 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Minimization of Expected Logarithmic Loss via Stochastic Dual Averaging
Nov 05, 2023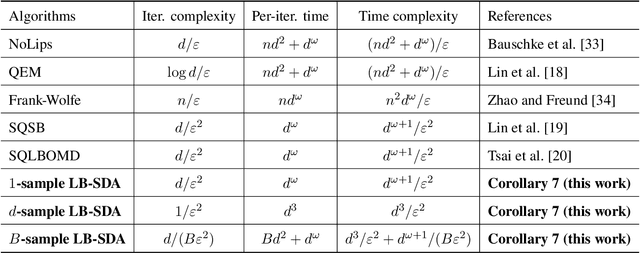
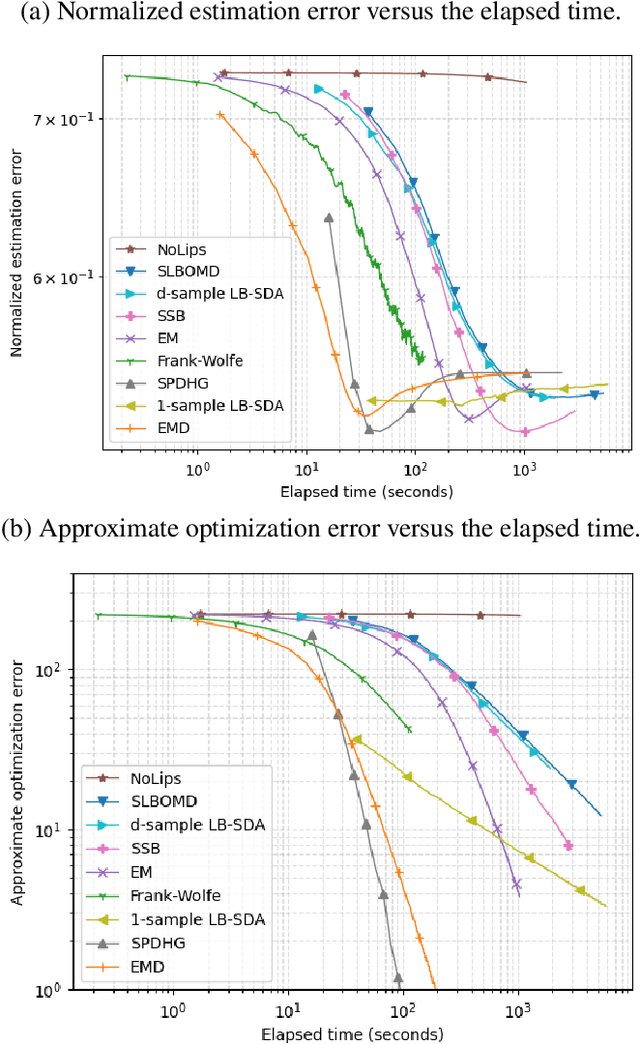
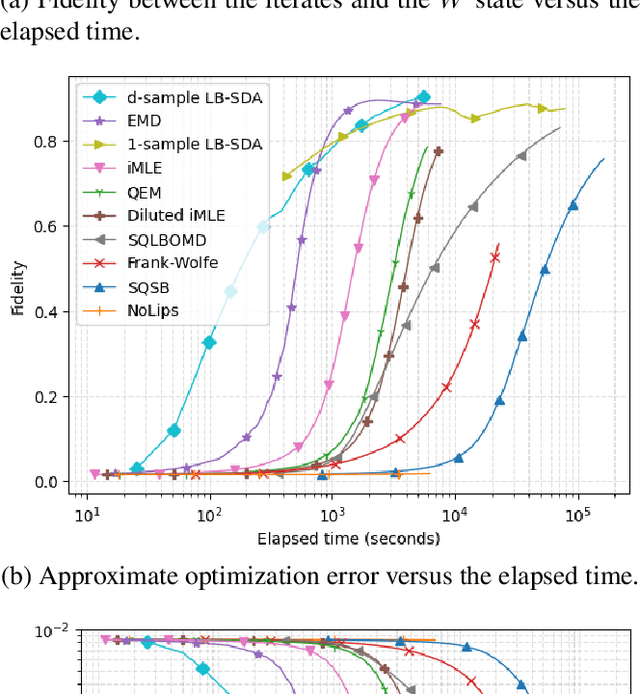
Consider the problem of minimizing an expected logarithmic loss over either the probability simplex or the set of quantum density matrices. This problem encompasses tasks such as solving the Poisson inverse problem, computing the maximum-likelihood estimate for quantum state tomography, and approximating positive semi-definite matrix permanents with the currently tightest approximation ratio. Although the optimization problem is convex, standard iteration complexity guarantees for first-order methods do not directly apply due to the absence of Lipschitz continuity and smoothness in the loss function. In this work, we propose a stochastic first-order algorithm named $B$-sample stochastic dual averaging with the logarithmic barrier. For the Poisson inverse problem, our algorithm attains an $\varepsilon$-optimal solution in $\tilde{O} (d^2/\varepsilon^2)$ time, matching the state of the art. When computing the maximum-likelihood estimate for quantum state tomography, our algorithm yields an $\varepsilon$-optimal solution in $\tilde{O} (d^3/\varepsilon^2)$ time, where $d$ denotes the dimension. This improves on the time complexities of existing stochastic first-order methods by a factor of $d^{\omega-2}$ and those of batch methods by a factor of $d^2$, where $\omega$ denotes the matrix multiplication exponent. Numerical experiments demonstrate that empirically, our algorithm outperforms existing methods with explicit complexity guarantees.
