 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating the Computation of UCB and Related Indices for Reinforcement Learning
Sep 28, 2019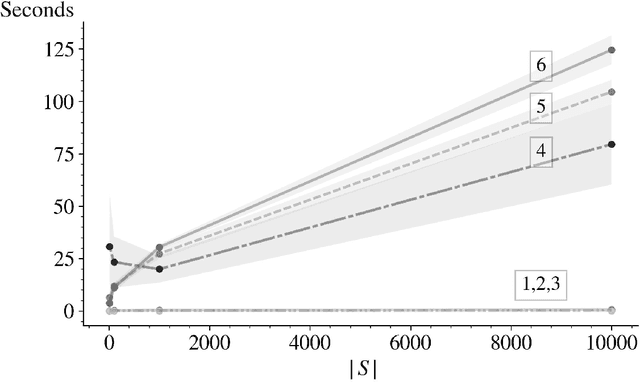
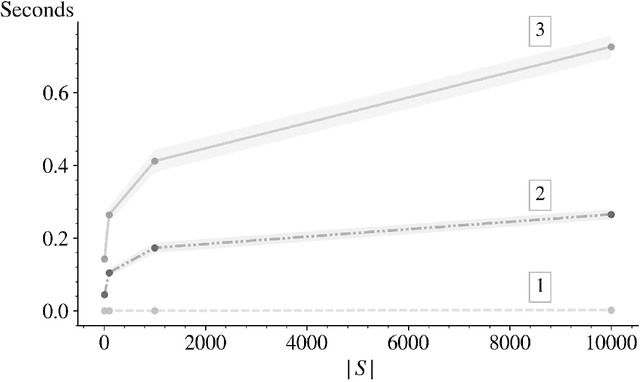
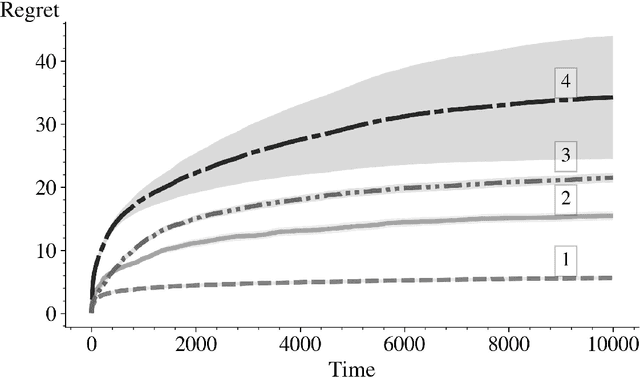
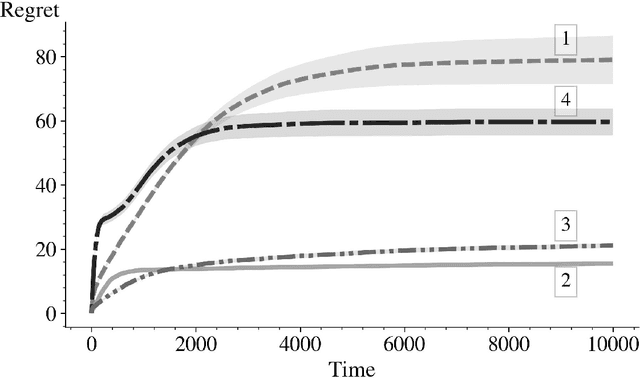
In this paper we derive an efficient method for computing the indices associated with an asymptotically optimal upper confidence bound algorithm (MDP-UCB) of Burnetas and Katehakis (1997) that only requires solving a system of two non-linear equations with two unknowns, irrespective of the cardinality of the state space of the Markovian decision process (MDP). In addition, we develop a similar acceleration for computing the indices for the MDP-Deterministic Minimum Empirical Divergence (MDP-DMED) algorithm developed in Cowan et al. (2019), based on ideas from Honda and Takemura (2011), that involves solving a single equation of one variable. We provide experimental results demonstrating the computational time savings and regret performance of these algorithms. In these comparison we also consider the Optimistic Linear Programming (OLP) algorithm (Tewari and Bartlett, 2008) and a method based on Posterior sampling (MDP-PS).
Reinforcement Learning: a Comparison of UCB Versus Alternative Adaptive Policies
Sep 13, 2019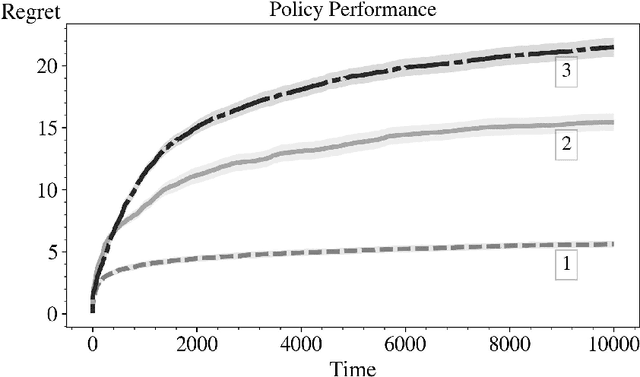
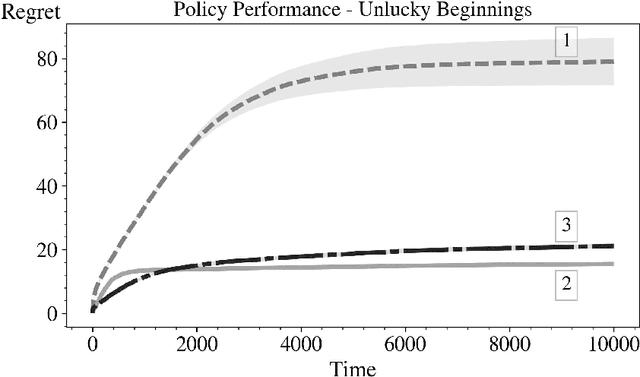
In this paper we consider the basic version of Reinforcement Learning (RL) that involves computing optimal data driven (adaptive) policies for Markovian decision process with unknown transition probabilities. We provide a brief survey of the state of the art of the area and we compare the performance of the classic UCB policy of \cc{bkmdp97} with a new policy developed herein which we call MDP-Deterministic Minimum Empirical Divergence (MDP-DMED), and a method based on Posterior sampling (MDP-PS).