 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaths and Ambient Spaces in Neural Loss Landscapes
Mar 05, 2025



Understanding the structure of neural network loss surfaces, particularly the emergence of low-loss tunnels, is critical for advancing neural network theory and practice. In this paper, we propose a novel approach to directly embed loss tunnels into the loss landscape of neural networks. Exploring the properties of these loss tunnels offers new insights into their length and structure and sheds light on some common misconceptions. We then apply our approach to Bayesian neural networks, where we improve subspace inference by identifying pitfalls and proposing a more natural prior that better guides the sampling procedure.
How Inverse Conditional Flows Can Serve as a Substitute for Distributional Regression
May 08, 2024



Neural network representations of simple models, such as linear regression, are being studied increasingly to better understand the underlying principles of deep learning algorithms. However, neural representations of distributional regression models, such as the Cox model, have received little attention so far. We close this gap by proposing a framework for distributional regression using inverse flow transformations (DRIFT), which includes neural representations of the aforementioned models. We empirically demonstrate that the neural representations of models in DRIFT can serve as a substitute for their classical statistical counterparts in several applications involving continuous, ordered, time-series, and survival outcomes. We confirm that models in DRIFT empirically match the performance of several statistical methods in terms of estimation of partial effects, prediction, and aleatoric uncertainty quantification. DRIFT covers both interpretable statistical models and flexible neural networks opening up new avenues in both statistical modeling and deep learning.
Bayesian Semi-structured Subspace Inference
Jan 23, 2024

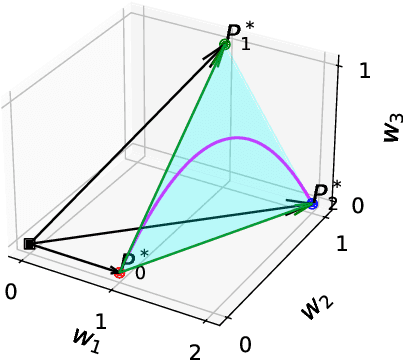

Semi-structured regression models enable the joint modeling of interpretable structured and complex unstructured feature effects. The structured model part is inspired by statistical models and can be used to infer the input-output relationship for features of particular importance. The complex unstructured part defines an arbitrary deep neural network and thereby provides enough flexibility to achieve competitive prediction performance. While these models can also account for aleatoric uncertainty, there is still a lack of work on accounting for epistemic uncertainty. In this paper, we address this problem by presenting a Bayesian approximation for semi-structured regression models using subspace inference. To this end, we extend subspace inference for joint posterior sampling from a full parameter space for structured effects and a subspace for unstructured effects. Apart from this hybrid sampling scheme, our method allows for tunable complexity of the subspace and can capture multiple minima in the loss landscape. Numerical experiments validate our approach's efficacy in recovering structured effect parameter posteriors in semi-structured models and approaching the full-space posterior distribution of MCMC for increasing subspace dimension. Further, our approach exhibits competitive predictive performance across simulated and real-world datasets.
Bernstein Flows for Flexible Posteriors in Variational Bayes
Feb 11, 2022