Data-Dependent Bounds for Online Portfolio Selection Without Lipschitzness and Smoothness
May 23, 2023This work introduces the first small-loss and gradual-variation regret bounds for online portfolio selection, marking the first instances of data-dependent bounds for online convex optimization with non-Lipschitz, non-smooth losses. The algorithms we propose exhibit sublinear regret rates in the worst cases and achieve logarithmic regrets when the data is "easy," with per-iteration time almost linear in the number of investment alternatives. The regret bounds are derived using novel smoothness characterizations of the logarithmic loss, a local norm-based analysis of following the regularized leader (FTRL) with self-concordant regularizers, which are not necessarily barriers, and an implicit variant of optimistic FTRL with the log-barrier.
Faster Stochastic First-Order Method for Maximum-Likelihood Quantum State Tomography
Nov 23, 2022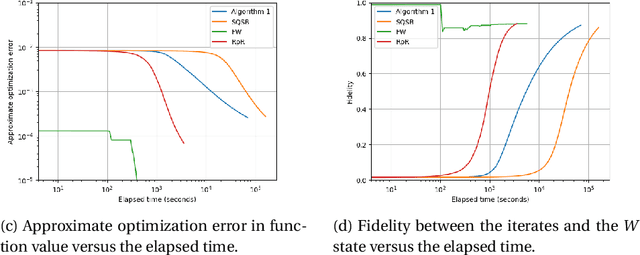
In maximum-likelihood quantum state tomography, both the sample size and dimension grow exponentially with the number of qubits. It is therefore desirable to develop a stochastic first-order method, just like stochastic gradient descent for modern machine learning, to compute the maximum-likelihood estimate. To this end, we propose an algorithm called stochastic mirror descent with the Burg entropy. Its expected optimization error vanishes at a $O ( \sqrt{ ( 1 / t ) d \log t } )$ rate, where $d$ and $t$ denote the dimension and number of iterations, respectively. Its per-iteration time complexity is $O ( d^3 )$, independent of the sample size. To the best of our knowledge, this is currently the computationally fastest stochastic first-order method for maximum-likelihood quantum state tomography.
Online Self-Concordant and Relatively Smooth Minimization, With Applications to Online Portfolio Selection and Learning Quantum States
Oct 03, 2022
Consider an online convex optimization problem where the loss functions are self-concordant barriers, smooth relative to a convex function $h$, and possibly non-Lipschitz. We analyze the regret of online mirror descent with $h$. Then, based on the result, we prove the following in a unified manner. Denote by $T$ the time horizon and $d$ the parameter dimension. 1. For online portfolio selection, the regret of $\widetilde{\text{EG}}$, a variant of exponentiated gradient due to Helmbold et al., is $\tilde{O} ( T^{2/3} d^{1/3} )$ when $T > 4 d / \log d$. This improves on the original $\tilde{O} ( T^{3/4} d^{1/2} )$ regret bound for $\widetilde{\text{EG}}$. 2. For online portfolio selection, the regret of online mirror descent with the logarithmic barrier is $\tilde{O}(\sqrt{T d})$. The regret bound is the same as that of Soft-Bayes due to Orseau et al. up to logarithmic terms. 3. For online learning quantum states with the logarithmic loss, the regret of online mirror descent with the log-determinant function is also $\tilde{O} ( \sqrt{T d} )$. Its per-iteration time is shorter than all existing algorithms we know.