 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Utility-driven Interval Rules
Sep 28, 2023



For artificial intelligence, high-utility sequential rule mining (HUSRM) is a knowledge discovery method that can reveal the associations between events in the sequences. Recently, abundant methods have been proposed to discover high-utility sequence rules. However, the existing methods are all related to point-based sequences. Interval events that persist for some time are common. Traditional interval-event sequence knowledge discovery tasks mainly focus on pattern discovery, but patterns cannot reveal the correlation between interval events well. Moreover, the existing HUSRM algorithms cannot be directly applied to interval-event sequences since the relation in interval-event sequences is much more intricate than those in point-based sequences. In this work, we propose a utility-driven interval rule mining (UIRMiner) algorithm that can extract all utility-driven interval rules (UIRs) from the interval-event sequence database to solve the problem. In UIRMiner, we first introduce a numeric encoding relation representation, which can save much time on relation computation and storage on relation representation. Furthermore, to shrink the search space, we also propose a complement pruning strategy, which incorporates the utility upper bound with the relation. Finally, plentiful experiments implemented on both real-world and synthetic datasets verify that UIRMiner is an effective and efficient algorithm.
HUSP-SP: Faster Utility Mining on Sequence Data
Dec 29, 2022



High-utility sequential pattern mining (HUSPM) has emerged as an important topic due to its wide application and considerable popularity. However, due to the combinatorial explosion of the search space when the HUSPM problem encounters a low utility threshold or large-scale data, it may be time-consuming and memory-costly to address the HUSPM problem. Several algorithms have been proposed for addressing this problem, but they still cost a lot in terms of running time and memory usage. In this paper, to further solve this problem efficiently, we design a compact structure called sequence projection (seqPro) and propose an efficient algorithm, namely discovering high-utility sequential patterns with the seqPro structure (HUSP-SP). HUSP-SP utilizes the compact seq-array to store the necessary information in a sequence database. The seqPro structure is designed to efficiently calculate candidate patterns' utilities and upper bound values. Furthermore, a new upper bound on utility, namely tighter reduced sequence utility (TRSU) and two pruning strategies in search space, are utilized to improve the mining performance of HUSP-SP. Experimental results on both synthetic and real-life datasets show that HUSP-SP can significantly outperform the state-of-the-art algorithms in terms of running time, memory usage, search space pruning efficiency, and scalability.
Totally-ordered Sequential Rules for Utility Maximization
Sep 27, 2022
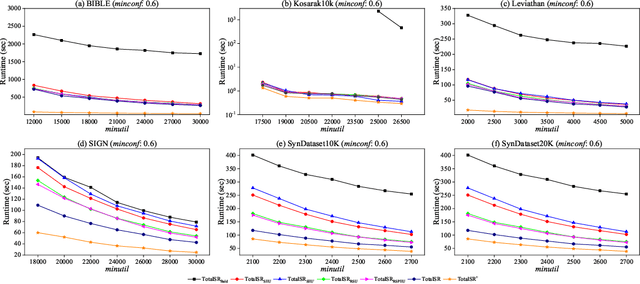

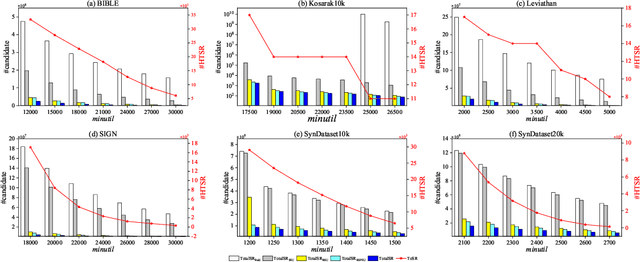
High utility sequential pattern mining (HUSPM) is a significant and valuable activity in knowledge discovery and data analytics with many real-world applications. In some cases, HUSPM can not provide an excellent measure to predict what will happen. High utility sequential rule mining (HUSRM) discovers high utility and high confidence sequential rules, allowing it to solve the problem in HUSPM. All existing HUSRM algorithms aim to find high-utility partially-ordered sequential rules (HUSRs), which are not consistent with reality and may generate fake HUSRs. Therefore, in this paper, we formulate the problem of high utility totally-ordered sequential rule mining and propose two novel algorithms, called TotalSR and TotalSR+, which aim to identify all high utility totally-ordered sequential rules (HTSRs). TotalSR creates a utility table that can efficiently calculate antecedent support and a utility prefix sum list that can compute the remaining utility in O(1) time for a sequence. We also introduce a left-first expansion strategy that can utilize the anti-monotonic property to use a confidence pruning strategy. TotalSR can also drastically reduce the search space with the help of utility upper bounds pruning strategies, avoiding much more meaningless computation. In addition, TotalSR+ uses an auxiliary antecedent record table to more efficiently discover HTSRs. Finally, there are numerous experimental results on both real and synthetic datasets demonstrating that TotalSR is significantly more efficient than algorithms with fewer pruning strategies, and TotalSR+ is significantly more efficient than TotalSR in terms of running time and scalability.
