 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Clustering: Objective Functions and Algorithms
Paper and Code
Apr 07, 2017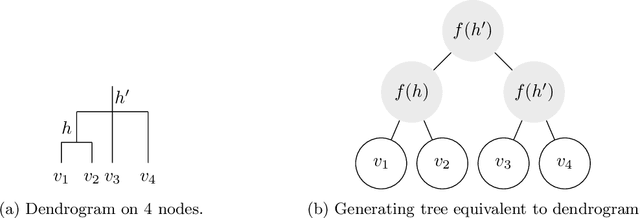
Hierarchical clustering is a recursive partitioning of a dataset into clusters at an increasingly finer granularity. Motivated by the fact that most work on hierarchical clustering was based on providing algorithms, rather than optimizing a specific objective, Dasgupta framed similarity-based hierarchical clustering as a combinatorial optimization problem, where a `good' hierarchical clustering is one that minimizes some cost function. He showed that this cost function has certain desirable properties. We take an axiomatic approach to defining `good' objective functions for both similarity and dissimilarity-based hierarchical clustering. We characterize a set of "admissible" objective functions (that includes Dasgupta's one) that have the property that when the input admits a `natural' hierarchical clustering, it has an optimal value. Equipped with a suitable objective function, we analyze the performance of practical algorithms, as well as develop better algorithms. For similarity-based hierarchical clustering, Dasgupta showed that the divisive sparsest-cut approach achieves an $O(\log^{3/2} n)$-approximation. We give a refined analysis of the algorithm and show that it in fact achieves an $O(\sqrt{\log n})$-approx. (Charikar and Chatziafratis independently proved that it is a $O(\sqrt{\log n})$-approx.). This improves upon the LP-based $O(\log n)$-approx. of Roy and Pokutta. For dissimilarity-based hierarchical clustering, we show that the classic average-linkage algorithm gives a factor 2 approx., and provide a simple and better algorithm that gives a factor 3/2 approx.. Finally, we consider `beyond-worst-case' scenario through a generalisation of the stochastic block model for hierarchical clustering. We show that Dasgupta's cost function has desirable properties for these inputs and we provide a simple 1 + o(1)-approximation in this setting.