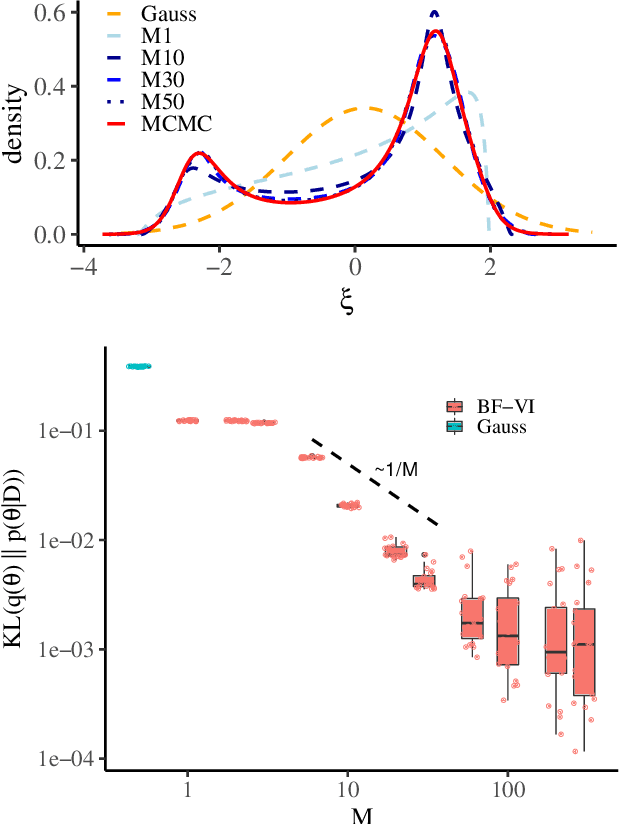
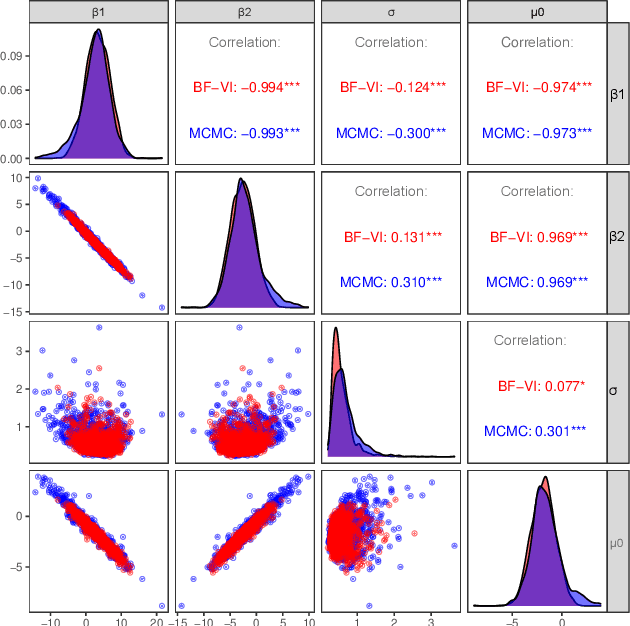
Variational inference (VI) is a technique to approximate difficult to compute posteriors by optimization. In contrast to MCMC, VI scales to many observations. In the case of complex posteriors, however, state-of-the-art VI approaches often yield unsatisfactory posterior approximations. This paper presents Bernstein flow variational inference (BF-VI), a robust and easy-to-use method, flexible enough to approximate complex multivariate posteriors. BF-VI combines ideas from normalizing flows and Bernstein polynomial-based transformation models. In benchmark experiments, we compare BF-VI solutions with exact posteriors, MCMC solutions, and state-of-the-art VI methods including normalizing flow based VI. We show for low-dimensional models that BF-VI accurately approximates the true posterior; in higher-dimensional models, BF-VI outperforms other VI methods. Further, we develop with BF-VI a Bayesian model for the semi-structured Melanoma challenge data, combining a CNN model part for image data with an interpretable model part for tabular data, and demonstrate for the first time how the use of VI in semi-structured models.
Transformation Models for Flexible Posteriors in Variational Bayes
Jun 01, 2021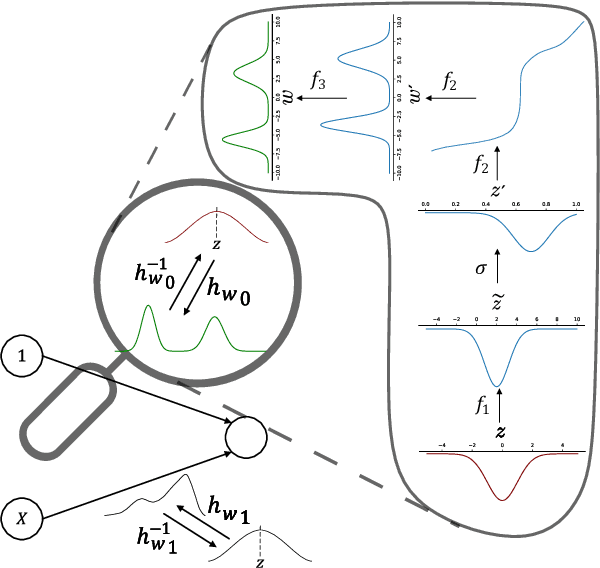
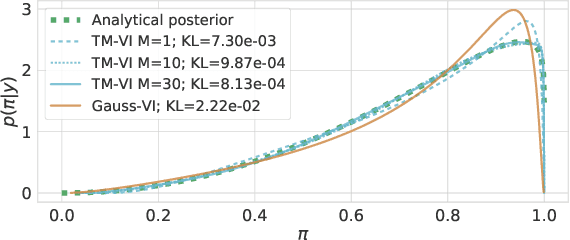
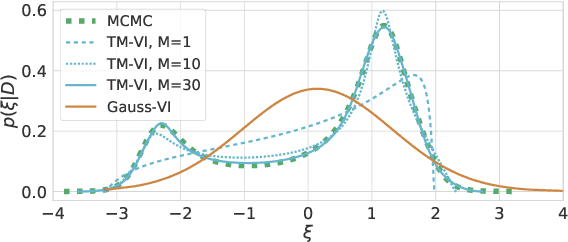
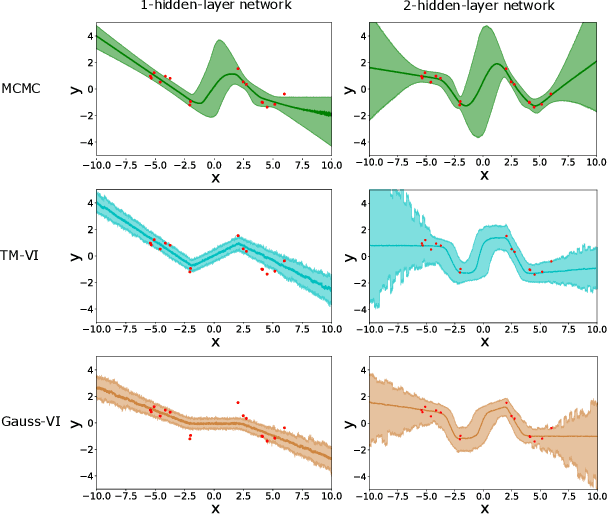
The main challenge in Bayesian models is to determine the posterior for the model parameters. Already, in models with only one or few parameters, the analytical posterior can only be determined in special settings. In Bayesian neural networks, variational inference is widely used to approximate difficult-to-compute posteriors by variational distributions. Usually, Gaussians are used as variational distributions (Gaussian-VI) which limits the quality of the approximation due to their limited flexibility. Transformation models on the other hand are flexible enough to fit any distribution. Here we present transformation model-based variational inference (TM-VI) and demonstrate that it allows to accurately approximate complex posteriors in models with one parameter and also works in a mean-field fashion for multi-parameter models like neural networks.