 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage hooks: a modular framework for augmenting LLM reasoning that decouples tool usage from the model and its prompt
Dec 08, 2024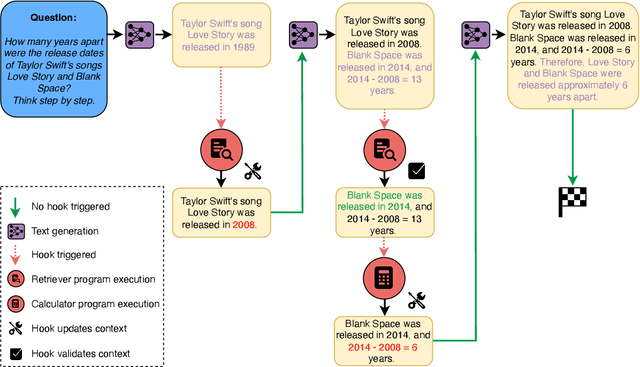
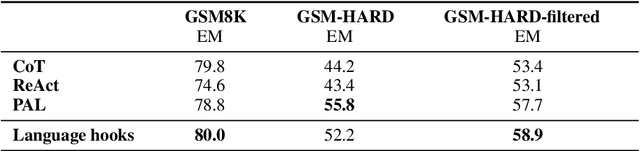
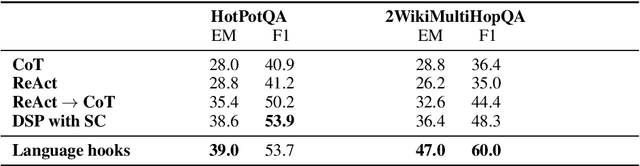
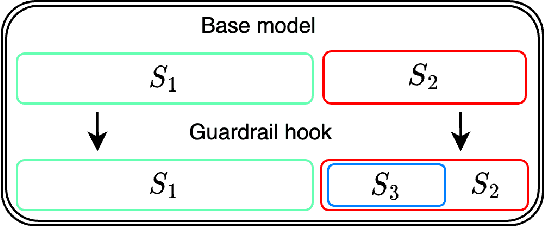
Prompting and fine-tuning have emerged as two competing paradigms for augmenting language models with new capabilities, such as the use of tools. Prompting approaches are quick to set up but rely on providing explicit demonstrations of each tool's usage in the model's prompt, thus coupling tool use to the task at hand and limiting generalisation. Fine-tuning removes the need for task-specific demonstrations of tool usage at runtime; however, this ties new capabilities to a single model, thus making already-heavier setup costs a recurring expense. In this paper, we introduce language hooks, a novel framework for augmenting language models with new capabilities that is decoupled both from the model's task-specific prompt and from the model itself. The language hook algorithm interleaves text generation by the base model with the execution of modular programs that trigger conditionally based on the existing text and the available capabilities. Upon triggering, programs may call external tools, auxiliary language models (e.g. using tool specific prompts), and modify the existing context. We benchmark our method against state-of-the-art baselines, find that it outperforms task-aware approaches, and demonstrate its ability to generalise to novel tasks.
Measuring chemical likeness of stars with RSCA
Oct 05, 2021

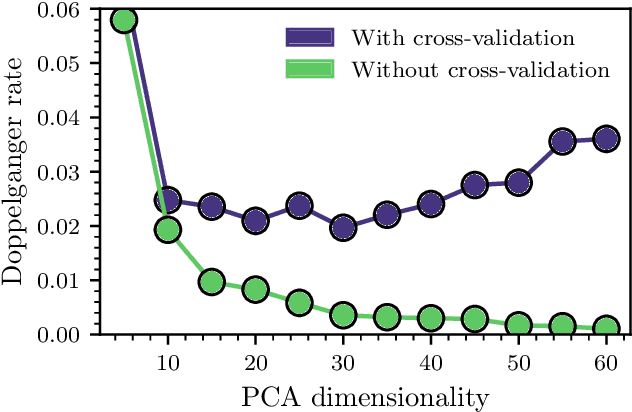

Identification of chemically similar stars using elemental abundances is core to many pursuits within Galactic archaeology. However, measuring the chemical likeness of stars using abundances directly is limited by systematic imprints of imperfect synthetic spectra in abundance derivation. We present a novel data-driven model that is capable of identifying chemically similar stars from spectra alone. We call this Relevant Scaled Component Analysis (RSCA). RSCA finds a mapping from stellar spectra to a representation that optimizes recovery of known open clusters. By design, RSCA amplifies factors of chemical abundance variation and minimizes those of non-chemical parameters, such as instrument systematics. The resultant representation of stellar spectra can therefore be used for precise measurements of chemical similarity between stars. We validate RSCA using 185 cluster stars in 22 open clusters in the APOGEE survey. We quantify our performance in measuring chemical similarity using a reference set of 151,145 field stars. We find that our representation identifies known stellar siblings more effectively than stellar abundance measurements. Using RSCA, 1.8% of pairs of field stars are as similar as birth siblings, compared to 2.3% when using stellar abundance labels. We find that almost all of the information within spectra leveraged by RSCA fits into a two-dimensional basis, which we link to [Fe/H] and alpha-element abundances. We conclude that chemical tagging of stars to their birth clusters remains prohibitive. However, using the spectra has noticeable gain, and our approach is poised to benefit from larger datasets and improved algorithm designs.
Disentangled Representation Learning for Astronomical Chemical Tagging
Mar 10, 2021