Reconstruct Anomaly to Normal: Adversarial Learned and Latent Vector-constrained Autoencoder for Time-series Anomaly Detection
Oct 14, 2020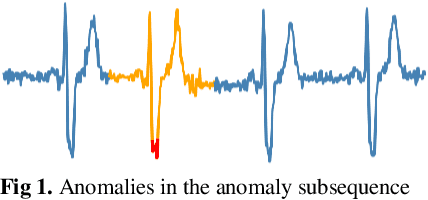
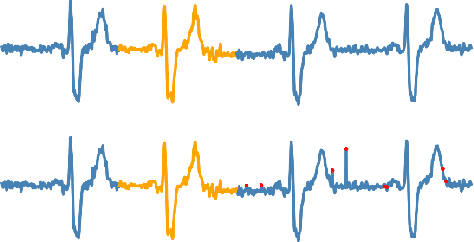
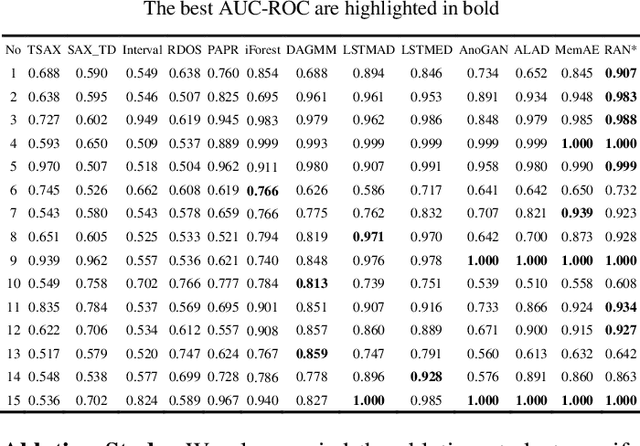
Anomaly detection in time series has been widely researched and has important practical applications. In recent years, anomaly detection algorithms are mostly based on deep-learning generative models and use the reconstruction error to detect anomalies. They try to capture the distribution of normal data by reconstructing normal data in the training phase, then calculate the reconstruction error of test data to do anomaly detection. However, most of them only use the normal data in the training phase and can not ensure the reconstruction process of anomaly data. So, anomaly data can also be well reconstructed sometimes and gets low reconstruction error, which leads to the omission of anomalies. What's more, the neighbor information of data points in time series data has not been fully utilized in these algorithms. In this paper, we propose RAN based on the idea of Reconstruct Anomalies to Normal and apply it for unsupervised time series anomaly detection. To minimize the reconstruction error of normal data and maximize this of anomaly data, we do not just ensure normal data to reconstruct well, but also try to make the reconstruction of anomaly data consistent with the distribution of normal data, then anomalies will get higher reconstruction errors. We implement this idea by introducing the "imitated anomaly data" and combining a specially designed latent vector-constrained Autoencoder with the discriminator to construct an adversary network. Extensive experiments on time-series datasets from different scenes such as ECG diagnosis also show that RAN can detect meaningful anomalies, and it outperforms other algorithms in terms of AUC-ROC.
