 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Training Difficulty and Accelerating Convergence in Neural Network-Based PDE Solvers
Oct 08, 2024
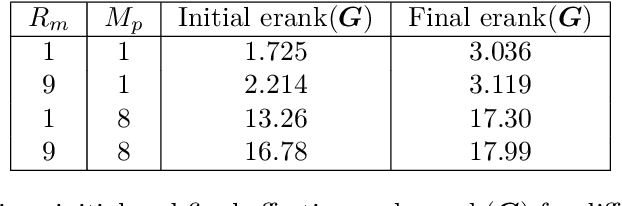

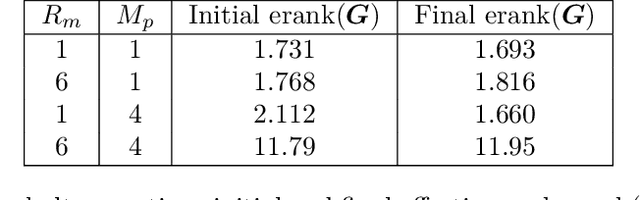
Neural network-based methods have emerged as powerful tools for solving partial differential equations (PDEs) in scientific and engineering applications, particularly when handling complex domains or incorporating empirical data. These methods leverage neural networks as basis functions to approximate PDE solutions. However, training such networks can be challenging, often resulting in limited accuracy. In this paper, we investigate the training dynamics of neural network-based PDE solvers with a focus on the impact of initialization techniques. We assess training difficulty by analyzing the eigenvalue distribution of the kernel and apply the concept of effective rank to quantify this difficulty, where a larger effective rank correlates with faster convergence of the training error. Building upon this, we discover through theoretical analysis and numerical experiments that two initialization techniques, partition of unity (PoU) and variance scaling (VS), enhance the effective rank, thereby accelerating the convergence of training error. Furthermore, comprehensive experiments using popular PDE-solving frameworks, such as PINN, Deep Ritz, and the operator learning framework DeepOnet, confirm that these initialization techniques consistently speed up convergence, in line with our theoretical findings.
Automatic Differentiation is Essential in Training Neural Networks for Solving Differential Equations
May 23, 2024