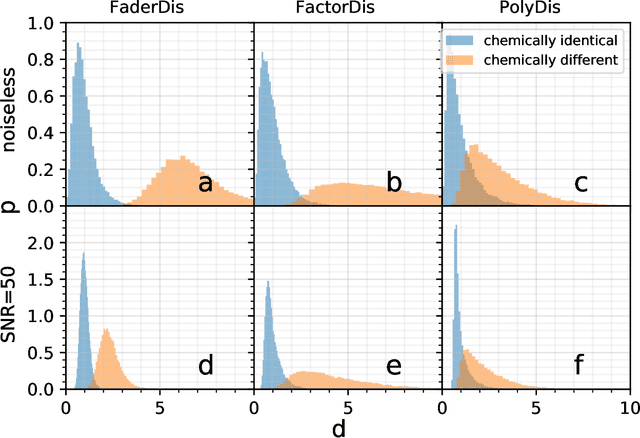
Modern astronomical surveys are observing spectral data for millions of stars. These spectra contain chemical information that can be used to trace the Galaxy's formation and chemical enrichment history. However, extracting the information from spectra, and making precise and accurate chemical abundance measurements are challenging. Here, we present a data-driven method for isolating the chemical factors of variation in stellar spectra from those of other parameters (i.e. \teff, \logg, \feh). This enables us to build a spectral projection for each star with these parameters removed. We do this with no ab initio knowledge of elemental abundances themselves, and hence bypass the uncertainties and systematics associated with modeling that rely on synthetic stellar spectra. To remove known non-chemical factors of variation, we develop and implement a neural network architecture that learns a disentangled spectral representation. We simulate our recovery of chemically identical stars using the disentangled spectra in a synthetic APOGEE-like dataset. We show that this recovery declines as a function of the signal to noise ratio, but that our neural network architecture outperforms simpler modeling choices. Our work demonstrates the feasibility of data-driven abundance-free chemical tagging.
Human-interpretable model explainability on high-dimensional data
Oct 14, 2020
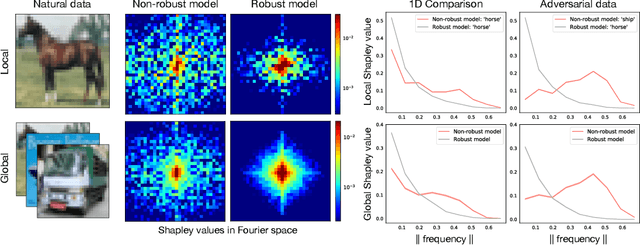
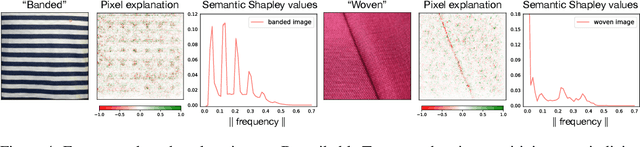
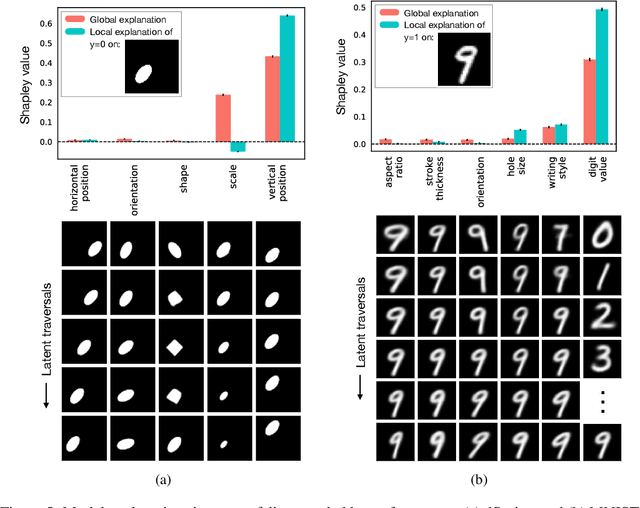
The importance of explainability in machine learning continues to grow, as both neural-network architectures and the data they model become increasingly complex. Unique challenges arise when a model's input features become high dimensional: on one hand, principled model-agnostic approaches to explainability become too computationally expensive; on the other, more efficient explainability algorithms lack natural interpretations for general users. In this work, we introduce a framework for human-interpretable explainability on high-dimensional data, consisting of two modules. First, we apply a semantically meaningful latent representation, both to reduce the raw dimensionality of the data, and to ensure its human interpretability. These latent features can be learnt, e.g. explicitly as disentangled representations or implicitly through image-to-image translation, or they can be based on any computable quantities the user chooses. Second, we adapt the Shapley paradigm for model-agnostic explainability to operate on these latent features. This leads to interpretable model explanations that are both theoretically controlled and computationally tractable. We benchmark our approach on synthetic data and demonstrate its effectiveness on several image-classification tasks.
Shapley-based explainability on the data manifold
Jun 01, 2020

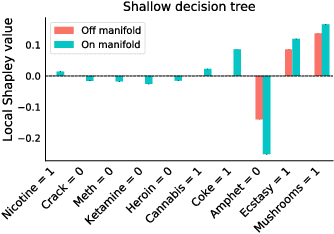
Explainability in machine learning is crucial for iterative model development, compliance with regulation, and providing operational nuance to model predictions. Shapley values provide a general framework for explainability by attributing a model's output prediction to its input features in a mathematically principled and model-agnostic way. However, practical implementations of the Shapley framework make an untenable assumption: that the model's input features are uncorrelated. In this work, we articulate the dangers of this assumption and introduce two solutions for computing Shapley explanations that respect the data manifold. One solution, based on generative modelling, provides flexible access to on-manifold data imputations, while the other directly learns the Shapley value function in a supervised way, providing performance and stability at the cost of flexibility. While the commonly used ``off-manifold'' Shapley values can (i) break symmetries in the data, (ii) give rise to misleading wrong-sign explanations, and (iii) lead to uninterpretable explanations in high-dimensional data, our approach to on-manifold explainability demonstrably overcomes each of these problems.