Time Series Anomaly Detection with Variational Autoencoders
Jul 03, 2019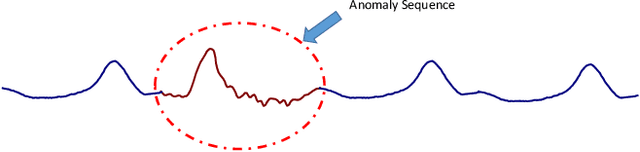
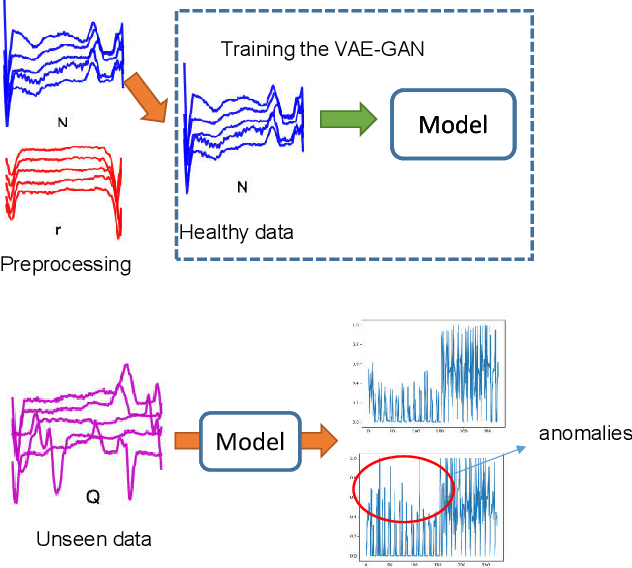
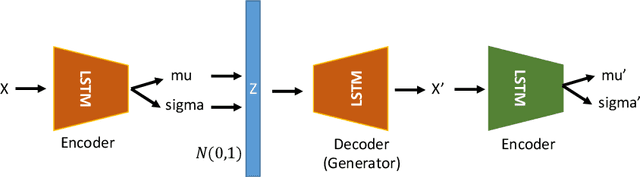
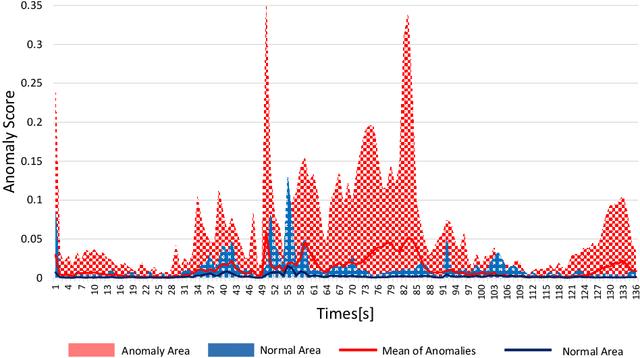
Anomaly detection is a very worthwhile question. However, the anomaly is not a simple two-category in reality, so it is difficult to give accurate results through the comparison of similarities. There are already some deep learning models based on GAN for anomaly detection that demonstrate validity and accuracy on time series data sets. In this paper, we propose an unsupervised model-based anomaly detection named LVEAD, which assumpts that the anomalies are objects that do not fit perfectly with the model. For better handling the time series, we use the LSTM model as the encoder and decoder part of the VAE model. Considering to better distinguish the normal and anomaly data, we train a re-encoder model to the latent space to generate new data. Experimental results of several benchmarks show that our method outperforms state-of-the-art anomaly detection techniques.
Anomaly Subsequence Detection with Dynamic Local Density for Time Series
Jun 28, 2019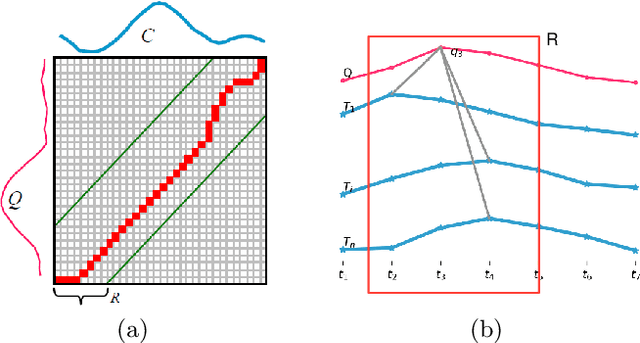
Anomaly subsequence detection is to detect inconsistent data, which always contains important information, among time series. Due to the high dimensionality of the time series, traditional anomaly detection often requires a large time overhead; furthermore, even if the dimensionality reduction techniques can improve the efficiency, they will lose some information and suffer from time drift and parameter tuning. In this paper, we propose a new anomaly subsequence detection with Dynamic Local Density Estimation (DLDE) to improve the detection effect without losing the trend information by dynamically dividing the time series using Time Split Tree. In order to avoid the impact of the hash function and the randomness of dynamic time segments, ensemble learning is used. Experimental results on different types of data sets verify that the proposed model outperforms the state-of-art methods, and the accuracy has big improvement.
