 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy SLIM: A SLIM-Based Approach For Preference Elicitation
Jun 10, 2024Preference elicitation is an active learning approach to tackle the cold-start problem of recommender systems. Roughly speaking, new users are asked to rate some carefully selected items in order to compute appropriate recommendations for them. To the best of our knowledge, we are the first to propose a method for preference elicitation that is based on SLIM , a state-of-the-art technique for top-N recommendation. Our approach mainly consists of a new training technique for SLIM, which we call Greedy SLIM. This technique iteratively selects items for the training in order to minimize the SLIM loss greedily. We conduct offline experiments as well as a user study to assess the performance of this new method. The results are remarkable, especially with respect to the user study. We conclude that Greedy SLIM seems to be more suitable for preference elicitation than widely used methods based on latent factor models.
Scalable Unsupervised Multi-Criteria Trajectory Segmentation and Driving Preference Mining
Oct 23, 2020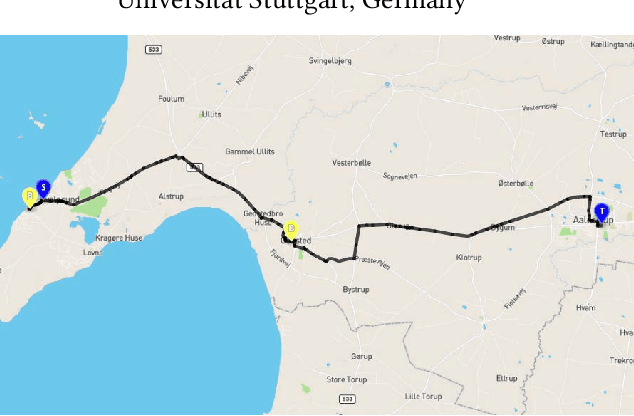
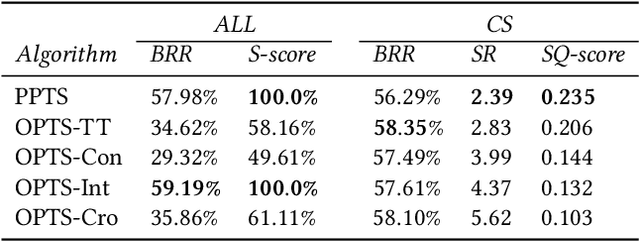
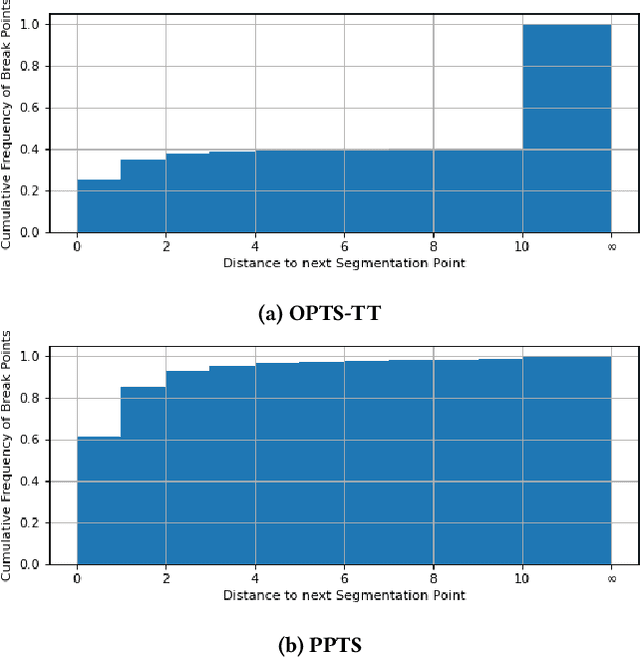
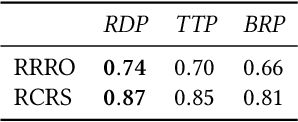
We present analysis techniques for large trajectory data sets that aim to provide a semantic understanding of trajectories reaching beyond them being point sequences in time and space. The presented techniques use a driving preference model w.r.t. road segment traversal costs, e.g., travel time and distance, to analyze and explain trajectories. In particular, we present trajectory mining techniques that can (a) find interesting points within a trajectory indicating, e.g., a via-point, and (b) recover the driving preferences of a driver based on their chosen trajectory. We evaluate our techniques on the tasks of via-point identification and personalized routing using a data set of more than 1 million vehicle trajectories collected throughout Denmark during a 3-year period. Our techniques can be implemented efficiently and are highly parallelizable, allowing them to scale to millions or billions of trajectories.
Coordination via predictive assistants: time series algorithms and game-theoretic analysis
Oct 05, 2018
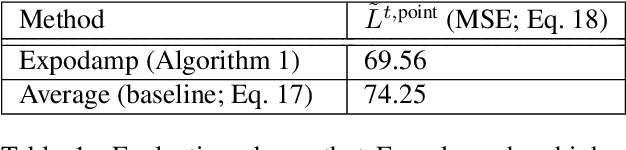

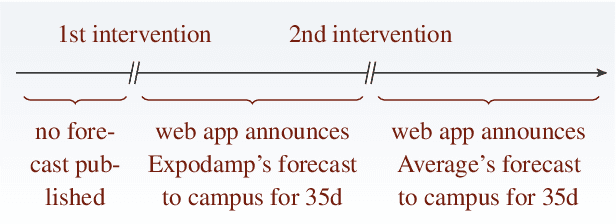
We study data-driven assistants that provide congestion forecasts to users of crowded facilities (roads, cafeterias, etc.), to support coordination between them. Having multiple agents and feedback loops from predictions to outcomes, new problems arise in terms of choosing (1) objective and (2) algorithms for such assistants. Addressing (1), we pick classical prediction accuracy as objective and establish general conditions under which optimizing it is equivalent to "solving" the coordination problem in an idealized game-theoretic sense -- selecting a certain Bayesian Nash equilibrium (BNE). Then we prove the existence of an assistant-based "solution" even for large-scale (nonatomic), aggregated settings. This entails a new BNE existence result. Addressing (2), we propose an exponential smoothing-based algorithm on time series data. We prove its optimality w.r.t.\ the prediction objective under a state-space model for the large-scale setting. We also provide a proof-of-concept algorithm and convergence guarantees for a small-scale, non-aggregated setting. We validate our algorithm in a large-scale experiment in a real cafeteria.