 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representation Learning for Astronomical Chemical Tagging
Paper and Code


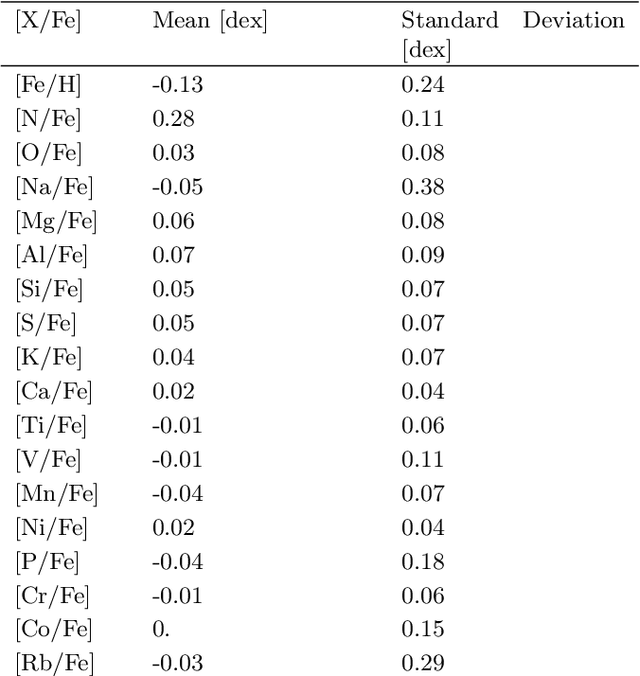
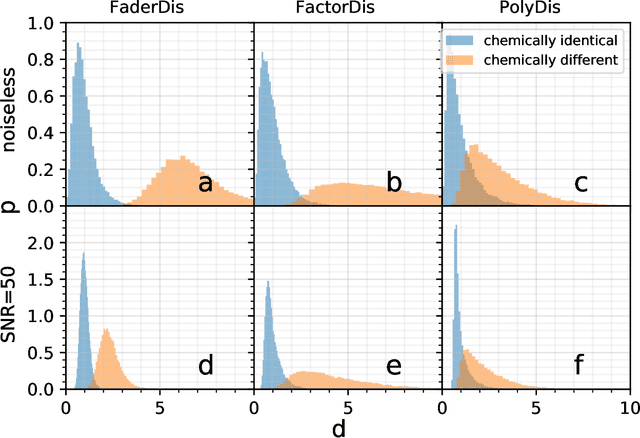
Modern astronomical surveys are observing spectral data for millions of stars. These spectra contain chemical information that can be used to trace the Galaxy's formation and chemical enrichment history. However, extracting the information from spectra, and making precise and accurate chemical abundance measurements are challenging. Here, we present a data-driven method for isolating the chemical factors of variation in stellar spectra from those of other parameters (i.e. \teff, \logg, \feh). This enables us to build a spectral projection for each star with these parameters removed. We do this with no ab initio knowledge of elemental abundances themselves, and hence bypass the uncertainties and systematics associated with modeling that rely on synthetic stellar spectra. To remove known non-chemical factors of variation, we develop and implement a neural network architecture that learns a disentangled spectral representation. We simulate our recovery of chemically identical stars using the disentangled spectra in a synthetic APOGEE-like dataset. We show that this recovery declines as a function of the signal to noise ratio, but that our neural network architecture outperforms simpler modeling choices. Our work demonstrates the feasibility of data-driven abundance-free chemical tagging.