An Improvement of PAA on Trend-Based Approximation for Time Series
Jun 28, 2019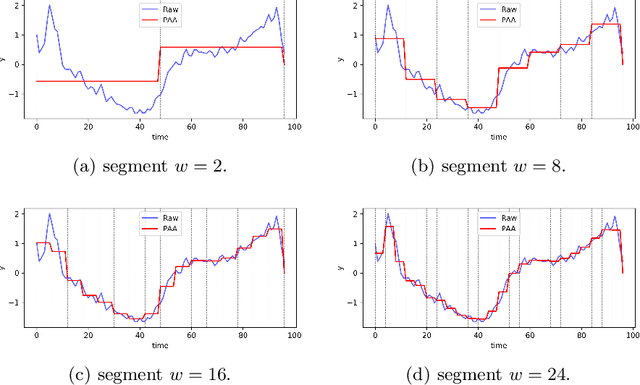
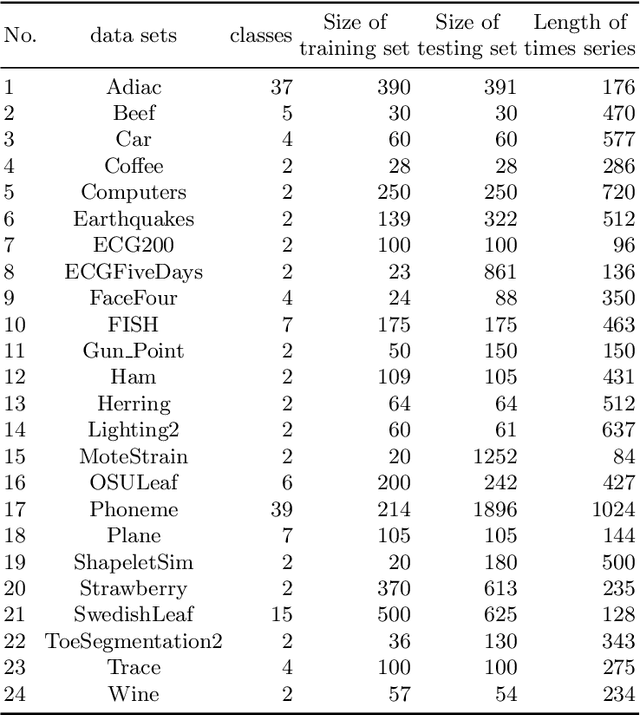
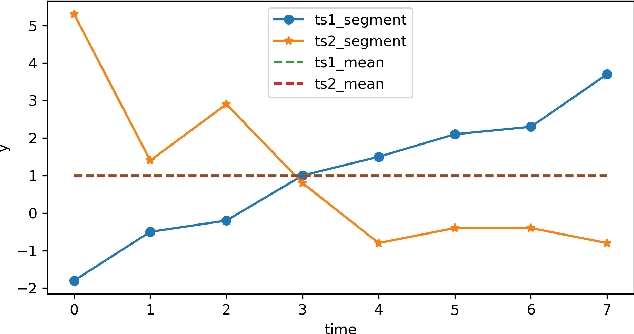
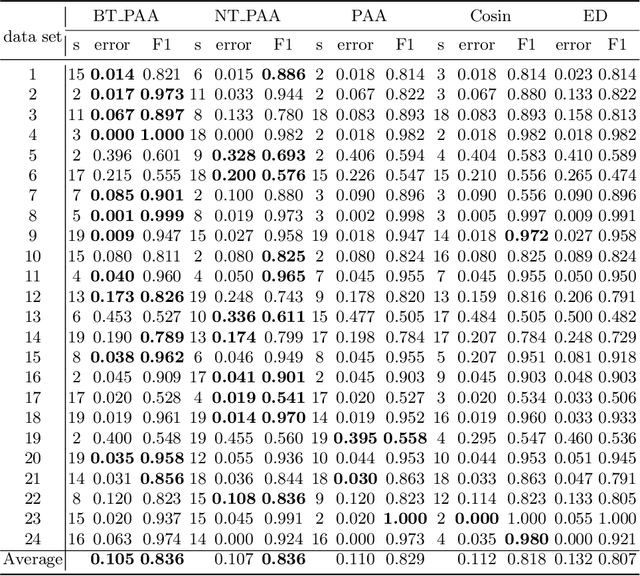
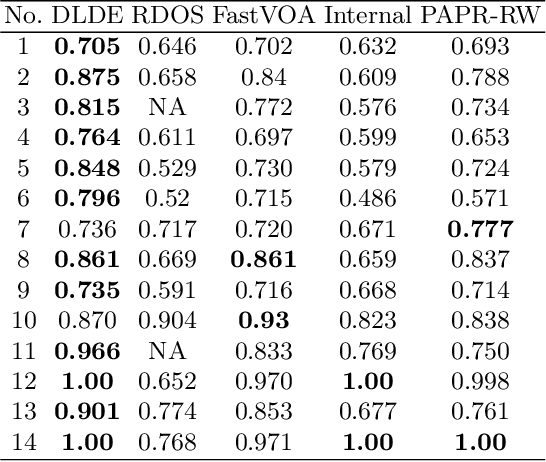
Piecewise Aggregate Approximation (PAA) is a competitive basic dimension reduction method for high-dimensional time series mining. When deployed, however, the limitations are obvious that some important information will be missed, especially the trend. In this paper, we propose two new approaches for time series that utilize approximate trend feature information. Our first method is based on relative mean value of each segment to record the trend, which divide each segment into two parts and use the numerical average respectively to represent the trend. We proved that this method satisfies lower bound which guarantee no false dismissals. Our second method uses a binary string to record the trend which is also relative to mean in each segment. Our methods are applied on similarity measurement in classification and anomaly detection, the experimental results show the improvement of accuracy and effectiveness by extracting the trend feature suitably.