 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Optimality in the Noisy Value-and Comparison-Model --- Accept, Accept, Strong Accept: Which Papers get in?
Nov 05, 2018
Motivated by crowdsourced computation, peer-grading, and recommendation systems, Braverman, Mao and Weinberg [STOC'16] studied the \emph{query} and \emph{round} complexity of fundamental problems such as finding the maximum (\textsc{max}), finding all elements above a certain value (\textsc{threshold-$v$}) or computing the top$-k$ elements (\textsc{Top}-$k$) in a noisy environment. For example, consider the task of selecting papers for a conference. This task is challenging due the crowdsourcing nature of peer reviews: the results of reviews are noisy and it is necessary to parallelize the review process as much as possible. We study the noisy value model and the noisy comparison model: In the \emph{noisy value model}, a reviewer is asked to evaluate a single element: "What is the value of paper $i$?" (\eg accept). In the \emph{noisy comparison model} (introduced in the seminal work of Feige, Peleg, Raghavan and Upfal [SICOMP'94]) a reviewer is asked to do a pairwise comparison: "Is paper $i$ better than paper $j$?" In this paper, we show optimal worst-case query complexity for the \textsc{max},\textsc{threshold-$v$} and \textsc{Top}-$k$ problems. For \textsc{max} and \textsc{Top}-$k$, we obtain optimal worst-case upper and lower bounds on the round vs query complexity in both models. For \textsc{threshold}-$v$, we obtain optimal query complexity and nearly-optimal round complexity, where $k$ is the size of the output) for both models. We then go beyond the worst-case and address the question of the importance of knowledge of the instance by providing, for a large range of parameters, instance-optimal algorithms with respect to the query complexity. Furthermore, we show that the value model is strictly easier than the comparison model.
Hierarchical Clustering: Objective Functions and Algorithms
Apr 07, 2017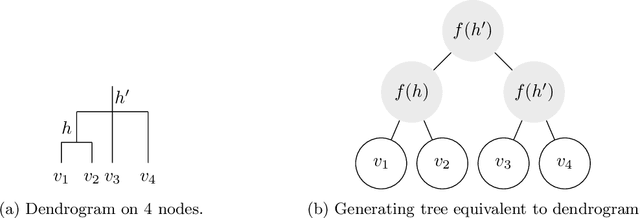
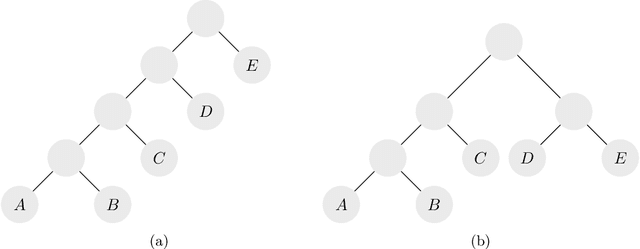
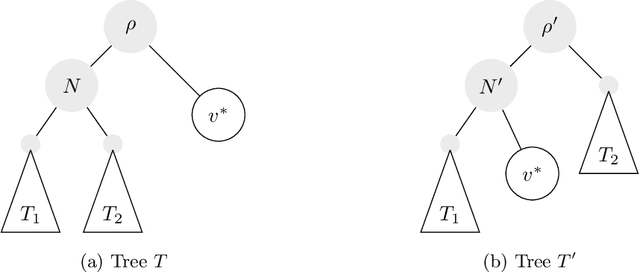
Hierarchical clustering is a recursive partitioning of a dataset into clusters at an increasingly finer granularity. Motivated by the fact that most work on hierarchical clustering was based on providing algorithms, rather than optimizing a specific objective, Dasgupta framed similarity-based hierarchical clustering as a combinatorial optimization problem, where a `good' hierarchical clustering is one that minimizes some cost function. He showed that this cost function has certain desirable properties. We take an axiomatic approach to defining `good' objective functions for both similarity and dissimilarity-based hierarchical clustering. We characterize a set of "admissible" objective functions (that includes Dasgupta's one) that have the property that when the input admits a `natural' hierarchical clustering, it has an optimal value. Equipped with a suitable objective function, we analyze the performance of practical algorithms, as well as develop better algorithms. For similarity-based hierarchical clustering, Dasgupta showed that the divisive sparsest-cut approach achieves an $O(\log^{3/2} n)$-approximation. We give a refined analysis of the algorithm and show that it in fact achieves an $O(\sqrt{\log n})$-approx. (Charikar and Chatziafratis independently proved that it is a $O(\sqrt{\log n})$-approx.). This improves upon the LP-based $O(\log n)$-approx. of Roy and Pokutta. For dissimilarity-based hierarchical clustering, we show that the classic average-linkage algorithm gives a factor 2 approx., and provide a simple and better algorithm that gives a factor 3/2 approx.. Finally, we consider `beyond-worst-case' scenario through a generalisation of the stochastic block model for hierarchical clustering. We show that Dasgupta's cost function has desirable properties for these inputs and we provide a simple 1 + o(1)-approximation in this setting.
Maximizing profit using recommender systems
Aug 25, 2009Traditional recommendation systems make recommendations based solely on the customer's past purchases, product ratings and demographic data without considering the profitability the items being recommended. In this work we study the question of how a vendor can directly incorporate the profitability of items into its recommender so as to maximize its expected profit while still providing accurate recommendations. Our approach uses the output of any traditional recommender system and adjust them according to item profitabilities. Our approach is parameterized so the vendor can control how much the recommendation incorporating profits can deviate from the traditional recommendation. We study our approach under two settings and show that it achieves approximately 22% more profit than traditional recommendations.