 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Useful are Gradients for OOD Detection Really?
Paper and Code
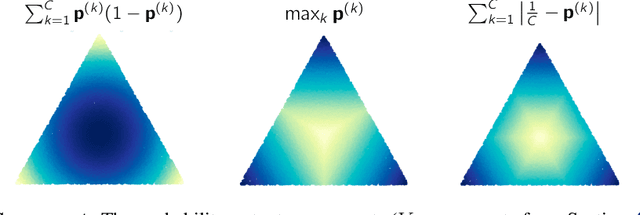

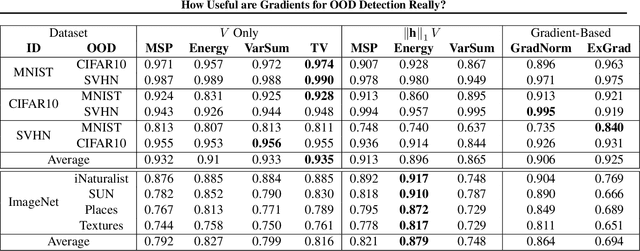
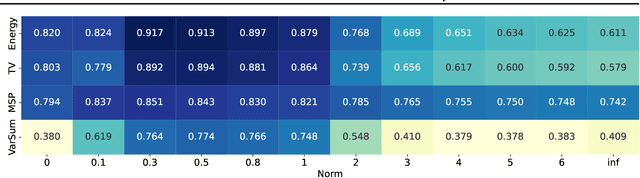
One critical challenge in deploying highly performant machine learning models in real-life applications is out of distribution (OOD) detection. Given a predictive model which is accurate on in distribution (ID) data, an OOD detection system will further equip the model with the option to defer prediction when the input is novel and the model has little confidence in prediction. There has been some recent interest in utilizing the gradient information in pre-trained models for OOD detection. While these methods have shown competitive performance, there are misconceptions about the true mechanism underlying them, which conflate their performance with the necessity of gradients. In this work, we provide an in-depth analysis and comparison of gradient based methods and elucidate the key components that warrant their OOD detection performance. We further propose a general, non-gradient based method of OOD detection which improves over previous baselines in both performance and computational efficiency.