Neural network-based approaches have recently shown significant promise in solving partial differential equations (PDEs) in science and engineering, especially in scenarios featuring complex domains or the incorporation of empirical data. One advantage of the neural network method for PDEs lies in its automatic differentiation (AD), which necessitates only the sample points themselves, unlike traditional finite difference (FD) approximations that require nearby local points to compute derivatives. In this paper, we quantitatively demonstrate the advantage of AD in training neural networks. The concept of truncated entropy is introduced to characterize the training property. Specifically, through comprehensive experimental and theoretical analyses conducted on random feature models and two-layer neural networks, we discover that the defined truncated entropy serves as a reliable metric for quantifying the residual loss of random feature models and the training speed of neural networks for both AD and FD methods. Our experimental and theoretical analyses demonstrate that, from a training perspective, AD outperforms FD in solving partial differential equations.
Stability Analysis Framework for Particle-based Distance GANs with Wasserstein Gradient Flow
Jul 07, 2023
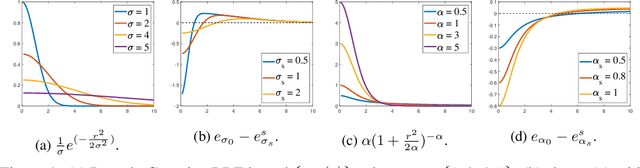
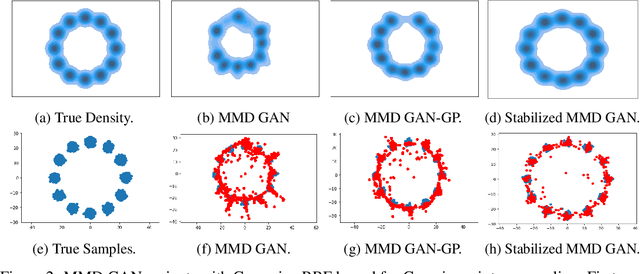
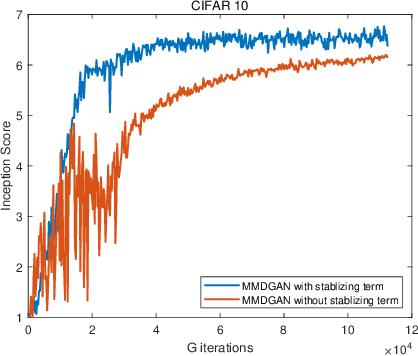
In this paper, we investigate the training process of generative networks that use a type of probability density distance named particle-based distance as the objective function, e.g. MMD GAN, Cram\'er GAN, EIEG GAN. However, these GANs often suffer from the problem of unstable training. In this paper, we analyze the stability of the training process of these GANs from the perspective of probability density dynamics. In our framework, we regard the discriminator $D$ in these GANs as a feature transformation mapping that maps high dimensional data into a feature space, while the generator $G$ maps random variables to samples that resemble real data in terms of feature space. This perspective enables us to perform stability analysis for the training of GANs using the Wasserstein gradient flow of the probability density function. We find that the training process of the discriminator is usually unstable due to the formulation of $\min_G \max_D E(G, D)$ in GANs. To address this issue, we add a stabilizing term in the discriminator loss function. We conduct experiments to validate our stability analysis and stabilizing method.
Elastic Interaction Energy-Based Generative Model: Approximation in Feature Space
Mar 19, 2023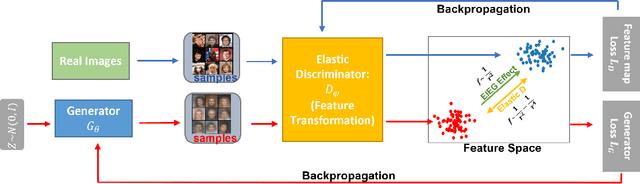
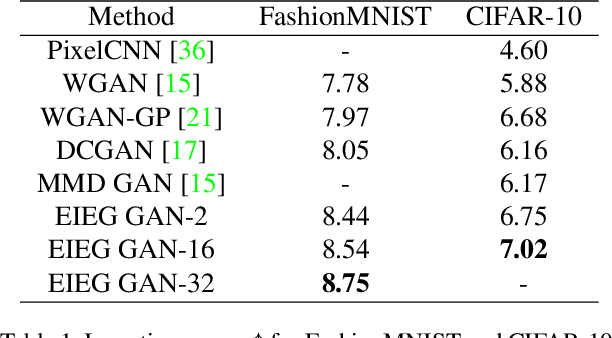
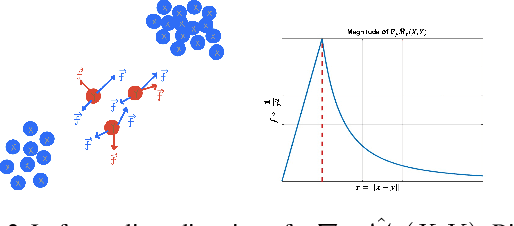

In this paper, we propose a novel approach to generative modeling using a loss function based on elastic interaction energy (EIE), which is inspired by the elastic interaction between defects in crystals. The utilization of the EIE-based metric presents several advantages, including its long range property that enables consideration of global information in the distribution. Moreover, its inclusion of a self-interaction term helps to prevent mode collapse and captures all modes of distribution. To overcome the difficulty of the relatively scattered distribution of high-dimensional data, we first map the data into a latent feature space and approximate the feature distribution instead of the data distribution. We adopt the GAN framework and replace the discriminator with a feature transformation network to map the data into a latent space. We also add a stabilizing term to the loss of the feature transformation network, which effectively addresses the issue of unstable training in GAN-based algorithms. Experimental results on popular datasets, such as MNIST, FashionMNIST, CIFAR-10, and CelebA, demonstrate that our EIEG GAN model can mitigate mode collapse, enhance stability, and improve model performance.