Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning: a Comparison of UCB Versus Alternative Adaptive Policies
Paper and Code
Sep 13, 2019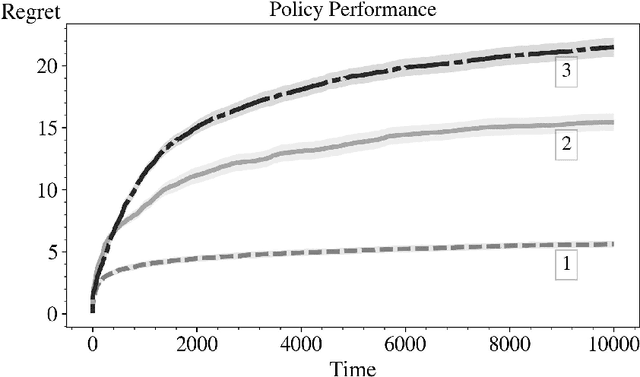
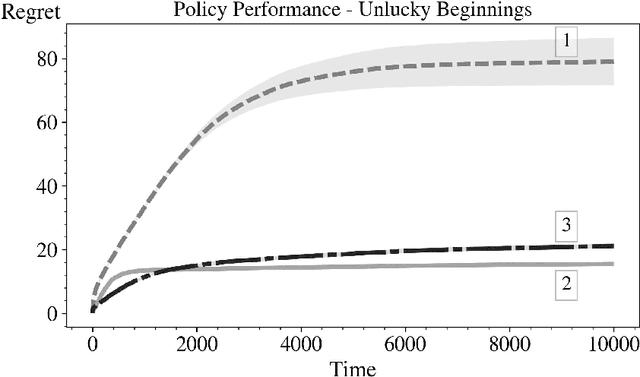
In this paper we consider the basic version of Reinforcement Learning (RL) that involves computing optimal data driven (adaptive) policies for Markovian decision process with unknown transition probabilities. We provide a brief survey of the state of the art of the area and we compare the performance of the classic UCB policy of \cc{bkmdp97} with a new policy developed herein which we call MDP-Deterministic Minimum Empirical Divergence (MDP-DMED), and a method based on Posterior sampling (MDP-PS).
View paper on