 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Learning In-context Learning for Named Entity Recognition
May 26, 2023Named entity recognition in real-world applications suffers from the diversity of entity types, the emergence of new entity types, and the lack of high-quality annotations. To address the above problems, this paper proposes an in-context learning-based NER approach, which can effectively inject in-context NER ability into PLMs and recognize entities of novel types on-the-fly using only a few demonstrative instances. Specifically, we model PLMs as a meta-function $\mathcal{ \lambda_ {\text{instruction, demonstrations, text}}. M}$, and a new entity extractor can be implicitly constructed by applying new instruction and demonstrations to PLMs, i.e., $\mathcal{ (\lambda . M) }$(instruction, demonstrations) $\to$ $\mathcal{F}$ where $\mathcal{F}$ will be a new entity extractor, i.e., $\mathcal{F}$: text $\to$ entities. To inject the above in-context NER ability into PLMs, we propose a meta-function pre-training algorithm, which pre-trains PLMs by comparing the (instruction, demonstration)-initialized extractor with a surrogate golden extractor. Experimental results on 4 few-shot NER datasets show that our method can effectively inject in-context NER ability into PLMs and significantly outperforms the PLMs+fine-tuning counterparts.
Universal Information Extraction as Unified Semantic Matching
Jan 09, 2023



The challenge of information extraction (IE) lies in the diversity of label schemas and the heterogeneity of structures. Traditional methods require task-specific model design and rely heavily on expensive supervision, making them difficult to generalize to new schemas. In this paper, we decouple IE into two basic abilities, structuring and conceptualizing, which are shared by different tasks and schemas. Based on this paradigm, we propose to universally model various IE tasks with Unified Semantic Matching (USM) framework, which introduces three unified token linking operations to model the abilities of structuring and conceptualizing. In this way, USM can jointly encode schema and input text, uniformly extract substructures in parallel, and controllably decode target structures on demand. Empirical evaluation on 4 IE tasks shows that the proposed method achieves state-of-the-art performance under the supervised experiments and shows strong generalization ability in zero/few-shot transfer settings.
Unified Structure Generation for Universal Information Extraction
Mar 23, 2022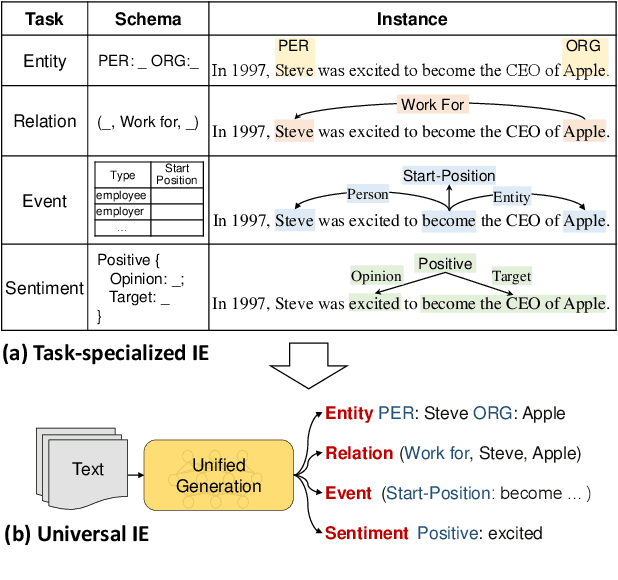


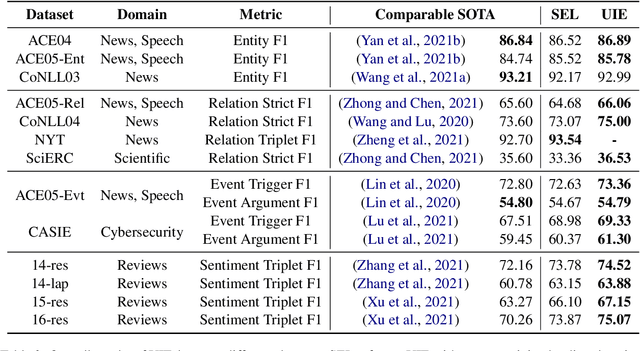
Information extraction suffers from its varying targets, heterogeneous structures, and demand-specific schemas. In this paper, we propose a unified text-to-structure generation framework, namely UIE, which can universally model different IE tasks, adaptively generate targeted structures, and collaboratively learn general IE abilities from different knowledge sources. Specifically, UIE uniformly encodes different extraction structures via a structured extraction language, adaptively generates target extractions via a schema-based prompt mechanism - structural schema instructor, and captures the common IE abilities via a large-scale pre-trained text-to-structure model. Experiments show that UIE achieved the state-of-the-art performance on 4 IE tasks, 13 datasets, and on all supervised, low-resource, and few-shot settings for a wide range of entity, relation, event and sentiment extraction tasks and their unification. These results verified the effectiveness, universality, and transferability of UIE.