 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Tallying Bandits: Overcoming Intractability via Repeated Exposure Optimality
May 04, 2023



In recommender system or crowdsourcing applications of online learning, a human's preferences or abilities are often a function of the algorithm's recent actions. Motivated by this, a significant line of work has formalized settings where an action's loss is a function of the number of times that action was recently played in the prior $m$ timesteps, where $m$ corresponds to a bound on human memory capacity. To more faithfully capture decay of human memory with time, we introduce the Weighted Tallying Bandit (WTB), which generalizes this setting by requiring that an action's loss is a function of a \emph{weighted} summation of the number of times that arm was played in the last $m$ timesteps. This WTB setting is intractable without further assumption. So we study it under Repeated Exposure Optimality (REO), a condition motivated by the literature on human physiology, which requires the existence of an action that when repetitively played will eventually yield smaller loss than any other sequence of actions. We study the minimization of the complete policy regret (CPR), which is the strongest notion of regret, in WTB under REO. Since $m$ is typically unknown, we assume we only have access to an upper bound $M$ on $m$. We show that for problems with $K$ actions and horizon $T$, a simple modification of the successive elimination algorithm has $O \left( \sqrt{KT} + (m+M)K \right)$ CPR. Interestingly, upto an additive (in lieu of mutliplicative) factor in $(m+M)K$, this recovers the classical guarantee for the simpler stochastic multi-armed bandit with traditional regret. We additionally show that in our setting, any algorithm will suffer additive CPR of $\Omega \left( mK + M \right)$, demonstrating our result is nearly optimal. Our algorithm is computationally efficient, and we experimentally demonstrate its practicality and superiority over natural baselines.
How Useful are Gradients for OOD Detection Really?
May 20, 2022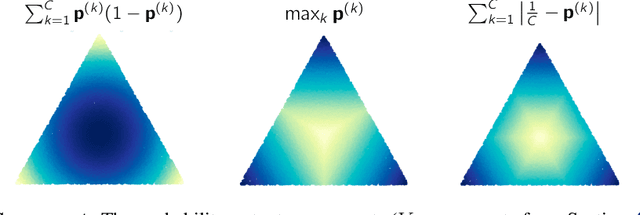

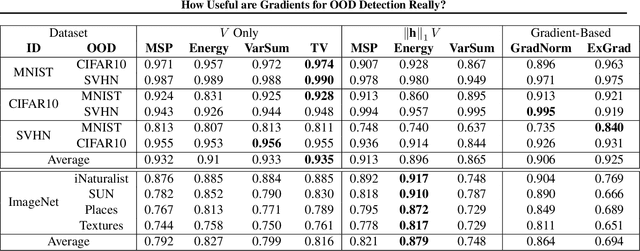
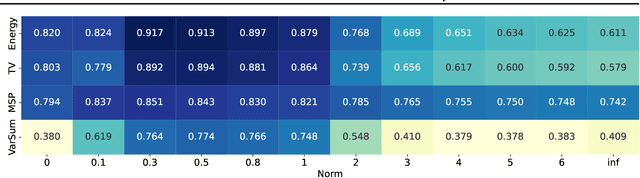
One critical challenge in deploying highly performant machine learning models in real-life applications is out of distribution (OOD) detection. Given a predictive model which is accurate on in distribution (ID) data, an OOD detection system will further equip the model with the option to defer prediction when the input is novel and the model has little confidence in prediction. There has been some recent interest in utilizing the gradient information in pre-trained models for OOD detection. While these methods have shown competitive performance, there are misconceptions about the true mechanism underlying them, which conflate their performance with the necessity of gradients. In this work, we provide an in-depth analysis and comparison of gradient based methods and elucidate the key components that warrant their OOD detection performance. We further propose a general, non-gradient based method of OOD detection which improves over previous baselines in both performance and computational efficiency.