 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Latent Distributions Without Finite Mean in Generative Models
Jun 05, 2018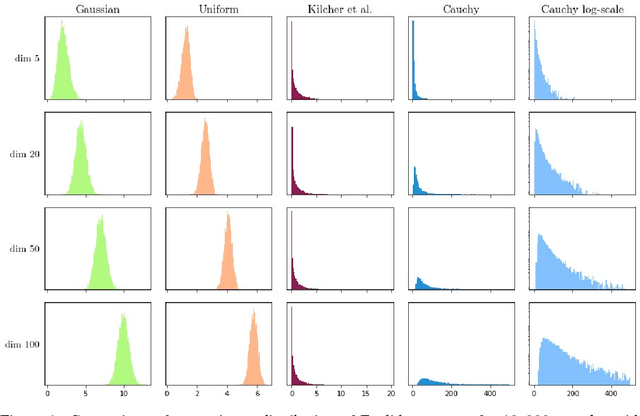



We investigate the properties of multidimensional probability distributions in the context of latent space prior distributions of implicit generative models. Our work revolves around the phenomena arising while decoding linear interpolations between two random latent vectors -- regions of latent space in close proximity to the origin of the space are sampled causing distribution mismatch. We show that due to the Central Limit Theorem, this region is almost never sampled during the training process. As a result, linear interpolations may generate unrealistic data and their usage as a tool to check quality of the trained model is questionable. We propose to use multidimensional Cauchy distribution as the latent prior. Cauchy distribution does not satisfy the assumptions of the CLT and has a number of properties that allow it to work well in conjunction with linear interpolations. We also provide two general methods of creating non-linear interpolations that are easily applicable to a large family of common latent distributions. Finally we empirically analyze the quality of data generated from low-probability-mass regions for the DCGAN model on the CelebA dataset.
Learning to SMILE(S)
Mar 08, 2018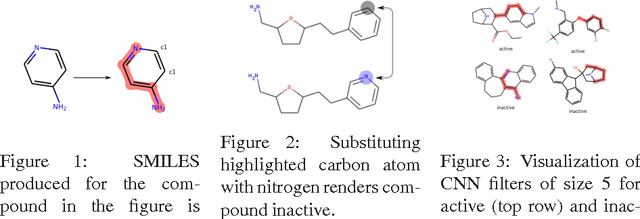

This paper shows how one can directly apply natural language processing (NLP) methods to classification problems in cheminformatics. Connection between these seemingly separate fields is shown by considering standard textual representation of compound, SMILES. The problem of activity prediction against a target protein is considered, which is a crucial part of computer aided drug design process. Conducted experiments show that this way one can not only outrank state of the art results of hand crafted representations but also gets direct structural insights into the way decisions are made.
How to evaluate word embeddings? On importance of data efficiency and simple supervised tasks
Feb 07, 2017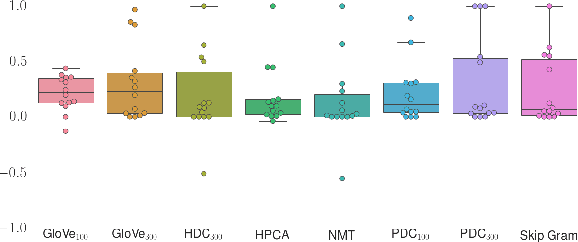



Maybe the single most important goal of representation learning is making subsequent learning faster. Surprisingly, this fact is not well reflected in the way embeddings are evaluated. In addition, recent practice in word embeddings points towards importance of learning specialized representations. We argue that focus of word representation evaluation should reflect those trends and shift towards evaluating what useful information is easily accessible. Specifically, we propose that evaluation should focus on data efficiency and simple supervised tasks, where the amount of available data is varied and scores of a supervised model are reported for each subset (as commonly done in transfer learning). In order to illustrate significance of such analysis, a comprehensive evaluation of selected word embeddings is presented. Proposed approach yields a more complete picture and brings new insight into performance characteristics, for instance information about word similarity or analogy tends to be non--linearly encoded in the embedding space, which questions the cosine-based, unsupervised, evaluation methods. All results and analysis scripts are available online.