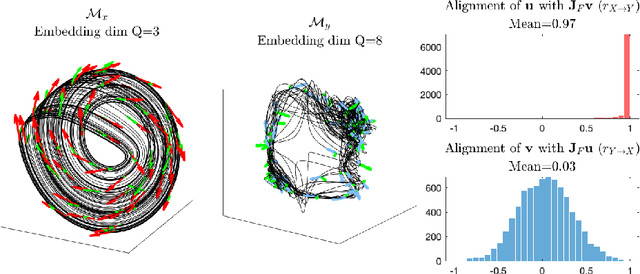

Causal discovery with time series data remains a challenging yet increasingly important task across many scientific domains. Convergent cross mapping (CCM) and related methods have been proposed to study time series that are generated by dynamical systems, where traditional approaches like Granger causality are unreliable. However, CCM often yields inaccurate results depending upon the quality of the data. We propose the Tangent Space Causal Inference (TSCI) method for detecting causalities in dynamical systems. TSCI works by considering vector fields as explicit representations of the systems' dynamics and checks for the degree of synchronization between the learned vector fields. The TSCI approach is model-agnostic and can be used as a drop-in replacement for CCM and its generalizations. We first present a basic version of the TSCI algorithm, which is shown to be more effective than the basic CCM algorithm with very little additional computation. We additionally present augmented versions of TSCI that leverage the expressive power of latent variable models and deep learning. We validate our theory on standard systems, and we demonstrate improved causal inference performance across a number of benchmark tasks.
A Gaussian Process-based Streaming Algorithm for Prediction of Time Series With Regimes and Outliers
Jun 01, 2024
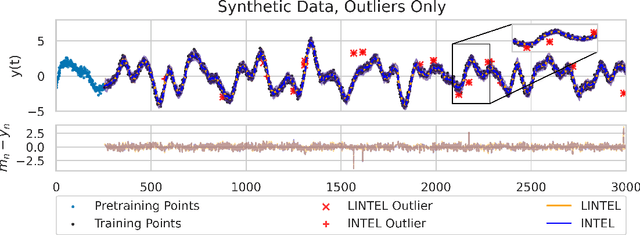
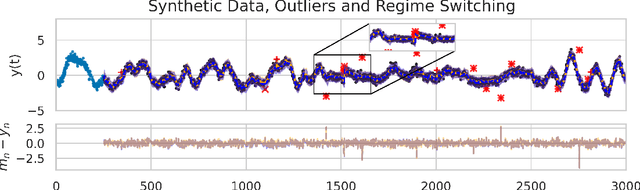
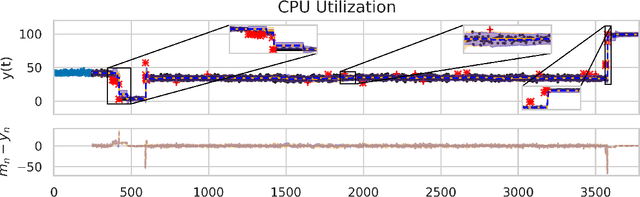
Online prediction of time series under regime switching is a widely studied problem in the literature, with many celebrated approaches. Using the non-parametric flexibility of Gaussian processes, the recently proposed INTEL algorithm provides a product of experts approach to online prediction of time series under possible regime switching, including the special case of outliers. This is achieved by adaptively combining several candidate models, each reporting their predictive distribution at time $t$. However, the INTEL algorithm uses a finite context window approximation to the predictive distribution, the computation of which scales cubically with the maximum lag, or otherwise scales quartically with exact predictive distributions. We introduce LINTEL, which uses the exact filtering distribution at time $t$ with constant-time updates, making the time complexity of the streaming algorithm optimal. We additionally note that the weighting mechanism of INTEL is better suited to a mixture of experts approach, and propose a fusion policy based on arithmetic averaging for LINTEL. We show experimentally that our proposed approach is over five times faster than INTEL under reasonable settings with better quality predictions.
Dynamic Online Ensembles of Basis Expansions
May 02, 2024Practical Bayesian learning often requires (1) online inference, (2) dynamic models, and (3) ensembling over multiple different models. Recent advances have shown how to use random feature approximations to achieve scalable, online ensembling of Gaussian processes with desirable theoretical properties and fruitful applications. One key to these methods' success is the inclusion of a random walk on the model parameters, which makes models dynamic. We show that these methods can be generalized easily to any basis expansion model and that using alternative basis expansions, such as Hilbert space Gaussian processes, often results in better performance. To simplify the process of choosing a specific basis expansion, our method's generality also allows the ensembling of several entirely different models, for example, a Gaussian process and polynomial regression. Finally, we propose a novel method to ensemble static and dynamic models together.
* 34 pages, 14 figures. Accepted to Transactions on Machine Learning Research (TMLR)
Fusion of Gaussian Processes Predictions with Monte Carlo Sampling
Mar 03, 2024


In science and engineering, we often work with models designed for accurate prediction of variables of interest. Recognizing that these models are approximations of reality, it becomes desirable to apply multiple models to the same data and integrate their outcomes. In this paper, we operate within the Bayesian paradigm, relying on Gaussian processes as our models. These models generate predictive probability density functions (pdfs), and the objective is to integrate them systematically, employing both linear and log-linear pooling. We introduce novel approaches for log-linear pooling, determining input-dependent weights for the predictive pdfs of the Gaussian processes. The aggregation of the pdfs is realized through Monte Carlo sampling, drawing samples of weights from their posterior. The performance of these methods, as well as those based on linear pooling, is demonstrated using a synthetic dataset.
Dagma-DCE: Interpretable, Non-Parametric Differentiable Causal Discovery
Jan 05, 2024


We introduce Dagma-DCE, an interpretable and model-agnostic scheme for differentiable causal discovery. Current non- or over-parametric methods in differentiable causal discovery use opaque proxies of ``independence'' to justify the inclusion or exclusion of a causal relationship. We show theoretically and empirically that these proxies may be arbitrarily different than the actual causal strength. Juxtaposed to existing differentiable causal discovery algorithms, \textsc{Dagma-DCE} uses an interpretable measure of causal strength to define weighted adjacency matrices. In a number of simulated datasets, we show our method achieves state-of-the-art level performance. We additionally show that \textsc{Dagma-DCE} allows for principled thresholding and sparsity penalties by domain-experts. The code for our method is available open-source at https://github.com/DanWaxman/DAGMA-DCE, and can easily be adapted to arbitrary differentiable models.